
Canal
Orden en el caos: estrategias para el reconocimiento automático de las variantes gráficas (...)
Eva María Domínguez Noya (Universidad de Santiago de Compostela)

Eva María Domínguez Noya (Universidad de Santiago de Compostela)
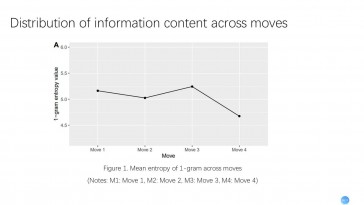
Li Li and Wei Xiao (Chongqing University)

Jin Liu and Wei Xiao (Chongqing University)

Eva María Domínguez Noya y Vítor Míguez Rego (Universidad de Santiago de Compostela)


Javier Fernández Cruz (Universidad de Málaga)

Nancy E. Avila-Ledesma (Universidad de Extremadura)

Antonio Moreno-Ortiz, María García-Gámez y Chantal Pérez-Hernández (Universidad de Málaga)

Chelo Vargas Sierra (Universidad de Alicante) y Antonio Moreno Sandoval (Universidad Autónoma de Madrid)

John Blake (University of Aizu)
Para enlazar este video en cualquier página, puede usar esta URL:

Aula Virtual puede incluir de forma automática Videos de TV.UM.ES en el mini-editor HTML (FCKeditor) de cualquier herramienta (Tareas, Exámenes, Anuncios, Recursos, ...).
Para incrustar el vídeo en el mini-editor HTML del Aula Virtual, debe pulsar sobre
el botón "Copiar para pegar" y en el mini-editor HTML del Aula Virtual pulsar en el
botón ![]() o pulsar la combinación de teclas Ctrl+V.
o pulsar la combinación de teclas Ctrl+V.
El video aparecerá directamente como una imagen de resolución , y al hacer click sobre ella, se reproducirá.
Para enlazar con tamaño fijo (click para copiar):
Para enlazar con tamaño dinámico (click para copiar):
Para más información sobre cómo enlazar videos o usar la API, consulte esta página.
En breve.
En breve.