
Canal
Typical Phraseological Units in Poetic Texts
Michael Pace-Sigge (University of Eastern Finland)
Michael Pace-Sigge (University of Eastern Finland)

Ekaterina Troshchenkova, Olga Blinova (Saint Petersburg State University -SPBU-)
Safa Atia (Universidad Autónoma de Madrid)
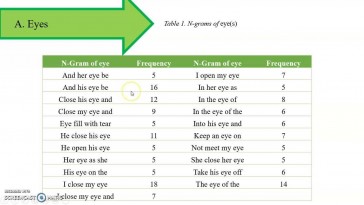
Cassandra Sian Tully (Universidad de Extremadura)
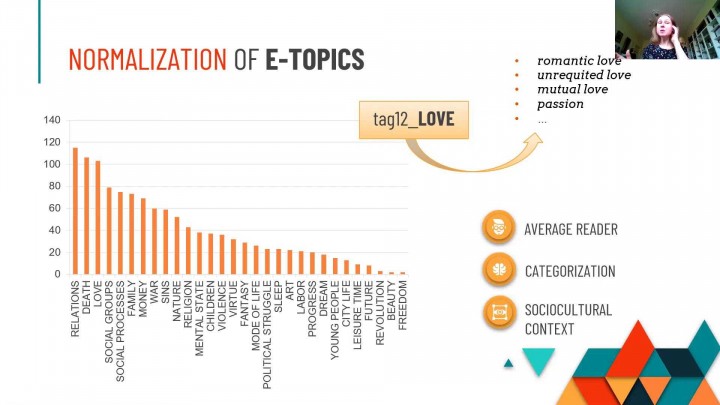
Zihuan Zhong (Queen Mary University of London)
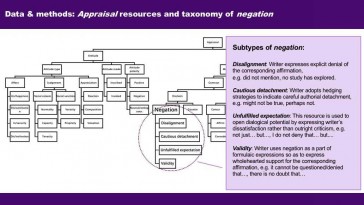
Shuyi Sun and Peter Crosthwaite (University of Queensland)
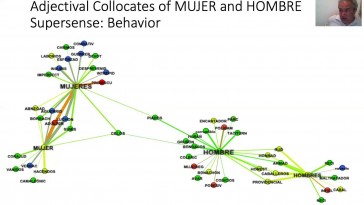
Héctor Castro and Ignacio Ródriguez (Universidad Autónoma de Querétaro)
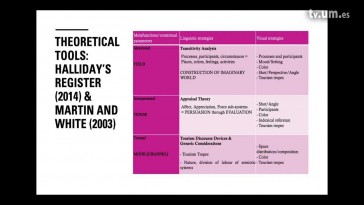

Jiang Niu and Yue Jiang (Xi'an Jiaotong University)

Isabel García Martínez (Universitat de Valencia)

Mengna Liu (Guangdong University of Foreign Studies)
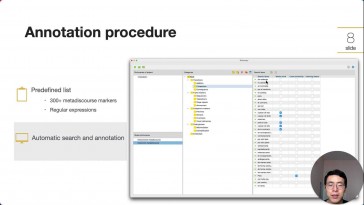
Gang Yao (Universidad de Murcia) y María Luisa Carrió Pastor (Universidad Politécnica de Valencia)

Ana Maria Terrazas-Calero (University of Limerick)

Ana Ruth Sánchez Barrera and Ignacio Rodríguez Sánchez (Universidad Autónoma de Querétaro)

Fang Wang (University of Surrey)
Cao Wei, Yuanyuan Zhao and Zhao Yuanyuan (Universidad de Huelva)
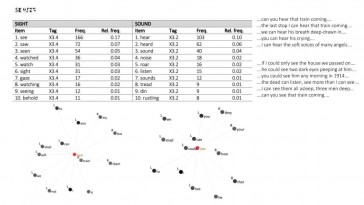
Hakan Cangır (Ankara University) and Taner Can (TED University)

Álvaro Ramos (Universidad de Granada)
Para enlazar este video en cualquier página, puede usar esta URL:

Aula Virtual puede incluir de forma automática Videos de TV.UM.ES en el mini-editor HTML (FCKeditor) de cualquier herramienta (Tareas, Exámenes, Anuncios, Recursos, ...).
Para incrustar el vídeo en el mini-editor HTML del Aula Virtual, debe pulsar sobre
el botón "Copiar para pegar" y en el mini-editor HTML del Aula Virtual pulsar en el
botón ![]() o pulsar la combinación de teclas Ctrl+V.
o pulsar la combinación de teclas Ctrl+V.
El video aparecerá directamente como una imagen de resolución , y al hacer click sobre ella, se reproducirá.
Para enlazar con tamaño fijo (click para copiar):
Para enlazar con tamaño dinámico (click para copiar):
Para más información sobre cómo enlazar videos o usar la API, consulte esta página.
En breve.
En breve.