Idioma:
Español
Fecha:
Subida:
2022-09-29T00:00:00+02:00
Duración:
34m 39s
Lugar:
Videotutoriales
Visitas:
810 visitas
Formación
Descripción
02:10 Introducción al enriquecimiento de datos
02:10 Explicación de fuentes externas
02:10 Configuración de fuentes adicionales
06:00 Flujo de obtención de datos
08:10 Fuentes externas adicionales
08:30 FigShare
08:30 GitHub
09:30 Matching
10:45 MESH
10:45 SNOMED
12:20 Configuración de fuentes externas adicionales
13:50 Validaciones
15:00 Envío a producción científica (PRC)
17:30 Petición de borrado de producción científica
22:20 Exportación de CVN
22:40 Opciones
22:45 Idioma
23:10 Tipos
23:30 Versión
28:00 Perfiles de usuario
25:30 Secciones
24:00 Estado del CVN generado
24:00 Procesado, Pendiente, Error
02:10 Explicación de fuentes externas
02:10 Configuración de fuentes adicionales
06:00 Flujo de obtención de datos
08:10 Fuentes externas adicionales
08:30 FigShare
08:30 GitHub
09:30 Matching
10:45 MESH
10:45 SNOMED
12:20 Configuración de fuentes externas adicionales
13:50 Validaciones
15:00 Envío a producción científica (PRC)
17:30 Petición de borrado de producción científica
22:20 Exportación de CVN
22:40 Opciones
22:45 Idioma
23:10 Tipos
23:30 Versión
28:00 Perfiles de usuario
25:30 Secciones
24:00 Estado del CVN generado
24:00 Procesado, Pendiente, Error
Transcripción (generada automáticamente)
Pantalla.
Quiero asegurarme de que
está agravando esto.
Si vas, vamos a empezar.
Bienvenidos a la formación
del día 28,
formación para investigadores en
la que yo mi compañero Manuel
vamos a explicar el proceso de
enriquecimiento de datos
y el proceso de validaciones
y de exportación.
Aquí tenemos poco, les quema
vamos a seguir primero
hago una pequeña introducción
explicando las fuentes externas,
el flujo y la configura una adicción,
aunque hay posteriormente poco más
en detalle las 2 fuentes externas
adicionales en las que el usuario
puede configurar
las y explicar el proceso de Machín
que tenemos, con, ves y es.
Noveno, después pasaré al
tema de validaciones.
El envío de publicaciones
a producción científica
y la petición de borrado de
publicaciones de científica.
Por mi compañero Manuel explicará
la exportación,
los 2 tipos de opciones que
hay como idioma tipos
diversión los perfiles de usuario.
Seleccione el estado del
procesarlo pendiente
y finalmente, contestaremos
a las preguntas
surgidas durante la formación.
Sé.
Para él, como como vio, como
hemos visto en el esquema,
voy a empezar explicando
el flujo de datos,
que, que sigue la a fuentes externas,
lo voy a explicar de forma
resumida vale?
Este proceso.
Hay principalmente sus procesos
para cargar los datos de
fuentes externas,
la obtención de los datos en sí y
después la carga para obtener
los datos de fuentes externas.
Las fuentes principales son Open Aire
vale sobre estas 3 se tiene
prioridad en este orden,
vale y tiene prioridad
frente a las copos
y tiene prioridad.
Prudencia Open Aire.
Me explico.
Por ejemplo,
si obtenemos una misma publicación
de estas 3 fuentes externas
supongamos que es una aplicación
porque tienen 1 o 2,
pero el título cambia entre
las 3 vale y hay
un pequeño cambio de ciclo,
y en este caso,
como unimos la información
de las 3 fuentes,
tenemos que dar prioridad en alguna,
porque el título es distinto
entre entre las 3 fuentes,
con lo cual en ese caso se
daría debía primero,
frente al resto de las 2, si viniese
únicamente de 2 puentes,
por ejemplo esta y la de Enaire
se daría prioridad.
Agradezco, Hanescu y si ópera eso
daría prioridad a la de Mahler.
Según el análisis de fuentes
externas realizado para el proyecto,
la fuente más completa y
su sable y yo penales,
el desarrollo de estos datos se
ha hecho mediante servicios.
Cada fuente tiene un servicio
específico
en el que se hace una petición
al API para pedir la;
después hay un servicio que engloba
todos estos micros,
servicios que hace peticiones
a cada 1 de los servicios.
Para obtener estos datos,
para después ocultar la información
fichero Hotasa vale a la vez,
aparte de hacer peticiones
mediante Lorquí
para estas 3 partes principales,
también se hacen peticiones
a 2 fuentes secundarias
mediante el dueño de la publicación.
Esta fuente secundaria son
semántica escolar
y, si no utilizamos Pantic escolar
para obtener las biografías
de la publicación y este nodo, por
si hay algún archivo adjunto,
como el de la publicación a estos
datos no podemos obtener
los de las 3 fuentes primarias.
Tenemos un pequeño ejemplo de la
bibliografía que obtenemos.
De una publicación vale que
obtenemos el doy la URL del año;
el título, la revista y
los autores de Smack,
expone y finalmente, pues eso,
hacemos una petición accionado
mediante.
Doy para mirar si hay algún
documento adjunto.
Finalmente, cuando ya tenemos
todos los datos,
si completadas entre ellos,
hacemos el enriquecimiento de
escriptores temáticos,
típicos enviamos el título,
la descripción y el PDC.
Si tiene, y con esto, nos nos
enriquece la publicación
y nos devuelve etiquetas, con
un porcentaje de acierto,
vale entre 0 1.
Las categorías que está
la publicación
de las categorías en ciudades de
la publicación que se adecuan
al que se utiliza.
Aquí tenemos un del flujo,
vale el investigador, empezamos
con el investigador,
vale.
Quienes es como se hacen
las peticiones
a las fuentes primarias es
importante que sea único vale,
y que el investigador
en estas fuentes
tenga el mismo Urquidi y esté
todo bien, unificado,
o las cuentas de las 3 puentes
vale, pero un caos,
por lo que obtenemos los datos
de las publicaciones vale,
y posteriormente, por cada
publicación obtenida
o preguntamos a tatuarse
ni hacer nada
para enriquecer los datos
de la publicación.
Finalmente, cuando ya tenemos
las publicaciones,
con todos los datos,
pasamos el proceso de
enriquecimiento de escritores
y ya generamos otras.
Son resultante para cargarlo,
vale el proceso de carga,
no lo voy a explicar en detalle,
pero para que lo sepáis servido.
Hay un directorio en el que
se guarda el fichero
y otras son con todos los datos y
por detrás tenemos un buen servicio
que va leyendo cara a cara cada
vez que entra un fichero
el vuelvo lo leí lo avale
el proceso de carga,
pues va a cargar las publicaciones
y se va a aplicar otro proceso
de vale para evitar duplicados
de personas y publicaciones.
Se utiliza umbral para cada
propiedad, vale,
y si consideramos que la publicación
supera este umbral,
pues es decir, vimos que,
como digo, esto ya creo
que se en una formulación anterior,
lo cual no entrar en mucho detalle,
vale, pues este sería procesado.
El flujo general de la obtención
de datos por fuentes externas,
después posteriormente el usuario
también tiene acceso a,
puede configurar fuentes
externas adicionales,
aparte de las que ya de
las 3 principales
y las que se usa vale?
Por ejemplo, aquí tenemos la página
de configuración que se hace
desde el nuevo lateral.
Aquí hay algo de configuración vale,
y aquí el usuario, si tienes,
por ejemplo,
cuenta si sale y tiene ahí
artículos o reos,
introduciendo el identificado
de la cuenta
y la sociedad a la cuenta, se pueden
obtener datos de esta.
Cuánto vale?
Hay que decir que los tops que
toquen tiene restricciones?
Vale?
El usuario tiene que ser consciente
de las restricciones que
tiene cada toque,
creo recordar que el tenía
restricción de tiempo,
es decir, cara el tiempo
se expira y aquí crear
1 nuevo vale, y simplemente sirve
para el número de peticiones
realizadas,
para obtener la información.
Adicionalmente,
aquí mostramos los ideales que tiene
el usuario vinculado vale,
y aquí tenemos apartado que voy
a explicar qué quiere ser más
el proceso que se hace por
detrás molemos aquí?
El bache es un proceso de pareo,
de etiquetas similares,
de ámbito médico y se hace sobre
las fuentes del mes.
Qué quiere decir esto?
Pues que todas las publicaciones
que pertenezcan
a la categoría de medicina que
tenga el investigador,
si le marcamos que quiere el proceso
de Machi por detrás,
lo que va a hacer es
preguntar a Messi,
por el nombre de la de las etiquetas.
Tras la publicación iba a
enriquecer estos datos.
Después tenemos un montón de guardar
que al pulsar se guardan
estos cambios
y si y posteriormente se se hubo,
preguntan por estas fuentes con un
proceso que hay por detrás,
que, como he dicho antes, se
ha encargado de comprobar
si alguno de los usuarios
tiene algún dato.
Es bueno el proceso de Machi,
el básicamente lo que
lo que nos permite
que, por ejemplo, esta
publicación vale?
Este ámbito médico vale?
Como podemos ver aquí las etiquetas
es el único bonito
en el que nos muestra el enlace
directo a Messi no le vale,
no podemos ver las etiquetas que se
hayan recuperado por el máximo,
vuelva a salir este bonito,
tengo otro ejemplo,
vale exactamente lo mismo.
Si pensamos.
Sobre los 2 enlaces, vale,
pues no dije,
por ejemplo, yo aquí tengo un
ejemplo abierto, estable,
pues aquí alguien se redirige
al apartado,
no me vale, y aquí al
apartado de Luis,
después el usuario puede ver
las cosas vinculadas etc.
Por detrás, a su vez, si logra
reconocer la etiqueta,
también guardamos toda todos
los conceptos asociados,
por si después se quiere hacer
una posible explotación,
va explicado, y también faltaría,
la opción de flujo, vale, y los
datos se cargan de 2 maneras.
Una vez generado otra zona
inste por detrás.
Como ha explicado antes,
tenemos un proceso
de qué va leyendo un directorio, iba
perdamos estos y este proceso.
Pues lo hace cara cada equis tiempo,
pero creo que pasa si el usuario
quiere obtener los datos
de fuentes externas
y no quiere esperar a este proceso,
que está por detrás,
que se carga cara cada equis tiempo,
pues le hemos ofrecido la opción de.
Aquí a no lateral siempre aquí
en recupera publicaciones
y erróneos.
Si el usuario usa aquí
lo que va a hacer
es que el usuario va a
mandar una petición
que quiere recuperar todas
las publicaciones y reos
vinculados al Lorquí.
Vale?
Ya los datos que están aquí
y los va a cargar en ese
mismo instante,
vale?
Entonces puede tardar un poquillo,
pero los datos,
pero no tienen que esperar
al proceso que tenemos.
Detrás de ir cargando los datos
cada equis tiempo,
esto es útil.
Por ejemplo, si el usuario sabe que
ha publicado una publicación en.
Y no quiere esperar a este proceso?
Pues simplemente le daríamos aquí y
si tiene vinculado a la cuenta
de si es como si la publicación
pertenece al mismo,
pues lo recupera para explicar
un poquito de todo el flujo
y las diversas fuentes externas
adicionales.
Voy a pasar al apartado
de validaciones,
como ya hemos visto en formaciones
anteriores
en el apartado de actividad.
Y publicaciones vale todas
aquellas publicaciones
que vengan fuentes externas
van a salir
con un bonito de bloqueada
lo vale con esto.
Y cuánto vale esto?
Qué quiere decir?
Pues que no son de que no todos
los campos son evitables.
Vale.
En el caso de que venga una
publicación por fuentes externas
y hay algún dato erróneo, habría
que ir a la fuente externa
donde esté la publicación
y corregir ese dato.
El proceso por detrás reconocerá
que ha habido una modificación
en esta publicación y a la siguiente
que fuentes externas la atrae
y la iba a modificar los datos
que ya había encargados
en nuestra base de datos
y lo va a corregir.
A su vez, aparte de las publicaciones
que vienen bloqueadas por
fuentes externas,
también pueden estar validadas
o les vale para hacer esto?
Vamos a construir un proceso
de validación.
El flujo es el siguiente.
El usuario supongamos que tiene
una ubicación cargada,
que no está bien, que no viene
de fuentes externas
y que la quiere validar, ya
que sabe que es correcta.
Por ejemplo, pues, una publicación
que venga de Google,
pues el usuario, la mandaría
a Vale y.
Tendrá que aceptar la validación
y cargarla,
y después cuando preguntemos
por la publicación
ya vendría batida el proceso,
esté como sea pues aquí tengo una
prueba termina muy escrito,
pero no pasa nada, vale el usuario.
Lo que tendría que hacer sería pulsa.
Sobre los 3 montoncitos.
Vale.
Y enviar a producción científica.
Como dicho este proceso.
Lo que va a hacer va a
ser enviarlo al ese.
Vale?
Aquí se le puede asignar un proyecto
a la publicación.
Vale, ya que las publicaciones
enviadas pueden
estar asociadas a un proyecto.
Vamos a hacer este ejemplo.
Vale?
Y bajamos a abajo del todo
y sobre el botón.
Enviar pulsar entonces que hace por
detrás es coge la publicación
y enviarla al como hemos
visto, salen estos.
Si vale.
Estoy con contento de que estaba
pendiente de validación
y ya que como se ha enviado
no tiene sentido evitar.
Una publicación que ya ha sido
enviada una vez enviada,
en.
Tenéis que ir a hablar, e imaginemos
y que ya sé que la publicación
está ya.
Están bien y él se nos da vida.
Pues esta publicación obligada
no nos va a llegar.
Nos va a llegar.
Cuando volvamos a pedir todas
las publicaciones por él,
pero con la diferencia de
que nos va a llegar ya
con este contento de vanidad
y una vez que la publicación
esté validada,
pues ya no se podría evitar evitar
los campos correspondientes.
Esto es una prueba, pero
hay campos bloqueados
como si bien fuentes externas
para para explicar un poquito el
envío a producción científica.
También tenemos la petición de
borrar la producción científica,
es decir, para aquellas
publicaciones que estén validada
y el usuario decida,
ya que no quieren que esté validada
o que haya algún error
y ya no la quiere
o o simplemente no la quiera
tener como validada,
pues sí pulsado.
Sobre el voto de los 3 bonitos
no va a salir de esta opción
de enviar a abordar, ha identificado
al pulsar sobre ella;
lo que va a hacer es volver a
enviar esta publicación,
pero competición del borrador
me vamos a pulsar, vale,
y lo que es lo que va a
suceder por detrás es
que se le va a llegar una
publicación competición de borrado
y una vez que la acepte la
petición de borrado
ya no va a volver a traer.
Esta va a traer esta publicación,
como no va a mirar y
no le va a salir,
y el editor y finalmente para
terminar un poco con la,
con el apartado de frío,
también se pueden enviar proyectos
externos para que lo validen
para que sea un proyecto para
que sean aceptados
como proyectos de la Universidad.
Aquí tengo una pequeña prueba
la que el usuario tiene
que solicitar una autorización vale.
Cuando les eje, cuando les le
acepte la autorización
por detrás se la va a
asignar al usuario,
vale.
Y, y cuando llega la tecla aceptada,
imaginemos que queremos enviar
este proyecto de prueba.
Vale?
Le va a salir aquí la autorización
aceptarla,
porque simplemente era
el proyecto Oeste?
Le tendríamos que asignan a la
autorización solicitada
y una vez casi nada,
pues aquí te saldría la opción
de enviar proyecto externo,
llegaban a validar la enviaría
el proyecto
y una vez validado el
proyecto externo.
Puede también, como digo,
esta utilización.
Habría que pedir la leche y
el proceso por detrás,
pero ya se le asigna al usuario
y correspondiente,
etc. Vale, pues esto sería un
poquito la explicación de todo.
Haciendo un breve resumen,
simplemente los datos por fuentes
externas tienen 3 fuentes principales
en las que se enriquece con
2 adicionales vale
y después también se
enriquecen con él.
Con el proceso de, con el proceso
de enriquecimiento escritores,
después el usuario tiene la
capacidad de configurar 2
más para obtener reos, vale
y que serán fixa
y, y después tienen la posibilidad
de habilitar el máximo
para aquellas publicaciones que
sean de ámbito médico,
para enriquecer las y,
posteriormente también ha explicado el envío
de críticas sobre publicaciones
que no estén validadas
y el envío de borrarlo.
Producción científica,
también ha explicado
que aquí no está las autorizaciones
para el envío de proyectos
para obligarlos a Vale, vale,
pues ahora vamos a pasar
en el apartado de exportación
del TMB,
le daré el turno a mi
compañero Manuel.
Hielos explicará pues todo lo
relacionado con la exportación.
Vale.
Las escuelas activas puede ser.
Yo voy a continuar, no es bueno.
Voy a continuar con la parte
de exportación de Google,
voy a hacer algún ejemplo inicial y
sobre todo para continuar después
haciendo alguno más para explicar
la parte de la exportación.
Primero, para llegar a la
exportación tenemos que darle al desplegable
de la derecha del usuario y
la parte de exportar CV.
En este caso vamos a ver una pestaña
muy parecida a la importación,
pero con bastantes más datos y
con un apartado de Google
es generados.
Los Google vamos a tener obligación
que ponerles un título.
Podemos seleccionar los diferentes
idiomas que esto,
en el caso de que hayamos
tenido un valor,
la edición, como vimos ayer,
que se podrían añadir sin
seleccionamos el inglés,
por ejemplo.
Vamos a exportar esa información.
Si el valor está vacío,
va a exportar por defecto
el Espanyol.
Los tipos de exportación son
los mismos que es decir.
Vamos a tener la exportación
del CBN normal,
la y también adicionalmente las 2
exportaciones que tengo abreviado,
que serían las de I sí y la vela.
También damos opción a la versión
de exportación, que sería la 1,
4, 0, que es la oficial
que tiene el FECYT,
y la 1, 4, 3, que sería la
que tienen pruebas,
pero que hemos visto que
muchos parámetros
no nos exportan.
En La 1, 4, 0 hemos creído
conveniente añadirla para dar opción
al usuario a algunos apartados
sobre todo de congresos.
También podemos seleccionar
en qué secciones
vamos a querer exportar.
En el caso de que seleccionar todos,
solo tendríamos que añadir.
El título selecciona el idioma,
el tipo de exportación
y la versión que queremos
para el Google
y darle a generar nuevas
aportaciones.
Esto nos va a crear aquí
un bonito proceso que saldrá el
en naranjas con el texto
hasta que el FECYT 2 nos
devuelva al archivo.
En el caso de querer seleccionar
alguno de los valores
o indicar que queremos exportar,
hay que darle a seleccionar,
para entrar a una pantalla
talla siguiente,
en la que veremos cuáles de
ellos podemos exportar
o no, sea cuales queremos sacar,
y también tenemos el botón
de últimos 5 años
que nos va a seleccionar todos
los valores que la fecha
tenga los últimos 5 años.
Vamos a utilizar un ejemplo.
Vamos a seleccionar los
últimos 5 años,
aquí podemos poner nuevos 5.
Vamos a exportarlo en español,
y la versión la vamos
a poner el a 1, 4.
Esto nos lleva a la misma
pestaña de exportación,
que si le hubiéramos a seleccionar
cargaría todos los datos del CMB,
y los los mostraría ahora para poder
elegir cuáles queremos exportar
o no.
En este caso vamos a
tener por defecto
los datos de identificación
seleccionado siempre tanto
en la versión de selección como
la de los últimos 5 años,
y luego, dependiendo de si
tiene o no tiene fecha,
se van a seleccionar o no
se van a seleccionar
automáticamente los, por ejemplo,
los proyectos que están en un período
de menos de 5 años.
Van a estar seleccionados,
pero en el caso
de que haya un proyecto antiguo
no se va a seleccionar.
Si queremos, si el usuario quiere
seleccionar este proyecto,
tiene que ir directamente
y darle esto pasa
con todos los intereses
del currículo.
Por ejemplo,
aquí el grupo está seleccionado,
han pasado más de 5 años
y, por defecto también, los valores,
que son los indicadores generales
de calidad y en resumen libre,
se van a seleccionar automáticamente,
ya que no tienen fecha y
no es posible elegir
si se quiere exportar o no
por los últimos 5 años.
Entendemos que siempre
están actualizados
y, por lo tanto, se exporta.
En caso de no quererlo, habría
que explicar o seleccionar,
para exportarlo.
Por ejemplo, tenemos la parte
del resumen libre,
que sería la selección
del resumen libre,
y la descripción del cuando
hayamos seleccionado,
todos los que queramos, le
daríamos a exportar.
Esto haría ya una petición
para la exportación,
se quedaría en naranja, como he
comentado anteriormente,
y con la opción de pendiente.
Además de la fecha en la que
se ha hecho esta petición,
en el momento en el que se
devuelva el archivo.
Esto cambiará a verde, estoy con
hito y tendremos un enlace
con el que poder descargar
el archivo de Facebook.
Pero pasar a explicar la parte de
perfiles de usuario internos.
En este caso sería para las, para
las opciones de seleccionar
o de los últimos 5 años.
Esto lo que va a hacer es
ayudar a los usuarios,
por ejemplo, crear un perfil de
exportación de únicamente
la situación profesional actual,
por ejemplo, es haríamos,
clic en los sitios que queremos
exportar en la parte del nombre
del perfil.
Un perfil en nuestro caso serían
los datos básicos
y la situación profesional,
lo que hemos llamado situación
profesional,
por ejemplo.
Y le daremos al botón
de guardar esto es.
Lo que haría es que nos
crearía un perfil
para que, cuando volvamos a entrar
en el caso de que esté la selección,
podamos cargarlo directamente y ya
directamente cuando entre en Lieja,
y el perfil para exportar.
Los datos qué haría?
Seleccionar y a todos los sistemas
que estaban seleccionados previamente
en este perfil, en el caso
de querer borrarlo,
habría que darle al botón
de borrar esto.
Nos sacaría un mensaje
de confirmación
y nos lo quitaría de perfil.
Las otras posibles exportaciones
serían las de Google abreviado,
sobre las cuales vamos a tener que
seleccionar siempre los valores,
tanto como de ahí pero no damos pie
a elegir la versión de exportación
y también el vídeo más
sobre los sitios.
En este caso tanto la lista
y como en ambas abreviada vamos a
dar menos datos a seleccionar,
iban a aparecer menos secciones
que de normal.
En este caso no se ve porque tenemos
o consciente descargados en el BOE,
pero aparecen menos secciones,
con menos datos
para poder seleccionar el usuario,
puesto que la versión abreviada
no da, no permite exportar
estos estos gastos o, por ejemplo,
seleccionar estos 2.
Exportarla.
Se nos quedaría igual en pendiente.
Voy a hacer una pequeña prueba
para el inglés.
Para ello me voy a ir a la
dirección del currículo.
Por ejemplo, vamos a exportar
la situación profesional.
Vamos a añadir un dato
extra en inglés,
en este caso a este campo,
al lado que sería la categoría
profesional.
Seleccionando el idioma inglés en
este caso que hemos añadido
un valor extra que sería el proceso
si queremos añadirla
en otro de los idiomas habría
que hacer lo mismo.
Poner el idioma, el valor que
queremos seleccionar
cualquier tipo de exportación
que queramos hacerlo
y entrar dentro de la generación
para seleccionar el en cuestión,
para exportar.
Hemos seleccionado en este caso
el profesor que va a tener los datos.
Van a aparecer en español,
pero cuando los van a estar
en esa versión inglesa.
Vamos a darle a la al botón
de exportado para,
envié la petición para
exportar los datos.
Hemos visto
que algunos de estos han cambiado
de verde naranja
o amarillo y verde.
Este es el primero que hemos hecho
para descargar un archivo pdf,
que sería el del currículum
vitae vamos a tener aquí la sección
del resumen libre.
La parte del jefe del TFM
no se ve representado aquí pero
realmente está almacenada
entonces si volviéramos a importar
quizá en un futuro este,
este PDF sí que se llevaría
esos datos incrustados.
Aquí vemos los datos del
usuario que tenemos
como como datos de identificación
y la experiencia científica
que hemos elegido para exportar.
Serán los temas de los últimos 5
años o que están en ese período.
Sobre el CB abreviado en este caso
la ley nos va a dar un CEO abreviado
con los mismos datos.
Los datos personales,
que es lo que hemos elegido,
el resumen del currículum,
que en este caso está vacío
y luego las aportaciones,
que son los intereses que hemos
seleccionado para exportar.
Inglés y luego, por último, el
CMB exportación en inglés.
Vamos a ver, que aquí ya tienen
los datos en inglés,
tanto por donde se ha generado
como la fecha.
El documento también nos indicaría
la versión de exportación
que hemos tenido, los
datos del usuario,
que te vendrían con la información
en inglés,
además de que la categoría
profesional hemos seleccionado
un dato en inglés,
por lo tanto se profesor
en vez de profesor,
que es lo que estaría el español.
Pero el caso de que hagamos,
por ejemplo,
una exportación de un CB abreviado
si se muchos valores suele ocurrir,
porque no es posible saber cuántas
páginas van a ser
que nos devuelvan un CB.
Entonces aquí abajo te
va a salir un CEOE
-generado con un icono rojo
y una pestaña que te va a poner
un error indicándole
al usuario que nos ha
podido exportar.
No quedaría nada más.
Propietarios
Proyecto Hércules
Comentarios
Nuevo comentario
Serie: Formacion EDMA investigadores (+información)
Canal
presentacion_modified
Relaccionados
Videotutorial de introducción a la aplicación
Videotutorial de expediente de interesado iniciado en el ‘Registro General Auxiliar’
Videotutorial de acciones disponibles
Tests automatizados de accesibilidad de frontend
Resumen de cómo está la UI en Mi campus

Madeja ATICA
Análisis de dependencias de la BD
Impulsar expediente
Charla interna de formación
Desarrollo con DDD y Arquitectura Hexagonal
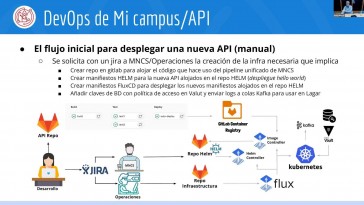
20230329 - Desarrollo Backend en Cloud - Sesión 4
20230322 - Desarrollo Backend en Cloud - Sesión 3

20230315 - Desarrollo Backend en Cloud - Sesión 2

20230308 - Desarrollo Backend en Cloud - Sesión 1