Una alumna de uno de la asignatura
de Estadística de Ciencias Ambientales
en este tercer vídeo del tema.
8, vamos a cerrar el análisis de
regresión lineal, simple,
donde lo que vamos a ver va a ser,
primero la verificación de las
suposiciones iniciales
mediante el análisis de los residuos,
y después vamos a ver cómo usar el
modelo de regresión para estimar
y predecir la variable y a
partir de un nuevo valor
de la variable de la autoría.
Antes de ver esto vamos a
hacer un breve resumen
de lo que hemos visto ahora
y si recordáis,
nosotros estamos considerando dos
variables que se relacionan
a través de lo que se llama el
modelo de regresión lineal simple.
En este modelo
tenemos una variable de valores que
están prefijados de antemano,
que se conoce como la variable
independiente,
que tiene un efecto solo una
variable y aleatoria
que la que llamamos variable,
dependiente en la forma que está
descrita en la transparencia.
Hay una parte que es una relación
lineal con la equis
y después hay un término
que es aleatorio
que estropea la linealidad,
bien para este modelo,
qué estamos suponiendo
sobre este dato?
Lo que hemos visto hasta ahora es
como hacer una estimación,
de ahí debe,
puesto que estos parámetros
son desconocidos
y después lo que hemos visto
es lo que se conoce como el análisis
de la variante en regresión,
que no permite realizar un contraste
para ver si la pendiente
de ese modelo es distinta
de hacer o no,
puesto que se valor, no está
descartado en el modelo inicial.
Además, ese análisis de la alianza,
lo que me permite también ver que
parte de la variabilidad
de depende de la relación
línea con la Ekhi
y qué parte depende del término
Epsilon que recordamos que
llamábamos residuos;
a partir de esta composición
también podemos calcular lo
que sea más eficiente;
determinación que nos va a permitir
decidir si el modelo es bueno
o no para predecir los valores
de y en función de bien,
pues aquí estamos haciendo una
serie de suposiciones
que tendremos que verificar.
Ese es su posición iniciales
con más detalle.
Era la siguiente.
Igual que la transparencia anterior.
Lo que tenemos claro es este modelo,
que relaciona la variable
con la variable,
y adicionalmente, lo que teníamos es
que determinó que era aleatorio.
El comportamiento que seguía era
el de una distribución normal,
comedia cero constante,
sin más cuadrado,
para cualquier valor que
nosotros considerara,
y además se topa los de Epsilon
que se van observando en nuestro
en nuestra toma de datos.
Son valores que son independientes
para los distintos valores
de la variable.
Bien, pues para verificar esas
suposiciones que estamos realizando
sobre el modelo que describen los
datos que estamos observando.
Hay tanto herramienta gráfica
como contact tipo antes,
pero por cuestiones de tiempo solo
vamos a considerar las herramientas
gráficas
y, además de estas suposiciones, las
la independencia de las observaciones
es posiblemente la más difícil
de verificar,
y no la vamos a abordar.
Por lo tanto, nosotros
nos vamos a centrar
en lo que es lo que es la,
la relación lineal,
la normalidad que sea de media cero
Valencia constante, sin
acuerdo, bien.
Cómo vamos a llevar a cabo ese ese,
esa verificación de las suposiciones
iniciales?
Bueno, pues eso lo vamos a hacer
a través de lo que se conoce
como los residuos.
Los residuos se construyen a partir
de las parejas de puntos
equis subí y subí en concreto para
cada pareja de en que subí
y vi lo que hacemos,
tomar la diferencia entre
la segunda ordenada
y subí y el valor de la
recta de regresión.
En el punto quiso recordar
que la recta regresión se calcula a
partir de las estimaciones de bebé
que hemos hecho en los apartados
anteriores,
pues esa diferencia en lo que
se llama el residuo,
mostrar y que aún no ha de notar
por subí con el símbolo
de este enzima, bien para
que nos puedan servir.
Esos residuos nos sirven
para lo siguiente,
fijaron que por la forma en que
tenía el modelo inicial,
en realidad, si yo tomo la
diferencia entre la variable y subí
y la recta y subí lo que nos queda,
es el término Epsilon,
que es lo que habíamos llamado
en el apartado,
en los apartados anteriores
del residuo kurdo.
Entonces tenemos por un lado el
residuo, que es una técnica,
es un, es una variable
que hemos definido
teóricamente a la hora de
construir el modelo,
y, por otro lado, tenemos los
residuos muestrario.
Si nos fijamos en la similitud
entre estas dos expresiones,
si nos fijamos en esta expresión
y en esta expresión de aquí
que al ser hago de este término
que está entre paréntesis,
puede ser un valor bastante
próximo al de aquí;
por lo tanto, esta diferencia
la podemos considerar
como observaciones de
Residuos Epsilon
subí en realidad.
No son observaciones puramente en
lo que se llama observaciones,
pero básicamente se comporta
muy parecido
a cómo debe comportarse el residuo
y hemos dicho anteriormente
que el residuo se comporta como
una distribución alma de cero
varias constante sin mácula.
Luego lo que vamos a hacer va a
ser utilizar estos residuos
como si fueran observaciones
del residuo,
y vamos a ver si el comportamiento
de los residuos
no confirma el comportamiento
que debe tener
el residuo en el modelo de regresión.
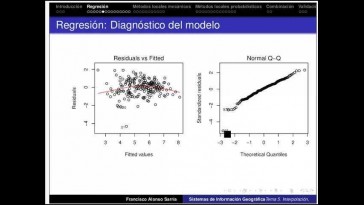
Bueno, pues entonces
lo primero que podemos hacer para
verificar esas suposiciones
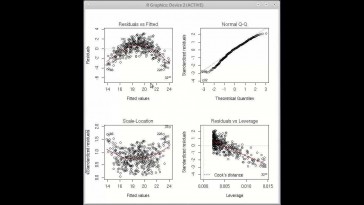
es construir una gráfica a
partir de los residuos.
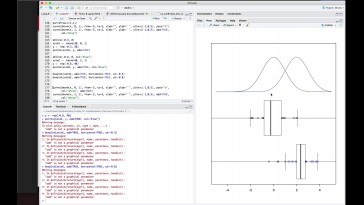
Que vamos a descubrir a continuación
esa gráfica
nos va a servir para verificar
la linealidad,
o sea, la relación a que los
residuos tienen medida cero
que la variedad es constante,
es decir en los residuos
y cómo construimos esa gráfica,
pues esa gráfica la vamos a
construir pintando en el plano
los puntos que tienen como primera
corte nada el valor y en Seúl,
la segunda corte, nada va
a tener el residuo;
mostrar de primera estos valores,
pues habría que reconstruirlo;
y no parece sencillo, pero es
más sencillo lo que parece.
Si vamos a darle es muy
fácil construirlo,
y en concreto los residuos mostrarle
y lo valore de de s v
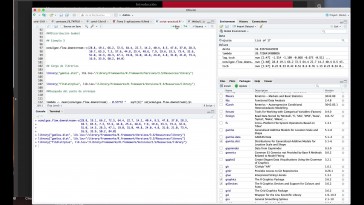
se pueden obtener en rne.
A partir de estas dos instrucciones
que aparecen en recordar que
nosotros tenemos dos vectores,
ya los tenemos insertados.
Tener ya lo que hacemos es que del
análisis de regresión lina
que se efectúa de y sobre
qué vamos a obtener.
Con este argumento adicional
lo valoré
-ahorro.
Me pego requisó y conecté
de aquí lo que hacemos
es obtener los residuos.
Vamos a ver como efectivamente
no son valores
aquí esto es lo que van apareciendo.
Son simplemente aburro.
Me ve gorro por cero los cinco
primeros son iguales.
Aquí era algo Roma ve gorro
en uno con cinco
como 25 sino recuerdo mal lo tiene
y así sucesivamente y ahora
con esta opción de que lo
que hacemos calcular
esos residuos que sí que parecen
un poco más complicado
de calcular por lo tanto eso
valore lo podemos calcular
y podemos hacer una gráfica
sin ningún problema.
Volviendo a la transparencia cuando
nosotros elaboraremos gráfica
el comportamiento que tienen
que tener esa gráfica
si hay linealidad la mediación
de Valencia
es constante en la siguiente.
Los puntos que yo voy construyendo
tienen que estar arriba
y abajo de la renta, igual
acero sin ningún patrón
es decir un comportamiento
totalmente aleatorio
y con una altura similar a
lo largo del voy a poner
unos ejemplos donde sí que se
comporta de manera correcta
y donde hay fallo en ese
comportamiento que indican
o falta de linealidad o falta de
variedad algo bastante bien
pues aquí he puesto como ejemplo
el ejemplo de arriba.
Es el ejemplo típico
donde se verifican las suposiciones
de linealidad,
danza, constante y residual acero.
Son valores que se quedan por encima
y por debajo de la red, igual acero,
que presentan más o menos
una amplitud constante
a lo largo de todos los valores
ajustado y no se observa
ningún patrón visible, éste
es el comportamiento
que esperamos si se verifican
esas suposiciones.
Cuando nos encontramos situaciones
como la de abajo es donde empiezan
a fallar algunas de esas
suposiciones inicial,
por ejemplo, aquí tenemos un patrón
donde se ve que la relación
entre aborda una gorra que
subí los residuos.
Mostrarle es creciente o una
situación como esta
donde de creciente y
después creciente
o una situación como esta donde
vemos que la altura va variando
conforme voy aumentando
los valores ajustado,
vamos viendo que estos valores
puntos se van ampliando.
Las dos primeras situaciones son
situaciones donde falla
la finalidad de que la
medida del residuo
sea cero entonces indicaciones
de patrón en concreto
como crecimiento o una, una
curva decreciente,
creciente o al revés.
Indican falta de linealidad, acero
y una situación como esta
donde vamos viendo que conforme
van aumentando
los valores ajustado la dispersión
de los residuos
o aumentando.
Son una indicación de
falta de igualdad
de varias zonas en los residuos,
así que en resumen,
lo que esperamos es un
comportamiento como éste de aquí y situaciones
como ésta señala,
falta de alguna de las suposiciones
iniciales.
En nuestro ejemplo.
No podemos construir,
puesto que hemos dicho anteriormente,
que aquí tenemos los valores
ajustada y aquí tenemos los valores
del residuo.
Yo puedo construir ahora un acuerdo
que perdonó una gráfica de punto.
Tomando como eje la lo ajustado
y como lo valoraré, residual
lo general y además,
lo que necesita la renta igual a 0,
para ver que efectivamente
se distribuyen más
o menos por encima por debajo.
Bueno, pues está una situación típica
donde se verifica la suposición e
iniciales más o menos en esta banda
se encuentran.
En este se encuentran
todos los puntos,
no se observa ningún patrón
y parece que podemos
estar tranquilos.
Respecto a que se verifican las
suposiciones iniciales,
no falta.
Una suposición inicial que
la de la normalidad
de los residuos.
Pero en ese caso tenemos una
herramienta gráfica
que ya hemos utilizado antes
que es el gráfico ocu,
en este caso de los residuos.
Así que lo único que tenemos
que hacer ahora
es construir nuestro gráfico.
Uno de los residuos muestran
cómo la mayor parte de los puntos
tan sobre en la recta
lo todo parece indicar que
normalidad al respecto de esta gráfica
cuando tengáis que hacer o un
ejercicio un examen yo lo único
que voy a pedir es que
lo si os parece
que se verifican si parece
que no se verifican
si fue la normalidad o no
fallan a la normalidad
y seguiría haciendo el ejercicio
de manera normal.
Necesito que sepa comentarlo.
No me importa tanto si acepta
del todo o no,
pero sí que necesito que los elabore,
y que hagáis algún comentario
sobre ella.
Bueno, pues con esa dos
herramientas gráfica,
las suposiciones iniciarán aquí hay
algo que posiblemente el choque,
y es que cuando hicimos en la nueva,
en el desarrollo del trabajo,
la verificación de la suposición
inicial le dijimos,
hay que hacerla al principio antes
de hacer toda la nueva;
sin embargo, aquí como ve
lo hacemos después,
cuando ya hemos hecho la nueva época
del coeficiente de determinación.
Por qué se hace después?
Pues darme cuenta que en la
elaboración del residuo
tengo que tener la estimación
de ahorro y gorro, recuerdo
y, por otro lado en la Nova,
lo que verifica que la
pendiente es igual,
hacerlo distinto, 0, si la pendiente
fuera igual a 0,
no tiene sentido analizar los
residuos de acuerdo,
luego primero si la pendiente
distinta observar ese sentido
y después la construcción
de los residuos
depende de la estimación de aire,
por eso primero hacemos
la estimación, contactamos
la pendiente
y una vez que tenemos eso, vamos
a hacer la verificación
de las suposiciones iniciales
mediante esos residuos hará comentar
en el esquema de trabajo como
simplemente a todos,
y ya no solamente nos queda el
último apartado que posiblemente
sea el más importante puesto
que comenzó el principio,
que la, el análisis de regresión
lineal simple se hace siempre
con un objetivo que es establecer un
modelo que me permite predecir
el valor de la variable en
función de la variable.
Bien, entonces la situación que
vamos a abordar en este último apartado
en general, y de acuerdo al modelo
de regresión lineal
vuelvo a repetirlo, dado un valor de
la variable que está prefijada.
Antemano, nosotros tenemos asociada
una población de valores,
de una variable y que es la variable.
La respuesta y de acuerdo al modelo
de regresión lineal,
siempre en lo que estamos asumiendo,
es que esa variable se
comporta de acuerdo
a una institución normal, con una
media que depende linealmente
del valor de una bonanza
sin más cuadrado,
que lo que ocurre, que ni conocemos
el valor real ni debe,
y aunque el modelo y las
suposiciones iniciales,
cuando fijó un valor de
la única información
que tendrían real de la ley,
es que se comporta como una
distribución normal,
pero desconocemos sus parámetros.
Entonces la cuestión ahora
es la siguiente.
Voy a poder fijado un valor
de la variable
que voy a poder obtener información
de alguna forma de la variable
asociado a esa variable,
respuesta a ese valor,
que la respuesta es que si podemos
hacerlo de otra forma, primero,
que la variable y tiene media ama
y es muy sencillo, ve que
la recta de regresión,
en el punto de que es
un estimado grado
de la media de la variable
y asociada,
así que fija un valor de acuerdo yo
si cálculo, la recta de reducciones,
ese punto de que estoy estimando
la media de los valores
y de la respuesta asociada a ese
valor y no solamente eso,
también voy a poder construir
un intervalo de confianza
para ese valor ama, así que
el panorama desconocido,
pero lo puedo tanto estimar
puntualmente un estimado,
dado que la recta regresión
en el punto,
ir como con un intervalo de confianza
como el que aparece en esta
transparencia fijado,
que aquí aparece en la
recta de regresión,
aparece un término después explicar
que quiere y después ya estadístico,
muestran que dependen de la variable.
Pero no solamente eso, sino que voy
a poder hacer algo que todavía más
interesante, que es dar un intervalo
el cual con una probabilidad
prefijada de antemano sé
que voy a poder encontrar el
valor de la variable,
fijaron que conectó lo único, que
estoy haciendo, obtener una idea
de cómo se comporta en promedio
la variable ley,
pero a mí seguramente lo que más
me va a importar decir.
Bueno.
Y cuánto va a valer la variable y
respuestas para ese valor que bien
pues eso puede hacer a través
de lo que se conocen
como intervalos de predicción,
que son distintos
de los intervalos de confianza.
El intervalo de predicción
en general es un intervalo
de extremos aleatorios
que depende de una palabra,
muestra de tal forma
que la probabilidad de
que ese intervalo
contenga el valor de otra variable
vamos a llamar ley,
estén prefijado de antemano, de
tal forma que yo puedo fijar
que la probabilidad de
que lo contenga
sea del 95 por 100 o del 99 por 100.
Eso es lo que me dice
que cuando yo tenga un intervalo
de estos de predicción
con una probabilidad bastante grande,
el valor de la ley va a estar
dentro de ese intervalo.
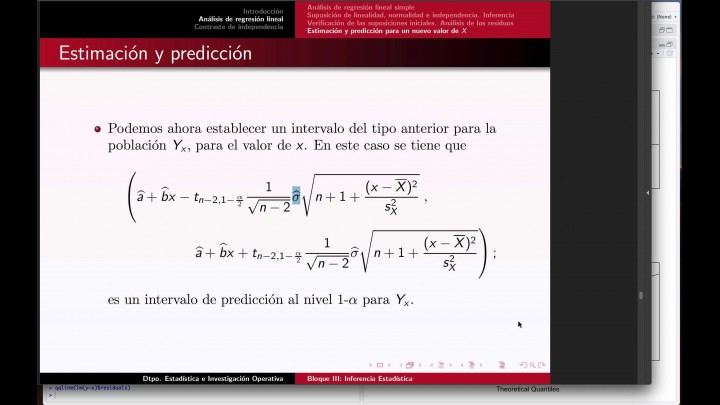
Bien, pues nosotros podemos
construir.
En el análisis de regresión
línea simple,
un intervalo como el que aparece aquí
donde intervalo contiene con
probabilidad uno menos Alfa
-el valor de la variable
y asociada a un nuevo valor
claro que este valor,
que lo fijó dos tres 4,
como éramos los ensartamos en
la fórmula y en la fórmula
necesito pues las estimaciones
de la estimación,
debe una serie de valore
crítico que se una
a través de de nuevo parecer
estadístico sin gorro,
y después de que dependen
de los valores
y recordar la interpretación
de intervalo
es que con una probabilidad de
100 por unas menos alfa
se encuentra el valor social
de la variable respuesta
y el cuerpo.
Bueno, vamos a hacer un
ejemplo con el orden
de este tipo de intervalo,
con el caso de.
Estamos considerando nuestro ejemplo
recordar que aquí lo que se analizaba
en las concentraciones de plomo que
habían en unas aguas residuales,
lo que se quería ver como variable,
respuesta, la concentración de plomo
residual que quedaba en el terreno.
Nosotros analizamos el
modelo estoy viendo.
Los valores de la recta de regresión
y ahora la cuestión
es si yo tuviera un nuevo valor,
por ejemplo equis,
igualado podría decir cómo se
van a comportar los valores
de ley sin necesidad de observarlo
o si tengo el valor igual
podría saber cómo son los valores
de el residuo de plomo
que quedan en el terreno sin
necesidad de observarlo.
Si lo hemos hecho hemos visto ante
el intervalo de confianza
de predicción.
Entonces,
cómo se genera ese intervalo de
confianza y de predicción en?
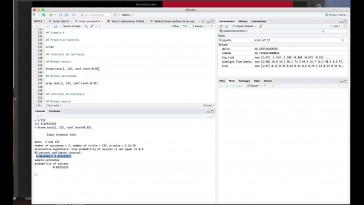
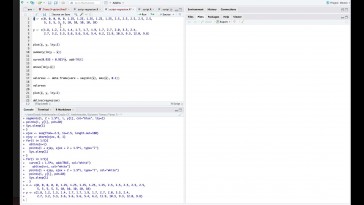
Se calculan de la siguiente forma.
Primero tenemos que generar un
vector donde van a estar los nuevos valores
de y para los cuales quiero hacer
los intervalos de confianza
y de predicción.
Aquí una cuestión muy importante
es que el argumento principal
que yo tengo que poner es el vector
de nuevos valores del equipo,
y fijaron que tengo que poner
como equipo como nombre
de ese lector.
De acuerdo, el nombre de la
variable de partida,
el nombre que le había puesto
al vector de datos
para la variable que lo tenéis
que repetir aquí.
Me acuerdo, bueno pues una vez que ya
había dicho quiero intervalo de
confianza y de predicción
para que igualado igual
aquí podéis poner
todos los valores que Teherán podría.
Simplemente con esta instrucción
generamos el intervalo de confianza
fijaron como tengo dos valores
posible que me genera
dos intervalos de confianza.
El primer intervalo de confianza
es éste y el segundo intervalo
de confianza es este y recordar
estos intervalos.
Lo que me dicen es.
En promedio, cómo se va a
comportar la variable.
Esos intervalos de confianza son
para la media de la variable
y luego la media de la residuo
de plomo que va
a quedar en el terreno bastante
2, 58 tres puntos igualados,
y entre 56 4, 12, para
igualar el hecho
de que el intervalo sea de confianza,
porque aquí ponemos en el argumento
que el intervalo es de confianza.
Claro que en este argumento ponemos
el nivel de confianza
y aquí tenemos que indicar
que estamos trabajando
con el modelo lineal que
relacione la variable
y con la variable aquí y eso
se especifica tal cual
está aquí y aquí lo que
estamos especificando
es el vector de datos para
cualquier calcularlo,
y ahora sí yo lo que quiero hacer es
calcular el intervalo de predicción
este argumento.
Lo cambiamos por este, donde
ponemos predicción,
y podemos cambiar también
el nivel de confianza,
así que si lo calculamos aquí de
nuevo tenemos dos intervalo,
y este y ahora recordar que
lo que estamos haciendo
con este intervalo es decir
dónde va a estar
el valor del residuo en el terreno.
Cuando la concentración en el agua
e igualados entonces una
probabilidad muy grande,
el valor que observe de residuos
de plomo en el terreno,
bastan entre un 47 cuatro con 31,
si hay igualdad entre con
una probabilidad
del 99 por 199 va a estar entre
2, 43 cinco puntos 25.
Me acuerdo ahora volveremos
sobre el ejemplo,
pero quiero volver ahora mismo
a la teoría que maneja bien.
Pues bien, diría aquí quería hacer
una serie de observaciones
sobre esos intervalos fijados
por una fórmula
con la que hemos construido
en el intervalo.
Todo ese intervalo de confianza
están centrados en el valor
de la reducción,
en ese valor de lo que son de
la forma requisó equis,
más o menos una misma cantidad
en un caso y en otra.
Luego todo excepto intervalo
que ha centrado
sobre la recta regresión
adicionalmente tenemos dos términos,
tenemos dos términos aquí y es
todo menos si os fijáis
este valor de lo que coinciden,
este valor,
que después lo analizaremos,
coincide con este aquí abajo y aquí abajo,
que era la en otros casos.
Cuál es la diferencia entre un
caso y otro este término,
y si comparamos otros términos
fijaron que esos dos términos
están claramente ordenado,
puesto que lo que hago es,
en este primer término,
sumarle dentro y luego el temen.
Es tradicional, que aparece en
el intervalo de predicción
hace que sea el intervalo
de precio más grande
que el intervalo de confianza.
El intervalo de predicción
siempre es más grande
que el intervalo de confianza
para la media.
Dado cuenta que esto es lógico.
Por qué?
Porque el intervalo de confianza
lo único que pretende
es dar un intervalo para cazar,
un único valor que en la media
de la variable ley
y con el intervalo de predicciones
estamos construyendo un intervalo
que pretende caza los posibles
valores de la variable
y, pero, claro, la variable
puede tomar mucho valor,
mientras que la media es
solamente un valor
o con conectó en mente los
intervalos de confianza de predicción,
son siempre más grandes
que los de confianza.
Eso lo veremos en el ejemplo.
Bien.
Otras formaciones importante es que
las expresiones que hemos visto
en los extremos de acuerdo resulta
que aparece un término,
que es quien menos se parra cuadrado,
así que cuanto más cerca
esté barra es decir.
Cuanto más cerca del valor de la
variable de la media muestra
más estrecho va a ser el intervalo
recuperó otra vez
la expresión, por ejemplo,
en transparencia,
que aparece este término y, por
lo tanto, cuanto más cerca
este término se vaya haciendo
cada vez más pequeños.
Cuanto más me separe el intervalo
se va haciendo más grande,
lo que estoy haciendo ahora
es analizar de qué factores va
dependiendo el intervalo
y cómo afectan a la forma
de entonces.
Hemos dicho cosas.
Por un lado, es que te va
a hacer en general,
tanto para mi confianza
como mi predicción,
que cuanto más cerca de la
media más pequeñitos
y cuanto más lejos, más grande y,
por otro lado de predicción,
siempre más grande que
el de confianza.
Bien, otra expresión u otra
cosa más importante,
los intervalos de confianza y de
predicción se hace más pequeño
cuando el coeficiente de
terminaciones de se hace más grande.
Por qué?
La moción en la silla hemos
visto anteriormente
en los intervalos que aparece
un término sin más gorro,
le vamos a recordar otra vez ahorro
que multiplica estos términos,
que son los que se suman y se restan
para generar los extremos
inferior y superior barcos.
Ese término que en un principio
no habíamos visto hasta
el momento se calcula
como la Cuadra positiva del cociente
entre la suma de Ecuador residual,
y de hecho no le hemos mencionado
en la momento,
pero no hemos detallado nunca
terminó si lo vais al cuadrado,
es un estimado y se acabó la
apariencia que desconocida.
Luego aquí lo que está en juego
es la apariencia del modelo.
Este término sin estima el valor
de signo y ahora fijado,
que como depende de la suma
de Ecuador residual,
va a tener alguna relación directa
con el comportamiento de.
Porque si recordar el valor
de voy a volver aquí
ha recordado título.
Si volvemos al que sienten cuadrado
cociente entre la suma de regresión
que la suma de cuadrados
total y todo terminó.
Aparecía la descomposición
de la variabilidad.
Iremos de aquí.
Entonces el cociente entre
este término,
aquí y ahora la red cuadrado
de este término
partido por él, es el
término sin magos.
Entonces si el coeficiente de
determinaciones grande
del orden del 90 por 100 de cero
con nueve o superior,
eso quiere decir que este término
y este término son muy parecido
que le va a ocurrir,
ha terminado aquí
porque se va a hacer muy pequeño,
puesto que se terminó fijar.
Ese término, ese cierres,
es el que se utiliza para calcular
consciente terminaciones grande,
lo que tendremos que tener menos.
Se va a hacer pequeño
y, como está multiplicando recordar
en la fórmula que estaba manejando,
como está multiplicando a este
trozo lo que se sumen,
se recta el hecho de que
sea pequeño va a hacer
que el intervalo de predicción
de predicción
o el de confianza se
haga más pequeña,
y entonces aquí donde
tenemos una prueba
de cómo afecta el coeficiente
de determinación a la hora
de utilizar el modelo de predicción,
dijimos sí ha cuadrado
grande el modelo.
Bueno, para predecir cómo se nota
que efectivamente el modelo es bueno
para predecir, porque ahora,
cuando voy a calcular intervalo
de confianza de predicción,
si a recuadro grande el intervalo
se hace pequeño fijaron
que el hecho de que el intervalo
de predicción
por ejemplo sea pequeño, quiere
decir que el modelo es bueno, de acuerdo,
porque si yo, para predecir
un intervalo
doy un intervalo de amplitud
yo sé 200, 300ó 400,
pues evidentemente eso tampoco me
da mucha precisión el hecho
de que sea pequeña me
da más precisión
a la hora de estimar el posible
valor de la variable ya entonces,
lo siguiente que tenemos
que tener en cuenta
es que el cociente, determinación
afecta
al cálculo integral de conciencia
y predicción
haciéndolos más pequeños.
Conforme ha recordado, se hace
cada vez más grande.
Y eso es lo que tenía aquí
completa de acuerdo
y por último lo que también
quería señala
es que la técnica de estimaciones
de predicción solo
es válida para el recorrido
de los valores de donde
el modelo lineal es válido si es
nuestro ejemplo hemos visto
que el recorrido va a ser a
10 yo no pueda extrapolar
y utilizar intervalo de predicción
para valores de igual a 20
porque ahí no he hecho un análisis
del modelo y no sé si se verifica
que sigue valiendo la linealidad
que aparece aquí
con todo lo que lleva aparejado
el modelo recuerdo bueno
pues lo que vamos a hacer va a ser
construir esos intervalos
de predicción y de confianza
para los distintos balones
y que veáis algunas de las
observaciones que hemos dicho
anteriormente en un ejemplo concreto,
por ejemplo con los datos de las
concentraciones de plomo
que construyó el intervalo
de confianza,
que están en azul y lo intervalo
de expedición
para todos los posibles
valores de Bale.
Lo primero que vemos en lo que
hemos dicho anteriormente,
que de confianza son más pequeñas
que los intervalos de predicción.
Lo hemos dicho ante el intervalo
de confianza.
Pretende capturar el valor de Amat
y el intervalo de predicción
pretende calculan
todos los posibles valores
del acuerdo,
aunque no se aprecia mucho
para esto intervalo,
hacen con una curva de acuerdo
a una curva de este estilo.
No se aprecia mucho el punto donde
más se estrecha en el intervalo
el punto de la media montaña
que dicho anteriormente,
que era donde se hacía más
pequeños el intervalo
y entonces la forma en que se
utilice lo que hemos dicho antes.
Yo aquí cojo un valor de que
ya tengo entre que posible
para que la respuesta
y el posible valor
de pactar la media de la respuesta
y además está esta gráfica
se puede utilizar de forma
inversa, por ejemplo,
imaginar que qué legislación,
el máximo de concentración
residual de plomo,
que tiene el terreno de yo puedo
utilizar esta gráfica venirme aquí
y ver para qué valor
de que se alcanza
ese máximo de concentración residual
que yo puedo tener.
Recuerdo así que cuanto yo
tenga un agua residual
que esté por encima de
este buen orden
y ya sé que tengo posibilidades
de usar valores
por encima de lo que dispone
la legalidad
y tendría que evitar ese tipo
de concentraciones de plomo
en las aguas que.
Entonces con esto terminamos
toda la parte de regresión
y simplemente me queda ahora
ver el esquema de trabajo
que tenemos dentro de la redacción.
Bien, entonces el esquema de trabajo,
que tenemos que centrar,
regresión lineal,
va a ser aquí nosotros, partiremos
de nuestro modelo,
partiremos de nuestro conjunto,
y subí y subí
y lo primero que haremos será
obtener las estimaciones de bme
mediante cuadrado,
dando lugar a lo que hemos llamado
la recta de regresión.
Sobre una vez que tengamos
esa estimación,
nosotros lo que hacemos
en nuestra tabla
no va donde vamos a descomponer la
habilidad de ahí en función
de la relación lineal con él
y del residuo Epsilon
y eso nos va a servir,
en primer lugar,
para contactar si la pendiente del
modelo es igual, hacerlo distinto
si la pendiente del modelo igual
a cero no es relación lineal,
y nuestro problema se acaba ahora,
si tenemos que la pendiente
es distinta,
pero nuestro paso siguiente es ver
si el modelo para predecir el valor
de si el valor de recuerdo superior
a hacer un nuevo modelo es bueno.
Entonces, lo que hacemos es
verificar las suposiciones iniciales
mediante el análisis de los residuos.
Por un lado, recuerda,
tenemos que utilizar la gráfica de
los puntos, algo y su vigor
y por otro lado, hacemos la gráfica
de de los residuos.
Si tanto en el examen
como los ejercicios simplemente
quiero que comen,
cómo conservar los valores, y ya una
vez que tenga ese eso comentado,
pasaré al último punto que
si se os pide podréis,
hacer estimaciones de predicción
para un nuevo valor
de la donde recordar quedado
un nuevo valor de poder,
por un lado, a través de
estimación puntual
o de intervalo de confianza,
dar una aproximación de la variable
de la media de la ley
y por otro lado, el intervalo
de predicción
podéis dar una aproximación de
la variable en general.
Soy consciente de determinación,
es menor que cero con 9.
Esta relación lineal no es
suficientemente buena
para predecir los valores de
ahí y no nos preocupamos
de la verificación de las
suposiciones iniciales
mediante el análisis de los residuos
o de la estimación en la predicción.
Desde el punto de vista práctico
aún así en los ejercicios,
se conciencie, determinación,
sale menor que cero nuevo,
seguiremos trabajando en dos
cosas o para aclarar
algún ejercicio de prácticas en
el análisis de los residuos
y en la estimación en prevención
para no valorar, pero eso
sí desde el punto de vista práctico
no tendría sentido.
De hecho,
si en algún ejemplo sale
que ha recordado
cómo estos intervalos son muy malo,
es decir, son intervalo muy grande y
no nos va a servir prácticamente
para decir nada con precisión.
Sobre la variable, bueno, pues
con este sistema de trabajo
cerramos el análisis de
regresión lineal
y cerramos los contenidos
de la asignatura.
Recordar que hay dos apartado que
no vamos a ver a una lesión
o subir el material escrito para
que lo puede consultar
en cursos posteriores nada conectó
lo dejamos aquí y ya no vemos
en las próximas sesiones
de videoconferencia,
un saludo y cuidar mucho.