Bueno, pues vamos a tener que ir con
la formación siguiente tema
que quería que quería tratar, un
tema de la entrada de datos y sistema
para las siguientes partes.
Van poco a poco, desde el proceso
de entrada de datos
y transformando para posteriormente
en el tiempo histórico,
pues en esta primera lista primera
parte vamos aprendiendo,
pues la entrada de datos.
Lo primero que tenemos que
tener en cuenta es
que va a haber distintos
orígenes de Fuentes,
pero Jennings van a ser, por un lado,
es lo que decía datos de
diferentes lugares
de diferentes proveedores
de información,
los cuales van a ponernos la
información de diferentes maneras
con distintos protocolos en
Manresa es un etc etc
etc no poder los cuales se
vamos a tener que tratar
de las fuentes de datos décimas
más conocidas,
que vamos a tener, pues podría
ser de ese cebs
del sheriff etc
etc entonces por por resumir digamos
que vamos a tener diferentes orígenes
de datos, con con datos distintos,
con los datos en distinto formato,
pero además, con distintos
protocolos ,
lo cual vamos a tener que poder
darles soportes de la aplicación.
En primer lugar, bueno,
pues volviendo a ver
lo que es el la parte de la
arquitectura de la del módulo
de importación, que ya lo vimos
un poco antes del descanso.
Vamos a estar formado
por por por varias,
por varios elementos,
no en primer lugar
el que va a tener que lidiar
con las colas,
fuentes de datos o los
orígenes de datos
que van a ser los importadores.
La idea es tener uno por cada
una de las fuentes externas
las que se toma la información.
Como decía, cada una
de estas fuentes,
disponer de los datos en un
formato de diferente
y además en una estructura diferente
a la que se vaya luego
a trabajar en el sistema bale.
Entonces, estos.
Micro servicios no van a estar
implementados en el sistema
y habrá algunos como los
importadores que van a estar más acoplado
esa al cliente y luego va otros
que no lo van a estar tanto,
por lo que será conveniente que cada
uno de los componentes reales
de las operaciones de la forma
más más atómica y acoplada
posible el caso de los importadores,
como comentaba Miguel servicios, 1,
por cada fuente de datos que se van
a encargar de leer los datos
de estas fuentes, el sistema a
través de un topic de Kafka
-Bale, su única misión será la de
leer los datos de esa década.
Una de las fuentes no va a realizar
transformación ninguna,
sino que lo único
que lo único que va a hacer es saber
cómo, cómo interactuar,
cómo leer de esa fuente de datos
y recoger el dato simplemente
si es un XML lo cogerá el XML,
lo procesara ese dato en XML
generará un evento en
la cola de Kafka
para que luego ya sea una
un formato más conocido
por el sistema.
Para los siguientes servicios
tenemos que hacer esa labor de adaptación
poco lo que decía.
Por ejemplo, caso de que una fuente
sea un importador correspondiente
pues se encargaría de recuperar
los ficheros vía fptp.
Pongamos que esos ficheros son XML,
pues tendría que extraerlo
con de XML y generar,
lo que lo que comentaba,
que serían esos, esos,
esos eventos dentro de la cola de
interna del módulo de entrada.
Una vez una vez ya tenemos los
datos en el sistema, vale,
que pasaría esa fase de los
de los importadores
de cada una de las de las fuentes.
Ya ya tenemos todos esos
datos adaptados
dentro de nuestro modelo de entrada
dentro de nuestro sistema.
Pero llevamos, ha bastado
simplemente en el formato vale?
No, no en el dato,
no en la estructura de
la información,
que eso vamos a tener que
transformarlas posteriormente.
Entonces, una vez ha pasado
por los importadores
que lo que los ha estado
en la cola de Kafka
vale.
La tarea del procesamiento de
del procesador de datos
Suárez es la tarea que
va, que va a tener,
es encargarse de transformar los
datos de la entrada en datos
que se precisa para la antología.
No la va a hacer,
no sabe o no la va a hacer
el por por sí mismo,
sino que esa transformación la va
a llevar a cabo más adelante
o una de un proceso que va a estar
implementado con María Pérez?
Se queda la parte de del procesador
en la que se va
a encargar de consumir esa
información está consumiendo
lo que es el tope de datos en una
base de datos intermedia,
que es la base de datos con
la que trabajarla,
se podría conectar directamente al
Kafka por ponerse, podría valer,
pero el problema que
vamos a tener aquí
es que un uno cada uno de los
elementos por sí solo
no es completo, digamos, no, sino
que voy al para poder componer
los.
La estructura de datos final
que se vaya a almacenar
sea la estructura que define
la antología realmente,
no puede almacenar en la tripleta.
Los recursos que veamos antes.
Digamos que voy a tener
que coger datos
de diferentes de diferentes sitios,
por decirlo de alguna manera.
Puedes tener que estar picando de
L Aquila y ya entonces digamos
que si me viene un dato por
una cola de solamente
voy a poder procesar ese
ese dato realmente.
Entonces, por eso, vamos a necesitar
tener una base de datos intermedia,
la que pueda hacer las consultas,
la tele posteriormente, hecho
hasta que el procesador
no termina de insertar los datos
en esta base de internet,
ya no va a poder comenzar
el proceso de la de.
Por este motivo.
Vale, bueno, pues nada la en cuanto
al proceso de de tele,
pues eso se va, va a hacer,
es esa transformación y como
resultado de esa,
esa transformación en este caso
va a escribir en una cola
de para volver a realizar el
procesamiento en streaming;
las siguientes en las
siguientes fases
del del sistema para para
que no dependa
de la velocidad de de procesamiento.
El que yo pueda seguir datos, para
decirlo de alguna manera
desacoplados un poco la
producción de gas
con el consumo de los mismos.
Bueno, un poco un poco lo que diga.
Lo que hablamos no realmente
no merece la pena
ser mucho más de lo que ya hemos
comentado cuando hay esto
sería la parte del procesamiento
de procesamiento.
Bueno, como decía aquí lo dejamos
obstante, indicado.
No tendremos los datos en
formato de entrada
a través de este procesamiento.
Se va a definir los datos
en más buenos datos.
Una salida en datos es que
muchas veces hablamos
de los ojos.
Vale?
Realmente esto es pocos,
van, van a ser clases,
objetos que van a estar definidos,
van a generar a partir
de la antología.
Es decir, si la antología de cine
que haber un objeto de tipo artista,
por como veamos Andersen, el ejemplo,
otro equipo investigador
ya llevándole
un poco más al mundo universitario,
digamos que va a haber un proceso
que se va a encargar
de que a partir de esa antología
de ese modelo
que se ha definido ese o un vale a
través de algo que se llama así
expresión estoy seguro que
mañana lo van a explicar
en la formación que tenéis la
infraestructura antológica,
se va a poder generar una
clase, es decir,
yo y tengo la antología de
filme mi investigador,
que tiene un hombre que tiene
apellidos, etc, etc, vale,
pues realmente eso va a desembocar
en que se va a generar una clase
la Public clase investigador, que
tiene un private nombre,
primates, tienen apellidos
y así sucesivamente,
no, eso es lo que denominamos
cojo Bale.
Entonces tenemos que tenemos que
poder rellenar esas esas clases,
eso es de esos datos a partir
de los datos de la entrada
y eso es lo que hace.
El proceso de para ello vamos
a utilizar ventajosas.
Nos va a ayudar en ese cometido
ventaja que lo que nos va
a permitir, por un lado,
es leer datos de diferentes fuentes.
El fondo es de entrada y realizar
transformaciones
sobre los mismos cálculos mapping
filtrado pivotado de información etc
Etc. Un poco el resumen de lo
que de lo que vamos a hacer
en ese proceso de transformación
para cada una de las entidades
responde a esta estructura,
para cada transformación
que se centra en una entidad
en particular,
y se siguen estos estos pasos no
abran entidades por un lado
se llama general las entidades sin
relación que no tenga relaciones
con otras con otras entidades se van
a leer los distintos orígenes
implicados en la transformación,
la entidad principal
y todos aquellos que contengan datos
relacionados con la entidad principal
y que consiste en propiedades
de la misma
para poder rellenarla una vez
obtenidos esta información,
se van a eliminar, hacer un
proceso de limpieza,
eliminando los caracteres extraños
o seleccionando.
los datos que sean necesarios
añade en otro tipo de datos
de tipo constantes,
y si procede ordenación.
Es bueno un poco lo que lo
que comentaba antes,
aplicando diferentes fórmulas.
Una vez los datos se encuentren
unificado.
Después se realizaría un último
último filtrado para terminar
con ese proceso de limpieza.
Sería una carga en la base
de datos de esto
es un poco lo que comentaba
antes de desventaja.
No diré directamente que es el que
va a hacer esa esa transformación,
y esa ese proceso de limpieza,
lo que sería el procesador
de eventos,
viéndonos ya justamente, a ventaja.
Quería descomponer el cuerpo
y la estructura del formato de
salida aplicando una serie de fórmulas
y teniendo un poco en
cuenta los datos,
el patrón descrito antes y por
último, las que se cargaría
y se cargaría en la cola en la cola,
Kafka correspondiente a los
objetos sin relaciones.
Luego, en cuanto a los sujetos
con relación,
pues se cargan las correspondientes
desde la base de datos
donde se almacena la entidad
y sus sus propiedades,
y y luego se carga la relación es
cuando cuando estábamos hablando
de objetos con relación
a se relación.
Realmente, lo que quiero decir
es que, por un lado se va a generar
las, la los Los Tojos.
Vale, sin sin tener en cuenta
que puedan tener relaciones
con otros elementos, vale?
Por ejemplo, un investigador
puedes decir que trabaja
en determinado departamento,
y ese departamento
es una relación ahí que vas a que
vas a tener un determinaba universidad.
Entonces, lo que vamos a hacer,
digamos, es, por un lado,
generar esos objetos
sin las relaciones
todavía en una primera pasada vale,
y es por eso por lo que decimos
que en primer lugar,
se va a enviar esas entidades
sin relación?
Vale, porque no es no se va
a enviar las las relaciones entre
ellas y lo va a haber
otra segunda pasada en la que se van
a enviar esas esos enlaces,
esos esas relaciones entre entre
todas las entidades
vale?
Porque porque lo hacemos
así Bale lo hace así
un poco para para gestionar el hecho
de que si en un primer momento
enviamos ya toda la información que
podríamos podíamos hacerlo
perfectamente enviar su entidad
con sus, con sus relaciones,
podría darse el caso de que
se envíe una relación
a un objeto, que no existe,
algo que no existe.
Entonces, de de cierta manera
tendríamos un problema,
no hay al poder insertar eso en
el triple story general.
El centro es para asegurarnos de
que todos los objetos existan.
Lo primero que vamos a hacer es
insertar todos sin relaciones
y, por último, vamos a
hacer otro segunda.
Pasaba enviando las relaciones
entre los diferentes objetos
para para ya en ese momento,
si somos conscientes
o tenemos la constancia de que de
que existen en, por ejemplo,
pues enviado todos los
investigadores enviado todas las universidades,
tengo una relación entre ambos,
pues ya puedo hacerla
de forma de forma bastante,
bastante sencilla.
Habría otras alternativas,
como, por ejemplo, crear
objetos vacíos
o ejemplo.
Si tengo una relación con
una universidad equis
y no existe esa universidad, es
crear la de cierta manera,
lo que pasa es que después podría
tener problemas de rendimiento
y también problemas a
la hora de poder
identificar esa universidad,
como cuando me llega el dato
para poder relacionar
que son obesidad de la universidad,
que me está llegando en
un momento dado,
no?
Entonces,
para un poco eliminar esos problemas
de que estoy contando,
decidimos hacerlo de esta,
de esta de esta manera,
y funcionando bastante de forma
bastante adecuada.
Bueno, de la parte de importación
sería sería un poco hasta hasta aquí
no sé si si queréis comentar
alguna duda.
Además, si no, pasamos a la parte
del sistema de gestión,
no menos.
Bueno, entonces nos vamos
a la modelo de gestión
haciendo un resumen de lo que
tenemos hasta ahora.
Digamos que teníamos los datos
en el sistema que proveían
de diferentes fuentes,
y ya lo sabemos, ya los
hemos obtenido,
y los hemos adaptado al formato.
Qué va a esperar
o que no se está definiendo la
odontología entonces, por tanto,
el sistema de gestión va a ser
el encargado de recoger
los datos en formato cojo, vale
del de la cola de entrada,
así como sus grabaciones,
valer esos enlaces
que comentaba antes de de otra cola
para los que les vamos a enviar
como ella es lo que se hará va
a ser utilizar la librería
de descubrimiento, para validar si
se trata de un nuevo recurso
o, por el contrario, es
una ya existente
que hay que actualizar
o bien, es necesario realizar
algún tipo de borrado
o similar general.
El rdc también apoyándose
en la factoría de Uriz
y la ingesta del del rdc, en otra,
en otra cola del modelo de gestión,
que va a permitir luego ya los
procesadores de eventos
y almacenar en los almacenamientos
que sea pertinente no
tengamos necesidad
de almacenarla.
La información.
En cuanto a éste está con la cola
que estamos comentando.
El sistema de sistema de gestión lo
va a utilizar para enviar eventos
hacia el proceso de eventos,
en este caso a diferencia
de otros puntos
del sistema que estábamos
utilizando, Kafka;
de hecho, está previsto usar casco
en todos los este tipo de colas,
pero vemos que es preciso
en este caso
garantizar un poco el orden de los
datos que nos están llegando.
Entonces es algo que no nos que
no nos ofrecen al final.
Así es muy muy adecuado para
una ingesta masiva
de información,
pero no garantiza el orden
de la información,
con lo cual no nos no nos
sirve del todo en este.
Este puso entonces.
Entonces en este punto no vamos
a optar por utilizar
una cola al tipo jm.
Es en concreto,
vamos a usar en cuanto a en cuanto a
los procesadores de eventos bueno,
ya lo ya lo comentaba un poco
un poco antes en antes
del descanso; cada uno de
estos procesadores
se va a encargar de consumir
los mensajes disponibles,
en la cola del modelo de gestión
y enviarlos al almacenamiento
correspondiente.
La idea es que exista un
procesador de eventos
por cada uno de los diferentes
almacenamiento triples
Tor wiki base, etc. De esta forma,
como decía, es muy, muy sencillo,
poder añadir.
Tanto.
Almacenamiento es como sea
como sea pertinente
no lo ves ahora mismo hay hay dos
pero podríamos incluso añadir
en caso de que quisiéramos hacer
con consultas de otro tipo,
indexación, etc.
Etc. Sería sería tan simple como
añadir un nuevo procesador
de eventos, con su fachada
correspondiente,
el procesador de eventos no
es que esté especializado
en ningún ningún almacenamiento,
en concreto,
simplemente es una nueva
instancia al tener,
al ser, al ser los servicios,
como hacía, podemos desplegar
varias instancias.
En este caso, creo, además,
que la diferencia es que
tiene configuración,
diferente, vale.
Por un lado, digamos
que el de eventos
para lo que va a hacer es
invocar a la del story.
Sin embargo, el de Vicky va, se
va a invocar a la pide sábado
tres de wiki bases es
la única diferencia
que van a tener esas van
a ser estándar,
van a ser unificadas, van a
tener la misma salida,
ambos esto hará savater.
La idea es que todos los sectores,
Savater tengan la misma y luego
internamente se especializa
en eso sí ya los en cada uno de los
de los almacenamientos disponibles
no.
Entonces también nos facilita por
ahí entonces eso los esto es a la persona
que habla de eso, de transformar
el error de Fez
recibido para que concuerda para
que se adapta el sistema
para el sistema final en el que sea,
en el que sea pertinente.
Durante el transcurso del
proyecto, como decía,
más se van a desarrollar
para traerles
y para Paraguay que no está previsto
desarrollar ninguno, ningún otro.
En este sentido.
Bueno, ya lo comentaba un
poco un poco antes,
estamos haciendo uso del
procesamiento en streaming
para diferentes partes de
toda esta aplicación.
Ya lo vimos también en la parte
de la parte de entrada,
si bien el el punto clave de
procesamiento es en streaming,
estaría dentro de este módulo de
gestión o entre el módulo de entrada
y el modelo de gestión sería
el lado blanco,
la más importante, que vamos a tener,
junto con la de los procesadores
de eventos,
también entonces la idea
es utilizar este,
está esta técnica de timing con
el fin de aumentar la escala,
habilidad y la alta disponibilidad
del sistema,
utilizando flujos de eventos.
Este tipo de sistemas están siendo
utilizados en proyectos
que requieren el procesamiento de
grandes cantidades de datos
y consiste en utilizar un mecanismo
de publicación y suscripción
a un look distribuido.
La lectura, la ventaja es que las
operaciones de escritura
en el ojo más eficientes, que
las actualizaciones en una,
en una, una base de datos,
entre las ventajas,
que luego lo veremos, pero entre
las grandes ventajas
es que totalmente la producción de
la información del consumo,
con lo cual cualquier productor
de información puede
estar gestando datos en el sistema,
pero no tiene por qué estar
esperando a que los procesadores
o quien lo tenga que consumir
termine de procesar.
Cierto dato.
Cada cada uno de estos procesadores,
de estos consumidores, van
a necesitar Copa,
va a utilizar el tiempo que estime
pertinentes sin impactar
en el rendimiento de la ingesta
de la información,
lo cual es una grandísima ventaja
que nos va a aportar este este tipo
de procesamiento, como nos decía.
Bueno, hoy en día Kafka se está
utilizando para parar.
La ingesta de datos de múltiple
es de múltiples fuentes,
pues de temas de idiotez, temas
de transacciones financieras,
con movilidad logística muy muy
pero que muy utilizado
en ese ámbito, cadenas de ensamblaje,
bueno, muchísimos, muchísimos a
ámbitos al final el mundo produce,
produce datos y se está produciendo
en todo momento.
Para poder aprovecharse de ello,
se necesita definitivo
una plataforma que, soporte
esa ingesta masiva
de grandes volúmenes de
datos de información,
y es muy importante herramientas,
como, como Kafka,
que nos permitan gestionarla
este tipo de del sistema.
Pues bueno,
como decía, trabajan con el patrón,
publicación, suscripción normalmente
y permiten de ese acoplar la
publicación de los eventos
de los de los consumidores.
Bueno, realmente bueno,
un poco lo que no estábamos
comentando en esas entonces
estas fuentes de datos,
pues los datos a través
de un productor
que acabara escribiendo los datos
en la la, el tópico,
en la cola de Kafka en
cuanto a la parte
de los consumidores, pues bueno,
pues realmente cada podíamos tener
uno o varios consumidores,
todos aquellos que sea
que sea necesario,
que nos vaya, que nos
vaya a hacer falta.
Todos van a estar mediante una
estrategia de política
y consumiendo de los
de los diferentes.
Diferentes colas vamos,
vamos a estar leyendo
la la información, cada uno
va a ir a su ritmo,
no tienen por qué porque impactar
ninguno en otro puede
ser que uno esté tratando el
primer, el primer elemento
y otro ya esté por el
elemento número 10.
De cada cada uno tiene su suposición
o en la que la del último elemento
leído, con lo cual vamos
a poder tener,
como decía tantos tantos
consumidores como como estime más necesario
y con su con su velocidad.
Aquí es este ejemplo de esto lo veo,
lo veamos diapositivas atrás
en la parte de la gestión de eventos
para el almacenamiento,
la diferentes triples que va a tener
el sistema que estamos hablando.
Bueno, ya lo comentábamos antes.
Productores y consumidores
desacoplados.
Los consumidores lentos no
van a afectar realmente
a los a los productores.
Una de las grandísimas ventajas
de este tipo de sistemas.
Añadir cuantos consumidores
sea necesario
sin afectar a los productores.
Bueno, aunque no afecte
a los productores
y que podría afectar
a la configuración
de la de la cola Kafka pero bueno
ese sería otro otro sistema otro tema
y no habría que añadir seguramente
más participaciones
a una cola.
Las cosas se pueden dividir al final
y las peticiones podrían
estar distribuidas.
Pero bueno, eso es otro tema que
igual no nos hace falta entrar
tan a al fondo de la cuestión.
Lo daba fallos de algún consumidor,
pues lógicamente no va,
no va a afectar al al conjunto
del sistema
o no va a afectar al resto realmente
de consumidores?
.
430
00:28:27,030 --> 00:28:28,970
Bueno, como decía, estas colas,
pues realmente se se denominan
topics valer y un topic,
pues es un tópico topic no deja
de ser una estrella,
una cadena de un flujo de
mensajes relacionados.
No encajamos como veamos.
Después tengo teníamos varios
topics, el topic del modelo
de gestión, el topic de del
modelo de entrada, etc.
Etc. Entonces, digamos que
cada uno de esos topics
sirve para una fundación finalidad.
Por eso por eso hablamos de
mensajes relacionados.
No deja de ser una representación
lógica
estos tópicos,
pues son definidos por los
desarrolladores más
que por los desarrollados,
por la propia aplicación en sí
misma, no, cada aplicación
pues va a necesitar una serie de
de tope y, si bien es cierto
que dependiendo de la configuración
que le vemos al a Kafka,
podría ser necesario crearlos
ya previamente.
En cuanto a la relación
topic productor,
pues vamos a tener una
relación en enero,
podría?
Podríamos estar un mismo producto,
podría estar escribiendo
en diferentes tope,
y si este es uno de los casos
que hablábamos antes,
como en el tema de la tele
-escribíamos en dos tópicos.
Una coloso, objetos sin relaciones,
los objetos planos y otro tópico
con las, con las relaciones,
y ahí también podría ser al revés,
tener varios productores para
parar el mismo tope,
aunque eso podría, habría
que ver el caso,
el caso de uso, pero bueno, podría,
por ejemplo, el caso de Elliott,
al que tengamos varios dispositivos
leyendo información de temperaturas
en diferentes momentos, por ejemplo,
una cadena de frío?
Vale?
Pues todos ellos podrían estar
enviando a la misma,
a la misma cola, de al mismo tope,
y entonces ahí podríamos ver ese,
ese posible caso y bueno,
número de topics y limitado,
dentro de evidentemente,
la capacidad del sistema bale y
posibilidad de dividirlo en nme
-partición es que nos van
a permitir hacer,
añadir o eliminar consumidores
para hacer un procesamiento
en paralelo por ejemplo entonces
bueno un poco
como como como decía tendremos
esas en este caso 4,
cuatro participaciones,
y tendríamos un un productor que
estaría escribiendo en el topic
y Kafka, después, internamente
de forma transparente,
al productor, iría asignando
a cada partición
cada uno de los de los eventos.
Normalmente es la clave de registro
en la que determina
a qué partición podría ir cuando
realmente digo que es un poco
el que nos lo va a gestionar.
Las participaciones, como decía
se podría facilitar.
Se puede utilizar para facilitar el
tener consumidores en paralelo
para poder consumirlos?
Hasta el número de partición
es, por ejemplo,
podríamos tener consumidores
distintos consumidores?
Como vemos antes, para
distintas cosas,
y eso es son distintos consumidores?
Vale?
Son distintas finalidades,
pero un mismo consumidor lo
podríamos tener replicado en veces?
Estoy hablando de este caso
no de tener varias réplicas
para para darle escala,
habilidad a esa a esa parte.
Entonces podríamos tener en este caso
pues, por ejemplo cuatro
consumidores del mismo sistema,
cada uno leyendo de una de las
de las participaciones.
Entonces esa de esa manera podemos
darles a esa flexibilidad
esas esa estaba escala habilidad
para mejorar el rendimiento
del del sistema por culpa
de este tema
o principalmente por lo que es uno
de los puntos principales,
por lo que no se garantiza
el orden también,
porque al final cuando estás leyendo
no tienes qué exactamente leer
en el orden que te lleva,
porque pueden estar leyendo
una partición.
Primero un mensaje que ha llegado
después de otro mensaje.
Que estén otra partición que
todavía no has leído?
Por ejemplo, no.
Entonces, es uno de los
de los puntos.
Otro de los motivos por los que
no nos garantiza un orden,
en este caso.
Entonces, bueno, básicamente,
lo que es una partición
viene a significar, está esto,
no deja de ser una, una,
que al final vas escribiendo
elementos
o sucesivamente de forma
de forma secuencial.
1, uno tras otro a la que
vas escribiendo,
como es el caso, de la cajita verde.
Vale, podíamos tener varios, varios
consumidores, en este caso,
como mal caso, los tarjetas azules,
vale?
Sería un poco el caso que,
como decía antes,
vamos a tener el procesamiento de
eventos que nosotros vamos
a tener dos ahora mismo, no?
Pues aquí vemos como uno de
uno de los sistemas.
El sistema está leyendo la,
el evento, número 4,
mientras que el sistema b
va va mucho más rápido
y ya está leyendo el número 10, vale?
Entonces son.
Es algo que nos va a facilitar
este sistema,
a este sistema para poder,
para poder llevarlo,
para poder llevarlo a cabo.
Vale, bueno, entonces este
esta forma de trabajar,
este estilo arquitectónico,
realmente suele denominarse
arquitectura capa,
vale y suele materializarse
mediante el uso de casco
como como estamos viendo entonces
bueno, este uso del casco,
como decía, me va a permitir
utilizar ese distribuido como fuente
de de verdad,
permite desarrollar diferentes
vistas de los mismos datos.
La vista puede ser una
base de datos rbs,
o índice de búsqueda, como bueno,
va a permitir un poco conectarlo.
Ahí la aplicación productora de
eventos comenzó a fallar,
generando datos incorrectos,
relativamente sencillo modificarlos.
Los consumidores, también de eventos
para adquirir los datos erróneos.
Es una base de datos más al uso.
Se se corrompe su restauración,
podría ser más complicada,
vale.
La la decoración puede
ser más más sencilla
en el ojo de solo escritura.
Que una base de datos que se
modifica continuamente,
puesto que los eventos pueden
volver a ejecutarse,
para explicar qué ocurrió una
determinada situación,
es decir, cualquiera podríamos
volver a coger el look,
decirle que él volverá a hacer un
rol vaca un momento dado y volverá
a acoger todos los eventos desde
un punto en concreto
desde un objeto, desde una
cajita; en concreto;
es decir, por ejemplo, en este caso
podremos volver a coger el programa
que se ha corrompido sistema
b desde totalmente
pues podríamos decir, volverá
a hacer una limpieza,
limpiarlo por completo y volver
a aplicar todos los eventos,
diciéndole que empieza a leer
en el cero de nuevo,
con lo cual esto esté este tipo
de arquitectura capa,
pues nos va a facilitar este está
esta situación para volver
a restaurar la, la información.
Bueno, para el modelado de datos,
autorización de un look que
solamente permite añadir datos,
puede ser más más sencillo,
que el uso de transacciones así
sobre base de datos nacional,
y el hermano el patrón encaja
perfectamente con esta pasta,
estilo arquitectónico,
también puede facilitar el análisis
del dato de un dato posterior,
es decir, vamos a saber
cómo hemos llegado.
Hemos llegado a una situación
da en concreto
ya que podemos analizar
todos los décimos,
cómo hemos llegado a tener,
cómo ha llegado el consumidor a
tener esto, pues podemos ir viendo
desde desde cómo ha pasado desde
desde el cero hasta el 10 que que
eventos que ha ido sucediendo
en el sistema es muy,
muy fácil de seguir en ese, en ese,
en ese caso y, por supuesto,
el desacoplamiento de la publicación
de los consumidores
como, como decíamos, todo esto
parece repetido de lo que ya antes.
Pero bueno, esto es relativo
a la arquitectura capa vale lo
cual encaja perfectamente
como como decía con con como
un motor de Destiny,
como puede ser.
Claro que Kafka tienen tiene
inconvenientes,
como, como ya he comentado antes,
y no está diseñado para garantizar
el orden de los eventos enviados
y habrá casos en los que,
si hace falta,
garantizarlo entonces para ello
vamos a optar por un sistema tipo jm sé
cómo es, como dicen, que es
un bloqueo de mensajería,
como hacía jm o pensador;
se implementa simplemente a
la especificación j, j,
y además nos garantiza que
preserva el orden
de los de los mensajes enviados,
lo cual es muy, muy importante
como contrapartida,
pues tiene otras implicaciones,
como tiene un mayor consumo de
recursos en el sistema, etc.
Etc. Con j.
M es en concreto,
pues podemos tener la opción de
publicar mensajes a un tópico
o a una cola Bale.
En el caso de Cascos
solamente teníamos la
opción de tópico.
Hay una diferencia fundamental entre
entre las dos puntos de vista
vale que está un poco ilustrado,
aquí está en este esquema un Topic,
reenvía o envía el mensaje,
desde el productor a varios
consumidores al mismo tiempo
sea enviado el mismo mensaje
a todos ellos.
Es una especie de realmente no final.
Lo comentábamos antes en el caso
de la gestión de eventos
para proceder a los eventos para
para los diferentes almacenamiento,
y al final es el sistema de gestión
que está insertando un evento
ahí y lo va a recibir.
Vamos a tratar todos los
procesadores de eventos
van a tratar el mismo evento, pero
habría otra otra opción
en el caso de caso de jm que
sería la cola vale?
En este caso eso en este caso
también vamos a tener consumidores,
pero cada uno de los de los
mensajes o eventos
se va a dirigir a un solo consumidor,
solo un consumidor va a
tratar a ese mensaje.
Entonces, digamos que aunque
tengamos varios,
vale entre ellos, se van a acabar
dividiendo la la carga
y van a estar haciendo un trabajo
de forma de forma secuencial,
dividendo, dividiéndose dividiéndose
cada uno de los de los mensajes
por turnos.
Realmente es una especie de pleno
en ese sentido en este caso
de la aplicación bueno como decíamos
lo vamos a utilizar
en esa parte del procesamiento de
eventos para garantizar el orden,
y lo vamos a ver, lo vamos a usar
como un tópico vale para ser la
forma más parecida a lo que es un Kafka,
vale lo que a lo que estaba
pensado originalmente,
y ya como tiene que funcionar
esa esa parte.
Pero, además, dándole un plus,
que es garantizando
esa ordenación, que era el problema
que nos que no estaba,
que nos estaba dando a Kafka en,
y por ello hemos decidido ir hacia
hacia un modelo con j.
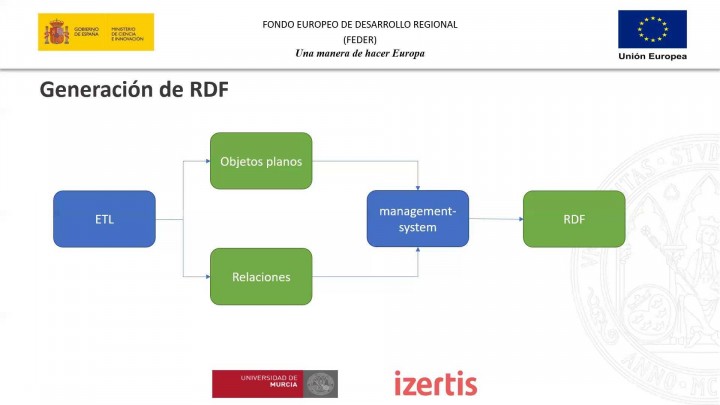
En cuanto al proceso de
generación de rdc,
vale?
Bueno, ya hemos visto un poco
las piezas principales,
más o menos, pero volviendo a
hacer un poco hacia atrás,
cuando nos llegaba a este modelo
de gestión el dato
lo que nos estaba llegando
era lo que nos estaba
enviando la tele,
a grandes rasgos lo que nos va
a llegar son esos ojos,
esos objetos, planos, esos objetos
que ya están transformados
en lo que en lo que define de alguna
manera la odontología,
vale en ese formato que se va
a insertar en el sistema
y vamos a tener que generar
el rdc a partir de ellos,
es decir, nosotros ahora mismo
lo que tenemos unos objetos
con unos datos, una estructura
de datos,
pero no tenemos errores y no tenemos
los tripletes poniendo
desde ello ello lo va a llevar a
cabo el sistema de gestión.
Realmente.
Bueno, yendo un poco más a detalle,
que ya lo comentaba, no
son sólo los ojos,
no va a tener un algo algo que sea
poco lo que nos va a llegar,
sino que se va a dividir
en 2, por un lado,
a estar los objetos planos, los
objetos en las relaciones,
y, por otro lado, las relaciones
ahí por lo que lo que decía,
para gestionar que no me llegan,
relaciones con las algo
que todavía no tengo,
el sistema vale de esta manera.
Primero proceso, todos los
objetos, planos planos
los incierto en el almacenamiento y
luego ya los con las relaciones,
pero sabiendo que ya
tengo los objetos
a los que voy a relacionar, es
un poco un poco el motivo
por el que se hace entonces,
nada.
Con todo esto el sistema de
gestión va a generar,
finalmente el.
El rdc, por ejemplo, un ejemplo
de objeto plano
de los que nos va a llevar
desde la tele,
va a ser Bale, no deja de
ser un un Jackson,
que luego al final se puede reducir.
En una clase, un objeto de una
clase vale un objeto plano?
Pues va a tener esta pinta,
va a tener una operación
que va a ser bueno,
este caso es inserción,
pero también podría
ser de eliminación o de modificación
de datos bale,
y luego va a tener los datos
en sí mismo, no?
Pues pues vamos a saber que
es de tipo proyecto,
en este caso vale,
y además va a tener toda esta
toda esta información.
Todos estos datos son los que son,
las que va a tener Bale.
Como veis, no tienen ningún
tipo de relación
con con nada.
Esto es lo que que es
el deseo es objeto,
es objeto plano, sin más,
con los datos básicos,
con todos los literales,
por así decirlo,
que nos va a permitir darnos de alta
en el proyecto luego luego ya
cuando no nos una vez estaba
el objeto plano.
Nos va a llegar más?
Está mal el título, aquí
sigue como plano,
pero sería este sería el la relación,
las relaciones Bale, esté vacía,
una vez procesados.
Todos esos objetos, planos
ya tenemos,
todo insertado, vale,
toca unos con otros
para para formar todos
los datos enlazados,
y entonces nos va a llegar
otro otro tipo de objeto
a través de otra cola
o de otro topic.
Vale?
Quién nos va a decir qué
relaciones tiene,
por ejemplo, volviendo al caso
del proyecto anterior?
Vamos a decir que este proyecto
10.154 Stalingrado por un lado,
hay Boix, en este caso bueno,
pues resulta que no tenía ninguna
ni ningún lío, pero bueno,
no de otras maneras no nos venía,
nos venía ahí pero sí que está ligado
a ciertas personas no personas
que formaban parte
de ese proyecto, que sería todas
estos identificadores que nos viene
aquí y entonces el sistema.
El sistema de gestión va a
saber cómo, cómo hacer.
Esos haces láser
para tener que generar
esas tripleta para,
para enlazar los datos, unos
con los unos, a los otros,
son los recursos o, mejor dicho,
unos con los otros vale para hacer
toda toda esta inserción,
por decirlo de alguna manera, para
hacer toda esta esa generación
de, para generar los recursos hay
una cosa muy importante.
Es decir, el sistema de
gestión por sí solo
no va a ser capaz de hacerlo,
no va a ser capaz de.
Iba a tener que apoyarse en
otros en otros módulos,
en otros sistemas adicionales.
Por un lado,
vamos a tener que generar una vale
al principio de la sesión
cuando empezamos a primera hora os
comentaba que todo todo recurso
en el sistema va a estar
identificado mediante una mediante una uvi.
Por ejemplo, antes veíamos
que el recurso Picasso
pues tenía una orilla identificaba
que ya está el punto de Barra,
Picasso que nos habló de memoria.
No vale esa esa identificación.
Nosotros por sí solos no
vamos a poder hacerlo,
porque no vamos a poder hacerlo,
porque de alguna manera tenemos
que mantener un registro
de esa surfista que podría
identificar.
Luego no nos va a venir otra
vez el mismo dato
en el caso de la misma, uri
mal entonces digamos
que el sistema de gestión no va a
poder saber hacer hacer eso.
Es tema de gestión lo que va
sin saber es general,
pero para ello tiene que saber las
escuelas que tiene que trabajar,
tanto, tanto las de, que
identifiquen al recurso
como las cámaras para identificar
cada uno de los atributos
que va a tener ese recurso,
porque los atributos,
los suelos valores,
pero los tributos van a ser
también tripletes,
como, como también veíamos que, como
por ejemplo el nombre o Bueno,
volviendo un poco poco atrás,
pues todo esto pues la modalidad
la fecha de fin la descripción etc
etc éste se va a traducir en lo que
es una Uriz dentro del ecosistema
de una hora y general para todo
este objeto María Mateo,
este recurso, pero luego cada
una de las de los atributos
va a tener su propia obra y que
lo identifiquen además,
y luego también que va
a tener otra Gauri.
Bueno, pues todos los objetos
de las relaciones,
evidentemente, antes veíamos
como el nombre era una,
era un literal que al final era
una cadena que era Pablo.
En el caso
de un austero podríamos tener
relaciones con otros, con otros,
con otros recursos también o que no
sea que no fuesen literales,
sino que fuesen otros otros objetos
o recursos que tengamos en el sistema
y así ir enlazando generando
todo todo,
todo el grapo para ello es para para
lo que tenemos este esta factoría
de Ulissi, el servicio
de descubrimiento,
en la factoría de, Uriz
como una médica
la que se va a encargar de asignar
esas esas subidas
a los recursos generados de acuerdo
también a una política de Uriz
calla, calla establecida.
En el sistema,
no es el que va a saber cómo cómo
hacerlo como generarla
no al sistema de gestión le da un
poco igual, como cómo se genere,
simplemente quiere tener una nueva
y se tiene que cargar de ellos
este esta factoría de de un gris,
pero luego también también muy
relacionado con todo esto,
vamos a tener que realizar una
labor muy importante,
que sería la parte del
descubrimiento y la conciliación de entidades.
Claro que cuál es el cuál es el
problema para que para que lo veamos
yo me tiene que se me
llega a algo decir.
Si me llega un recurso nuevo, si
me llega una actualización
de un recurso o me llega
una inserción,
también podría ser de otra
fuente de datos.
Podríamos estar hablando
del mismo recurso,
es decir, un mismo mismo
investigador,
por ejemplo.
Podría venirme a lo mejor,
pero no estás diciendo
una barbaridad,
pero podría venir a una universidad
de la Universidad de Murcia,
por ejemplo, también podría venirme
el mismo que ha colaborado
en un proyecto la Universidad
de Oviedo,
por decir algo.
No.
Entonces, de alguna manera
tendría que poder saber
que ese mismo investigador
es el mismo.
Estábamos hablando del mismo recurso
y ahí es donde entra en juego.
La librería, de descubrimiento,
de la librería descubrimiento,
lo que va a hacer es esa,
aplicar diferentes mecanismos,
diferentes, algoritmos,
para poder identificar,
para poder saber si es
o no es el mismo
el mismo investigador que
estamos hablando.
Si si tuviese un mismo identificador
en ambos sistemas,
sabríamos que no habría forma,
habría forma de poder identificarlo
fácilmente,
pero muchas veces no es el
caso y muchas veces
pues a lo mejor nos va a
llegar con cada uno
cada uno de esos sistemas con
diferentes identificadores,
pero sabemos que el usuario, que
el investigador es el mismo
porque se parece en un grado alto
de un porcentaje muy alto,
no?
Entonces tenemos que poder determinar
que sea que sea el mismo porque
se llama y se apellida igual,
porque porque vive en el mismo sitio,
porque la fecha de nacimiento
es la misma, por ejemplo,
no por poner dos ejemplos.
Aquí no;
entonces es lo que se encarga del
esa librería de descubrimiento.
Habrá otros casos.
Habrá otros casos en las que
no sea posible hacerlo.
Mediante un proceso automatizado,
que una máquina no sea capaz
de identificarlo entonces,
en esos casos
pues sí que habrá que hacer
una, una labor manual
y de hecho así está previsto que
haya nada, una cierta manera,
una forma manual de resolver
aquellos casos que no sea la máquina,
no sepa cómo cómo resolverlo.
Entonces, esa esa labor es la
que va a llevar a cabo.
La librería de descubrimiento.
Entonces, bueno, hasta hasta aquí
finalizamos un poco lo que es la
generación de rne y demás.
Así que si tienes alguna duda, me
imagino que muchas todo esto
y otras maneras Oslo va a contar
en profundizar mucho más
en sesiones posteriores de esta.
Esta parte justamente que
estamos hablando,
estamos hablando ahora.
Yo tengo una pregunta.
Una, qué pasaría si el procesamiento
de las colas cae la máquina?
Supongo que se persistirán,
indicó y luego se recuperará a
levantarse así si ese en ese caso
sí se cayese a la máquina.
Digamos que como tú tienes
constancia de dónde está la leíste,
el último elemento,
cuando se vuelva a levantar
la máquina,
cuando se vuelva a recuperar
seguiría leyenda en el último que ha dejado,
con lo cual no habría ningún
tipo de pérdida.
Es una de las ventajas que tiene
este sistema de procesamiento
en streaming, bale y luego otra cosa.
Cuando has dicho al final
que el mecanismo de disco
debería bajar,
tendría que actuar.
Una persona para resolver
la ambigüedad
de una persona informática
o una persona usuaria,
una persona experta en el dominio,
por decirlo de alguna manera,
tiene que ser alguien capaz
de resolverlo.
Luego a esa persona habrá que
ponerle los mecanismos
para que pueda hacerlo, ya sea
a través de una interfaz
o más más amigable.
Ha trabado a través de un
fichero, por ejemplo,
que se procese Bach.
Eso sabría que todavía está sin
terminar de definir esa esa parte,
pero desde luego,
tiene que ser alguien que sepa
que conozca el dominio
y que sepa como cómo resolver
el conflicto.
Lógicamente bale era bueno.
Yo tengo otra duda con Holly,
con respecto a los topics
y los eventos,
cuando no me ha quedado claro,
cuando creo que, por defecto,
el cuando terminaba de
procesar topic,
se avisaba todos los
altos los eventos,
pero vosotros lo tanto creo que era,
o algo así me solo avisaba,
vais al al evento o al consumidor.
Lo requería en que requería ese dato,
no viéndola la transparencia,
no me ha quedado muy claro,
porque estaba el modelo p2 p;
y el modelo transparencia.
Si vale a ver aquí la diferencia
entre entre ambos modelos.
Digamos que, por un lado, si
nos vamos al modelo p2 p,
que digamos que los consumidores
estarían procesando;
los datos, por turnos,
digamos que ejemplo,
si yo voy metiendo en datos Vamos,
por ejemplo, el primer consumidor,
pues precisaría al primero
el segundo, el segundo,
el tercero, el tercero, Bale
el cuarto, el cuarto,
y luego evaluaría otra vez
a al primero otra vez.
Dirían por turnos procesando cada 1,
un dato, no todos, todos los datos,
como el otro modelo en este caso,
se irían repartiendo, por decirlo
de alguna manera,
si con eso queda cada día más.
Claro, se va repartiendo el trabajo
de los consumidores.
Es el modelo p2 p, con
el modelo de cola,
vale de en el ecosistema jm.
Sin embargo, el otro modelo de
publicados y suscripción mal
el modelo de topics digamos que
todos los consumidores
van a estar leyendo en paralelo más,
pero van a la van a hacer,
vas a leer todos los los mensajes
que se envíen a la al tópico.
Es una especie de en este caso.
Pero la solución adoptada
aquí cuál ha sido
la esta última que acababa
de comentar?
Por qué más se parece a Kafka?
En ese sentido, Kafka trabaja
de esta manera.
Precisamente, como si fuese un
broncas y cada uno lee,
y si me interesa lo coge,
y si no es apto para correr un
poco más atrás, aquí vale.
Por ejemplo, si si vemos en este
caso la iigm que va la parte
del en la parte del centro un
poco hacia la derecha vale.
Y lo que vamos a tener son
dos procesadores.
Es bueno para llevarse
otro para Bale,
pero cada uno de ellos tiene que
recibir todos todos los mensajes
que recibirlos todos.
Luego, ya que si internamente
deciden a procesarlo
es problema del consumidor
pero llegarle vas
a llegar vale vale vale no llegan
y interesar el proceso
y si no, no Exacto, exacto, si no
la desperdició y ya la deshecha
y hasta ahora no me había
quedado claro
cuál era la opción que sabía
que se había adoptado,
si es es la de publicación y
suscripción, la, por decirlo
de alguna manera.
Eso es gracias.
Una pregunta más.
Que queráis comentar.
Si tenéis, al final lo bueno
cuando sea sin problema.
Bueno, pues en ese caso
vamos a continuar
hacia cómo vamos a almacenar
los datos.
Volvemos otra vez a ver un poco
la positiva anterior
para tenerlo claro, bueno, haciendo
un poco también relación
a lo que acabamos de comentar
ahora del,
pues eso va a llegar a todos
los procesadores,
como como ya comentábamos,
y cada uno de esos procesadores va a
decidir qué hacer con esos eventos,
y realmente se lo va a enviar
a la gestora Sabater,
y en este caso
y en la sala pero es el que se va a
encargar de adaptarlas al sistema
que corresponda, caso a utilizar,
en la piel de Pepe, para
estarlo entre él,
y si en el caso de Wikileaks pues
lo va a insertar utilizando
el propio cliente que nos
proporciona para para,
para trabajar con él mismo.
Bale entonces un poco poco bueno
decía eso tenemos dos dos
dos a dos almacenamientos dos
lugares en los que se va
a almacenar.
Bueno, pues en cuanto a las decisión
para elegir uno u otro en este caso,
pues efectivamente, pues lo primero
tendría que cumplir
con estas especificaciones
para el proyecto,
así las que se planteaba
en el propio pliego.
Pues también para el tema de
los plazos de entrega,
la flexibilidad, la reducción
de la deuda técnica,
uno de los puntos que comandaba
el pliego,
porque pongo ese primer punto vale,
porque hay un factor muy determinante
que fue que tuviesen la posibilidad
de intercambiar el triple.
Store en un momento dado además,
que éste está esta solución.
podría estar pensada para que se
desplegase en varias universidades
que cada universidad, la despliegue
bajo su bajo,
su paraguas, con sus propios
datos, etc.
Una estancia de la de la misma.
Por lo tanto, cada uno de
ellos debería ser capaz
de tener la posibilidad
de poder intercambiar
el triple Store que se está que se
va a utilizar en la solución final.
Entonces, por eso, por eso es el
motivo de este este este punto.
Porque, por ejemplo, lo primero
que pensamos fue
fue en poner wiki base vale?
Ya que iba a ser, te da muchísimas
cosas ya ya hechas,
te da toda la parte de consultas,
tienen muchísima potencia
ahí en esa esa parte,
pero, por ejemplo, no, no vamos a
poder cumplir con ese objetivo
de poder intercambiar
el triple Store.
Uy, qué base está muy ligado
en ese sentido!
Vale?
Entonces por ello por ello lo
he querido reflejar Bale.
Este es un poco el esquema que nos
da la arquitectura de wiki base.
En este esquema se precie.
Un gran bloque funcionaba
en azul que digamos
que sería el core de su deseo
aplicación desde su de su sistema.
Eso también por tanto, soportaría
la mayor parte
de la carga funcional de whisky.
Base sería posible añadir.
Ciertas extensiones.
No tiene la posibilidad
hasta cierto límite
digamos no no podría ser demasiado
demasiado profundas al final
como tecnologías de almacenamiento
pues iba a ser almacenar.
Como vemos aquí es verdad que
ya lo he comentado antes,
que sea su triple héctor el que va
a utilizar de forma nativa,
sin posibilidad de modificarlo.
Bale.
Tiene que ser ahora sí o sí pero
además utiliza para otros,
para otras partes, para otros datos.
Utilizaba otros sistemas de
almacenamiento se cuele sui
o las tijeras como motor
de indexación
para hacer ciertas ciertas consultas.
También lo que lo comentaba.
Una de las puntos grandes o fuertes
que tienes es un sistema
totalmente integrado,
y es muy sencillo llevar
a cabo un sistema,
un sistema de este tipo, pero
tiene ciertas carencias
que hace que no sea adecuado para
core de nuestra aplicación,
sino que sería una solución
en sí mismo seguramente,
pero eso, o lo tomas o lo dejas,
dejamos no es más difícil de adaptar
a las características concretas
de este de este sistema que
estamos desarrollando.
El caso de, por ejemplo, ya
vimos antes este esquema,
pero por volver a tenerlo presente,
al ser un servicio mucho más modular,
nos va a permitir, bueno,
por un lado,
hacer las modificaciones que
necesitemos pertinentes.
Bale también nos va a
permitir realizar,
escalado horizontal redundancia eso.
Por lo tanto, es bastante
potente en ese sentido,
además de cumplir con el plazo con
la especificación que también
era otra de las de las necesidades
que teníamos.
En este ese sistema
y que Wikileaks no nos
no nos da llevasen,
no es un servicio en sí mismo,
así que sí que sería un servicio
para el almacenamiento de datos
enlazados, data, pero no cumple
con la especificación.
Por lo tanto, por lo tanto también
es otro de los motivos,
por lo que a ser no nos va a valer
como core de nuestra,
de nuestra solución.
También comentábamos antes
que aquí podíamos soportar bases
de datos racionales y triples
Tor triples Tours.
Como ya comenté cualquier historia
entre comillas por defecto
vamos a ver pero podríamos
conectar otros triples
Torres a través del encuentro, es
parques de forma bastante,
bastante fácil, sobre todo
en el caso de fucsia
y al al tener por debajo
te debe también
y pues tiene una, tiene, se lleva
muy pero que muy bien,
no obstante se podría integrar
con otros triples Torres,
si bien es cierto que en función
del tipo historia
habría que volver a pasarnos la
tesis del PP para garantizar que sigue
que sigue combatiendo a
un gran porcentaje
toda todas la especificación, vale
que no tengamos grandes grandes
problemas en ese sentido.
De acuerdo.
En bueno el tema de versionado
con los elementos que comentaba
también antes y también buena
relación con con casco pero
no del mismo manera
que acabamos de ver en este caso
para enviar a otros sistemas una vez
una vez se inserten los datos en
entre y Bale la forma de verlo
bueno lo acabó justo comenta lo que
la forma que vamos a integrar
no va a ser directamente
con contenedores,
sino que va a ser una integración
a través de fusil por su puesto
y puentes parques.
Hubiese acabado utilizando, debe,
como como vemos aquí no fuese,
es un servicio que puede correr
como como servicio
de sistema operativo como
como una aplicación web
y como servicio independiente,
y ese sería un poco el caso
que vamos a tratar proporciona esa
capa de extracción al acceso
a al sistema de almacenamiento
y proporción
proporcionando un protocolo
para la conexión
a través de ese puente Bale
por defecto interesante.
Debe que como un sistema de
almacenamiento robusto
y transaccionado al utilizar
por debajo de Jena también
como como veíamos anteriormente uno
de los sistemas junto a Ford j,
y en cuanto a la seguridad también
en el caso de fucsia
y aquí también nos va a proporcionar
cierta cierto nivel de seguridad,
ya que vamos a tener que
poder acceder a a él,
no solo a través de tres como él,
sino a través de sus imponente
parques vale para poder hacer
las consultas, es una ley
de la finalidad,
una ley de penas, de proveer
de un en los parques,
sino de un que nos va a permitir
consultar los datos.
Vale?
Entonces, para suplir esa carencia,
vamos a utilizar el encuentro,
es parque del que nos de fuese
quien esté en este caso.
Entonces, de alguna manera
tenemos también
que garantizar la seguridad
y en este caso
la seguridad que trae de serie fuese
aquí es utilizando apaches,
sino que permite implementar esa
autenticación y autorización
y que a veces fácilmente integrarme
con esa capa de permisos
de una capa de permisos de género,
aunque también que también para,
para ir ya a nivel de a
nivel de tripleta,
a nivel de recursos, mejor dicho,
poder limitar el acceso
a ciertos datos
que pueden ser más sensibles
en el sistema.
Entonces, como veíamos, íbamos
a tener dos opciones.
Teníamos wiki base y 3, 2, dos
tipos de almacenamiento.
Esta opción,
pues, realmente propone que la
elección de las dos opciones
anteriores, en paralelo, lo que
comentábamos antes, las dos
va a servir para distintas cosas.
Entonces, por un lado,
digamos que, como core de
la de la aplicación,
la idea sería, como decía,
utilizar junto con Bale,
por otro lado, para un perfil
más administrador,
pues vamos a tener wiki base que
permitan permitir consultar
los datos de una forma bastante,
bastante rápida,
en caso de que puede estar
más habituado
a este tipo de sistemas.
Bueno que sea un poco porque
se ha decidido optado
por una opción o por o por
otra un poco el cuadro
de para ver cómo se amolda
a la a cada
a cada uno de los requisitos
que teníamos.
En primer lugar, como decía,
suena en el caso de wiki base.
En cuanto a la autenticación, según
la documentación disponible
utiliza, se podría utilizar doble
que sería un plug-in.
Entonces se permitiría que
iba a ser elevado
en cualquier proveedor de Watts
o es lo que vamos a utilizar para
autorización, autenticación?
El sistema?
Vale para todo este tema de micros?
Servicios es muy, muy cómodo
utilizar otro doblete,
con un 2, con 1,
vale para hacer esa transferencia
del toque de autenticación,
ya que ya que digamos que no
te hace falta depender
de sistemas de autorización externos
digamos que es el propio
toquen por sí mismo, es fiable valen,
con lo cual, evitar sobrecarga
de consultas
a otros sistemas internos
para validarlo.
Entonces, la idea es seguir
por ese camino
y por eso teníamos esa esa necesidad.
Vale?
Entonces digamos que se podría ser.
Podría conseguir por ese camino,
bueno, tanto el ajuste de requisitos!
En este caso sería sería grande.
En el caso de trenes con confusión,
pues ya soporta de serie la
autenticación, doblete.
Con lo cual.
Por lo tanto,
es también un un alto nivel de de
adherencia, ese ese requisito,
en este caso para analizar
el proceso de de lo bien
y además también decir
que utiliza la web
y de la forma que se que se indica
la especificación de referente
a la web y con especificación,
o entonces digamos que lo tendríamos
garantizado también.
Por otro lado, podría trabajar como
autenticación básica, Bale,
aunque en este caso no penal,
y en concreto, Bale.
Este caso no sería la
opción adecuada,
sino que tendríamos que ir más
al otro, a la otra opción,
utilizando otro doblete.
En este punto estarían los dos en
un alto nivel de adherencia
al requisito.
En cuanto a la autorización,
en el caso de Huawei,
que iba a ser,
no hemos encontrado ningún tipo
de documentación relevante
que indique que por sí misma
o mediante el uso
de algún se pueda proporcionar algún
mecanismo de autorización
con la claridad suficiente
para cubrir los requisitos
del proyecto,
aunque es cierto que se
puede establecer
algunos aspectos de la autorización
a nivel global sobre la plataforma,
tales como lectura.
Ha decidio creación borrada
de entidades
y algunas autorizaciones
administrativas,
como creación de usuarios, etc.
Etc. Pero parece que no es posible
gestionar una autorización
a nivel de recurso
Bale, que es un poco lo que lo
que necesitaríamos en este
en este caso entonces, en este caso
el nivel de ajuste de requisitos
no sería,
no sería adecuado en
el caso de trenes.
En este sentido, Bale,
al utilizar uefa
a hacer para la para autorizar,
sí que permite,
como vimos antes como ejemplo, el
definir a nivel de recurso,
quién y quién no puede acceder
a ese recurso en concreto.
Por lo tanto, ese es el
nivel de ajuste.
Requisito sería, sería alto.
En cuanto al tema de la que
data del que comentaba,
no es un servidor de Bale,
se utiliza su propia.
Entonces no se sabe ni lo
pretende de acuerdo
Bale entonces y tampoco le incluye
entre sus entonces las posibles.
Simplemente acciones para entonces,
en ese sentido pase
no va, no va a adherirse a los
requisitos de ninguna manera.
Señalaron Álvaro.
En el caso de que cumple plenamente
el la especificación de hecho.
Bueno, como decía alguna vez, ya
he comentado antes el tema,
sea utilizado, además
para verificarlo
y, efectivamente, efectivamente
lo cumple,
aunque si bien es cierto, aparecen
algunas algunos incumplimientos,
pero se puede, se podría
deber a ciertos formas
de interpretar la norma, digamos,
de alguna manera,
porque realmente la garantía de
que el nos diga que cumple
desde el año 2018 con el que vamos,
yo creo que es garantía
suficiente como para,
como para poder decidir
qué puedo decir?
Que tiene un alto nivel de
ajuste en este sentido?
En el caso del pueblo de Sfar,
que el base en principio cumple
con los requisitos
enunciados en cuanto al
encuentro es parqués,
ya que voy que iba a ser,
expone un empollón,
básicamente porque cuenta
es parte del ballet.
Pero realmente se es esa dependencia
de blogs Graphic
por decirlo de alguna manera, hace
que que no se pueda cumplir
con la independencia de
independencia de triples,
por decirlo de alguna forma, no?
Entonces sí que sí que podríamos
decir que cumpliría
con qué tienen en puentes parques,
pero no, no puedes intercambiables,
no puede ser independiente de
lo que tengamos debajo,
ya que tendría que ser siempre en
el caso de trenes más use.
Bueno, pues en este caso fuese.
Aquí nos provee de puentes
Parken Bale,
si bien es cierto que podríamos
incurrir un poco en el mismo problema
que en el caso de wiki base vale,
pero pero como realmente el coro de
nuestra aplicación va a ser,
el podríamos como como ya comentaba,
intercambiar y por otro,
por otro triples.
Todos los puentes parques que
tengamos ahí hay debajo,
ya sea con él a través de
su imponente parques
o bien implementando un modelo
de persistencia de datos
dentro dentro de tres que
lo adapte al al nuevo,
al nuevo almacenamiento, o
al nuevo puentes parte,
con lo cual en este caso sí
que creemos que el ajuste
requisito es es alto.
En ese sentido, en cuanto al
análisis de requisitos de triples
-Touré, vale, como en el
caso de wiki base,
como ya como acabamos
de comenzar, ahora,
se utiliza además construir su
propio servicio de consultas,
el entonces Kohl
desplegado por, por lo tanto, usar
esa funcionalidad fuera de fuerza.
La lección del triple historia
sólo obliga,
como como acaba de comentarlo
y, por tanto,
tiene un fuerte acoplamiento
entre entre wiki base,
con.
Entonces los requisitos relativos
a esa esa lección de triples
Touré nada, hace que no tengamos
un grado de libertad
para poder seleccionar uno u otro,
por lo tanto no habría un bajo
nivel de cumplimiento.
En ese sentido
y y también relacionado con lo que
comentaba antes de enfrentarse a ella
pues sí que hay en ese caso cómo
podemos intercambiarlos
de forma bastante sencilla pues
el nivel de cumplimiento
sería sería alto, hasta aquí
vamos a tres días,
está ganando por goleada
en ese aspecto,
pero algo en el tema de la interfaz
gráfica en ese caso Wikileaks,
pues ofrece una interfaz mucho
más sólida y madura puesta
en producción con éxito, por ejemplo
en el proyecto que data
que además ofrece cierto grado de
personalización hasta cierto punto,
lo que permitiría probablemente
adaptar a las distintas universidades
en este sentido o perfiles del
cliente que puede ser necesario
para el proyecto.
Por ello creemos que en este caso
la interfaz de Wikileaks,
que tiene un nivel de madurez alto y
se ajusta mucho a los requisitos
por por contrario la interfaz
es demasiado madura.
Seguramente no es el objetivo
de ofrecer esa esa interfaz
de usuario y y ya no son un elemento
con la de la solución.
Vale?
Entonces en este sentido
digamos que sería insuficientes
a esa herencia
no no no tendría una no cumpliría
más con ese requisito
pero bueno.
Yo creo que este caso no
es tan importante,
el cumple con la parte de
la interfaz gráfica.
Ya que la entrega, la grada,
vamos a tener que desarrollarla
sí o sí.
De otras maneras.
Una interfaz adaptada al proyecto.
Con todas las.
Con todos los datos.
Un poco lo que vimos antes,
agregación gráficas,
etc. Entonces digamos que.
El que no cumpla este punto
no es demasiado.
No es demasiado importante.
Es más importante que
cumpla el resto.
Vale?
Por eso nos hemos ido.
Hacía así el modelo discusión
para nuestro coche.
Si bien es cierto eso.
También hemos escogido wifi base
para durante el proceso de desarrollo ya.
Poder explotar esa esa, esa
información por parte
de los perfiles y también de ciertos
perfiles administradores
durante durante el resto
del proyecto.
Entonces, digamos que nos quedamos
un poco con lo mejor
de ambos mundos, por decirlo
de alguna manera.
Bale, en cuanto, en cuanto
al almacenamiento,
en el sistema,
podemos decir que, bueno, como
como ya comentábamos,
que se va a hacer a través del
almacenamiento de redes,
realmente lo que lo que vamos a hacer
es, como vimos sistema de
gestión generales,
rdc, Bale, y a través de almacenar,
almacenar, los los datos
en a través de su app,
que es la que nos va a dar
las posibles opciones,
estamos hablando de la, de la parte
de la parte de Huawei que iba a ser,
utilizaremos el héroe que
iba a ser, lógicamente,
pero centrándonos ya en el coro de
la aplicación que se va a utilizar
a través de esa.
Para ello se utilizaría los
diferentes mecanismos diferentes
métodos http pulpos Lete etc
etc que nos va a permitir trabajar
con él con el sistema
para poder insertar actualizar
borrar consultar los datos etc
etc Bale y luego también
está esta pila de Pep,
pues también nos va a gestionar al
versionado de la información,
como como ya comentábamos antes,
para ver todo el histórico
de cómo ha ido, cómo ha ido variando
el dato en función del tiempo,
cómo ha ido el recurso, mejor dicho,
variando en función del, del tiempo.
Vale, realmente lo que vamos a tener,
por un lado, van a ser.
Alfred armamento bale,
vamos a tener diferentes su gris
en función del tiempo.
Por ejemplo, vemos aquí que que
para la versión actual
tenemos la Laurie, pero para
la versión anterior
tenemos la r1 y para la anterior
de la anterior teníamos
la al final no es que vaya
actualizando los datos,
sino que va creando diferentes
versiones.
Vale?
Entonces voy a poder acceder al?
Va dejando la foto de del recurso
voy a poder acceder al recurso
en un momento en un momento
dado no en el momento,
la versión que yo, que yo considere
que considere oportuno.
Entonces para ello al final
lo que lo vamos a hacer,
lo que se va a hacer para poder
obtener esa ese dato.
En un momento dado se añadirá
una cabecera.
Entonces yo lo que lo que sé es un
objeto sirve tener un recurso,
una obra de Pablo Picasso.
Por ejemplo, tengo Picasso
si la solicitud ese dato
tal cual sin nada más me para
dar la última versión,
la versión actual.
Pero si yo quisiera ver
qué dato tenía objeto
Picasso en el momento hace dos días,
pues podría añadir una cabecera,
la al método, que sería
acepta de eta,
en el que podría poner
una franja de tiempo
la que quiero ver como estaba
ese dato vale?
Entonces lo que va a
hacer este sistema
es de volverme otra Houry.
Bale nos da una dirección,
mejor dicho,
una dirección que voy
a tener que tratar.
Esa dirección es una red de
dirección hacia el recurso en ese momento
hacia esa versión en concreto.
Entonces esa de esa manera es cómo
voy a poder obtener los datos.
No fueron poco, a poco se se
vería aquí no hace nada
una especie de negociación de
contenido, en primer lugar,
en la que en la que solicitó
un recurso para la mano
una cabecera para ver cómo
estaba en cierto momento
y lo que me va a devolver a
un 303 con con la web rne
para poder acceder a ese recurso
en ese momento,
en concreto varios, un
poco como cómo va.
Cómo va a funcionar todo todo
esto de los elementos Bale
y nada.
Toda la parte de la del
almacenamiento
llegaríamos hasta hasta aquí?
Si surge alguna duda con respecto
a esto no, no.
Bueno, pues pasaríamos al al.
punto.
Sería la parte de los
modelos auxiliares.
Bueno, si quieres hacer un
descanso de 10 minutos,
como nosotros, yo creo que nos
da tiempo, pero bueno,
como queráis.
Sí?
Lo que quería era mi madre.
Vale, me noto si queréis, yo creo
que me sobra un poco de tiempo
vale vale vale venga pues
nos vemos hay 10
por ejemplo vale si venga ahora.