Canal
Reassessing and systematizing affixal meaning definition in OE dictionaries (...)
Raquel Vea Escarza (Universidad de La Rioja)
Raquel Vea Escarza (Universidad de La Rioja)

Luisa Fidalgo Allo (Universidad de La Rioja)

Natalia Zawadzka-Paluektau and Aleksandra Tomaszewska (University of Warsaw and University of Sevilla)

Eva Lucía Jiménez-Navarro (Universidad de Córdoba)

Anna Beatriz Dimas Furtado and Elisa Duarte Teixeira (Universidad de Brasilia)
Carmen Varó Varó (Universidad de Cádiz)

Raquel Mateo (Universidad de La Rioja)
Jens Fleischhauer and Stefan Hartmann (Heinrich Heine University Düsseldorf)
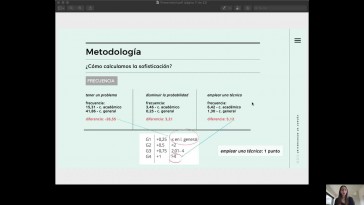
Eleonora Guzzi and Margarita Alonso Ramos (Universidade da Coruña)
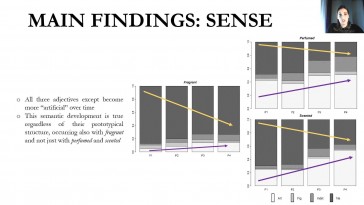
Daniela Pettersson-Traba (Universidad de Extremadura)

Sabrina Lafuente Giménez and Vanessa Gonzaga Nunes (Universidade Federal de Sergipe)
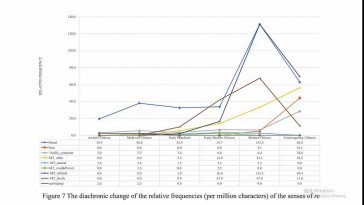
Meili Liu (Katholieke Universiteit Leuven)
Para enlazar este video en cualquier página, puede usar esta URL:

Aula Virtual puede incluir de forma automática Videos de TV.UM.ES en el mini-editor HTML (FCKeditor) de cualquier herramienta (Tareas, Exámenes, Anuncios, Recursos, ...).
Para incrustar el vídeo en el mini-editor HTML del Aula Virtual, debe pulsar sobre
el botón "Copiar para pegar" y en el mini-editor HTML del Aula Virtual pulsar en el
botón ![]() o pulsar la combinación de teclas Ctrl+V.
o pulsar la combinación de teclas Ctrl+V.
El video aparecerá directamente como una imagen de resolución , y al hacer click sobre ella, se reproducirá.
Para enlazar con tamaño fijo (click para copiar):
Para enlazar con tamaño dinámico (click para copiar):
Para más información sobre cómo enlazar videos o usar la API, consulte esta página.
En breve.
En breve.