
Canal
Are contemporary Chinese writings and translations more standardized than in the early 20th century?
Jialei Li (Beijing Foreign Studies University)

Jialei Li (Beijing Foreign Studies University)

Leonor Pérez Ruiz (Universidad de Valladolid)

Radoslava Trnavac (University of Belgrade) and Maite Taboada (Simon Fraser University)
Yuan Xiaoshu (Shanghai International Studies University)

Sergio Maruenda y Laura Mercé (IULMA Universitat de València)

Miguel Fuster (IULMA Universitat de València)
Ulrike Oster (Universitat Jaume I)

Carmen Quijada (Universidad de Oviedo)

María de Los Ángeles Criado Alonso, Elena Battaner, Regino Criado, Miguel Romance and David González de la Aleja (Universidad Rey Juan Carlos)

Irene Szumlakowski Morodo (Universidad Complutense de Madrid)

Ignacio Miguel Palacios Martínez and Paloma Núñez Pertejo (Universidad de Santiago de Compostela)

Suhong Hu (Nagoya University)
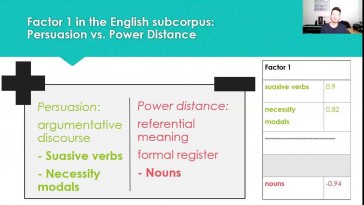
Daniel Granados (Universidad de Murcia)

Chou Mo, Bert Le Bruyn, Martijn van der Klis and Henriëtte de Swart (Utrecht Institute of Linguistics OTS)
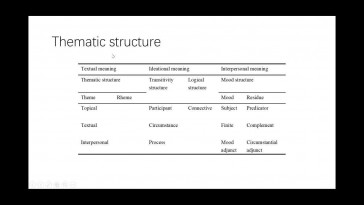
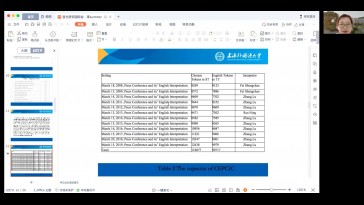
Tingyan Li and Juhong Zhan (Xian Jiaotong University)

Elena Dominguez Romero and Victoria Martin De La Rosa (Universidad Complutense de Madrid)
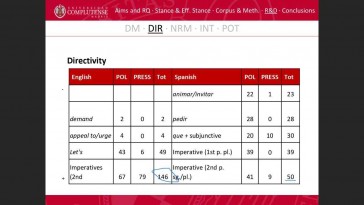
Natalia Mora López y Sergio Ferrer Navas (Universidad Complutense de Madrid)
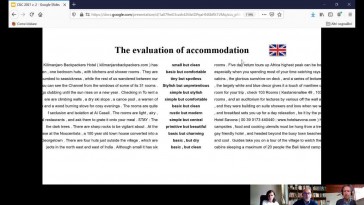
David Finbar Brett (University of Sassari), Antonio Pinna (University of Sassari) and Barbara Loranc (University of Bielsko-Biala)
Para enlazar este video en cualquier página, puede usar esta URL:

Aula Virtual puede incluir de forma automática Videos de TV.UM.ES en el mini-editor HTML (FCKeditor) de cualquier herramienta (Tareas, Exámenes, Anuncios, Recursos, ...).
Para incrustar el vídeo en el mini-editor HTML del Aula Virtual, debe pulsar sobre
el botón "Copiar para pegar" y en el mini-editor HTML del Aula Virtual pulsar en el
botón ![]() o pulsar la combinación de teclas Ctrl+V.
o pulsar la combinación de teclas Ctrl+V.
El video aparecerá directamente como una imagen de resolución , y al hacer click sobre ella, se reproducirá.
Para enlazar con tamaño fijo (click para copiar):
Para enlazar con tamaño dinámico (click para copiar):
Para más información sobre cómo enlazar videos o usar la API, consulte esta página.
En breve.
En breve.