
Canal
Procedimientos metodológicos para la obtención de información sobre L1 en niños/as bilingües (...)
Asier Romero e Irati de Pablo (Universidad del País Vasco / Euskal Herriko Unibertsitatea)
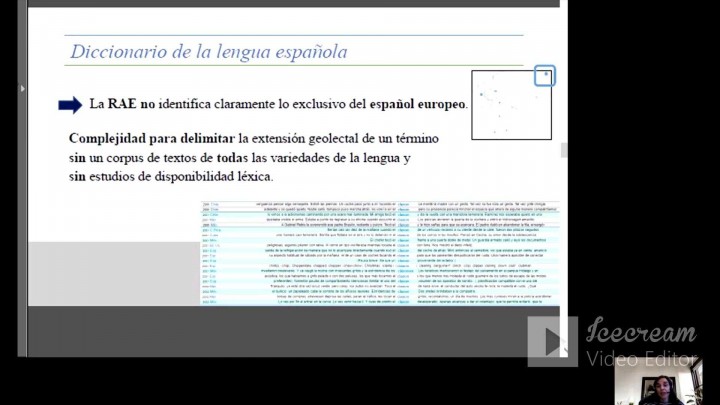
Asier Romero e Irati de Pablo (Universidad del País Vasco / Euskal Herriko Unibertsitatea)

Silvia Sánchez Calderón (Universidad de Educación a Distancia -UNED-)

Xiaolong Lu (University of Arizona)
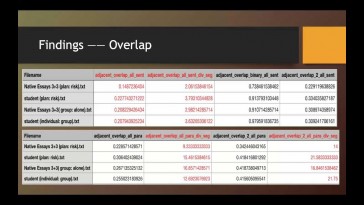
Nan Jiang (Vanderbilt University)

Andrea Listanti (University for Foreigners of Siena), Jacopo Torregrossa (Goethe-Universität Frankfurt) and Liana Tronci (University for Foreigners of Siena)
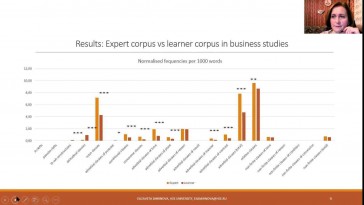
Elizaveta Smirnova (National Research University Higher School of Economic)
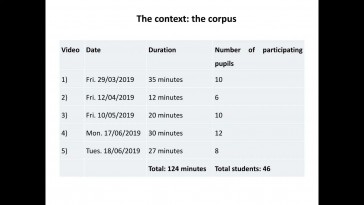
Begoña Clavel Arroitia and Barry Pennock Speck (Universitat de Valencia)

Raquel Mateo Mendaza (Universidad de La Rioja)

Daniel Díez Lorenzo (Universidad de Cantabria)

Miharu Fuyuno (Kyushu University) and Takeshi Saitoh (Kyushu Institute of Technology)
Silvia Aguinaga Echeverria (Universidad de Navarra) and Nausica Marcos Miguel (Denison University)
Francisco Javier Fernández Polo (Universidad de Santiago de Compostela)

Vanessa Cardoso Egrejas (CLUNL) and Antonio Chenoll (Universidade Aberta)
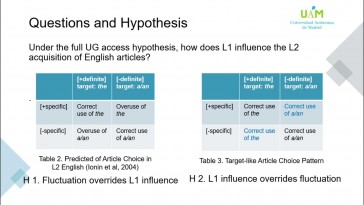
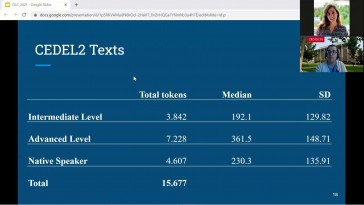
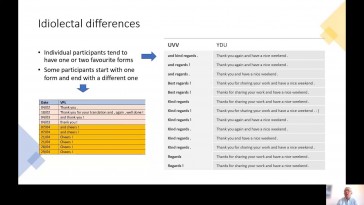
Ting Xu y Amaya Mendikoetxea (Universidad Autónoma de Madrid)

Adrián Granados y Francisco Lorenzo (Universidad Pablo Olavide)

Anita Ferreira (Universidad de Concepción)
Para enlazar este video en cualquier página, puede usar esta URL:

Aula Virtual puede incluir de forma automática Videos de TV.UM.ES en el mini-editor HTML (FCKeditor) de cualquier herramienta (Tareas, Exámenes, Anuncios, Recursos, ...).
Para incrustar el vídeo en el mini-editor HTML del Aula Virtual, debe pulsar sobre
el botón "Copiar para pegar" y en el mini-editor HTML del Aula Virtual pulsar en el
botón ![]() o pulsar la combinación de teclas Ctrl+V.
o pulsar la combinación de teclas Ctrl+V.
El video aparecerá directamente como una imagen de resolución , y al hacer click sobre ella, se reproducirá.
Para enlazar con tamaño fijo (click para copiar):
Para enlazar con tamaño dinámico (click para copiar):
Para más información sobre cómo enlazar videos o usar la API, consulte esta página.
En breve.
En breve.