

Idioma:
Español
Fecha:
Subida:
2021-02-10T00:00:00+01:00
Duración:
41m 08s
Lugar:
Curso
Visitas:
1.210 visitas
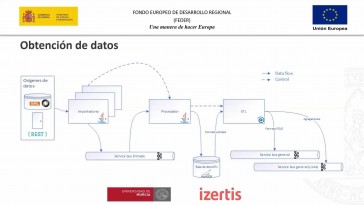
03_Módulos de gestión
Transcripción (generada automáticamente)
Bueno, entonces se nos vamos
a la modelo de gestión
haciendo un resumen de lo que
tenemos hasta ahora.
Digamos que teníamos los
datos incrustados
en el sistema que procedían
de diferentes fuentes,
y ya lo sabemos, ya los
hemos obtenido
y los hemos adaptado al formato
que va a esperar
o que nos está definiendo la
odontología entonces, por tanto,
el sistema de gestión va a ser
el encargado de recoger
los datos en formato cojo, vale
del de la cola de entrada,
así como su segregación
en esos enlaces
que comentaba antes de.
Para los que les vamos
a enviar con ellos,
lo que se hará va a ser utilizar
la librería de descubrimiento,
para validar si se trata
de un nuevo recurso
o, por el contrario, es
una ya existente
que hay que actualizar,
o bien, es necesario realizar algún
tipo de borrado similar
en general.
El rdc también apoyándose
en la factoría de Uriz
y la ingesta del del rbs, en otra,
otra cola del modelo de gestión
que va a permitir luego ya los
procesadores de eventos
y almacenar en los almacenamientos
que sea pertinente no
tengamos necesidad
de almacenarla.
La información.
En cuanto a éste está con la cola
que estamos comentando.
El sistema de sistema de gestión lo
va a utilizar para enviar eventos
hacia el proceso de eventos,
en este caso,
a diferencia de otros
puntos del sistema
que estábamos utilizando, Kafka;
de hecho, estaba previsto usar en
todos los este tipo de colas,
pero vemos que es preciso
en este caso
garantizar un poco el orden de los
datos que nos están llegando.
Entonces, es algo que no nos
que no nos ofrece al final
así es muy,
muy adecuado para una ingesta
masiva de información,
pero no garantiza el orden
de la información,
con lo cual no nos no nos sirve
de todo en este este
puso entonces entonces, en este
punto no vamos a optar a optar por utilizar
una cola al tipo jm y en concreto,
vamos a usar en cuanto a en cuanto a
los procesadores de eventos bueno,
ya lo lo comentaba un poco un poco
antes en la antes del descanso.
Cada uno de estos procesadores
se va a encargar de consumir
los mensajes disponibles en la
cola del modelo de gestión
y enviarlas al almacenamiento
correspondiente la idea es
que exista un procesador de eventos
por cada uno de los diferentes
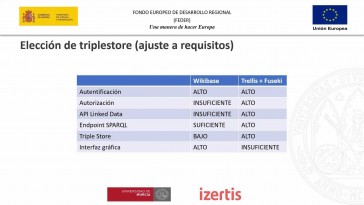
almacenamiento triples por ejemplo
wiki base tres etc
etc de esta forma
como decía es muy pero
que es muy sencillo,
poder añadir.
Tanto.
Tantos almacenamiento es como sea,
como sea pertinente, no le habéis
ahora mismo hay, hay 2,
pero podríamos incluso añadir.
Pues eso, en el caso que quisiéramos
hacer con consultas
de otro tipo, indexación, etc,
etc. Sería sería tan simple
como añadir un nuevo procesador de
eventos, con su correspondiente,
el procesador de eventos no
es que esté especializado
en ningún ningún almacenamiento
en concreto,
simplemente es una nueva
instancia al tener,
al ser, al ser un servicio
como hacía,
podemos desplegar varias instancias
en este caso.
Dijo además, que la diferencia
es que tiene configuración,
diferente, vale.
Por un lado, digamos que el evento
es para lo que va a hacer,
es invocar a la del.
Sin embargo, el de Vicky
va, se va a invocar
a la del sábado 13 wiki bases es.
La única diferencia que van a tener
esas van a ser estándar,
van a ser unificadas, van a
tener la misma de salida,
ambos esto hará savater.
La idea es que todos los sectores,
Savater tengan la misma y luego
internamente se especializó
eso sí ya los en cada uno
de los de los almacenamientos
disponibles.
Entonces también nos nos facilita
por ahí entonces eso los
estos adaptadores,
transformar el error de Fez recibido
para que concuerda
para que se haga el sistema
para sistema final
en el que sea el que sea pertinente
durante el transcurso del proyecto,
como decía, más se van a desarrollar
para traer y para Paraguay,
que no está previsto desarrollar
ninguno, ningún otro.
En este sentido.
Bueno, ya lo comentaba un
poco un poco antes,
estamos haciendo uso del
procesamiento en streaming
para diferentes partes de
toda esta aplicación.
Ya lo vimos también en la parte
de la parte de entrada,
si bien el el punto clave de
procesamiento es en streaming,
estaría dentro de este módulo de
gestión o entre el módulo de entrada
y el modelo de gestión sería
el lado blanco,
la más importante, que vamos a tener,
junto con la de los procesadores
de eventos,
también entonces la idea
es utilizar este,
está esta técnica de timing con
el fin de aumentar la escala,
habilidad y la alta disponibilidad
del sistema,
utilizando flujos de eventos.
Este tipo de sistemas están siendo
utilizados en proyectos
que requieren el procesamiento de
grandes cantidades de datos
y consiste en utilizar un mecanismo
de publicación y suscripción
a un look distribuido.
Deseo la lectura.
La ventaja es que las operaciones
de escritura son más eficientes
que las actualizaciones
en una, en una,
una base de datos, entre
las ventajas,
que luego lo veremos, pero entre
las grandes ventajas
es que totalmente la producción de
la información del consumo,
con lo cual cualquier productor
de información puede
estar gestando datos en el sistema,
pero no tiene por qué estar
esperando a que los procesadores
o quien lo tenga que consumir
termine de procesar.
Cierto dato.
Cada cada uno de estos procesadores,
de estos consumidores, van
a necesitar Copa,
va a utilizar el tiempo que estime
pertinentes sin impactar
en el rendimiento de la ingesta
de la información,
lo cual es una grandísima ventaja
que nos va a aportar este este tipo
de procesamiento, como os decía.
Bueno, hoy en día Kafka
se está utilizando
para la ingesta de datos de múltiple
de múltiples fuentes,
pues de temas de idiotez, temas
de transacciones financieras,
con movilidad logística muy muy
pero que muy utilizada
en ese ámbito, cadenas de ensamblaje.
Bueno, muchísimos, muchísimos
a ámbitos
no del final.
El mundo produce, produce datos
y se está produciendo en todo
momento para poder aprovecharse de ello.
Se necesita definitivo una
plataforma que soporte esa ingesta masiva
de grandes volúmenes de
datos de información.
Es muy importante herramientas,
como, como Kafka, que nos permitan
gestionar este tipo de sistema,
pues, como decía, trabajan
con el patrón,
publicación-suscripción, normalmente
y permiten acoplar la publicación
de los eventos de los de
los consumidores.
Bueno, realmente bueno,
un poco lo que no estábamos
comentando en esas entonces
estas fuentes de datos,
pues los datos a través
de un productor
que acabara escribiendo los datos
en la la, el tópico,
en la cola de Kafka en
cuanto a la parte
de los consumidores, pues bueno,
pues realmente cada podíamos tener
uno o varios consumidores,
todos aquellos que sea
que sea necesario,
que nos vaya, que nos
vaya a hacer falta.
Todos van a estar mediante
una estrategia
de consumiendo de los diferentes
de las diferentes colas.
Vamos a estar leyendo la
información, cada uno va a ir
a su ritmo, no tienen por qué
por qué impactar ninguno.
En otro puede ser que uno esté
tratando el primer,
el primer elemento y otro ya.
Por el elemento número 10
cada cada uno tiene su suposición o
en la que la del último elemento
leído, con lo cual vamos
a poder tener,
como decía tantos tantos
consumidores como como estime necesario
y con su con su velocidad.
Aquí es este ejemplo de esto lo veo,
lo veamos positivas atrás
en la parte de la gestión de eventos
para el almacenamiento.
La diferentes triples que
va a tener el sistema,
el que estamos hablando.
Bueno, ya lo comentábamos antes.
Productores y consumidores
desacoplados;
los consumidores lentos no
van a afectar realmente
a los a los productores.
Una de las grandísimas ventajas
de este tipo de sistemas.
Añadir cuantos consumidores
sea necesario
sin afectar a los productores.
Bueno, aunque no afecte
a los productores
y que podría afectar
a la configuración
de la de la cola Kafka pero bueno
eso sería otro otro sistema otro tema
y no habría que añadir, seguramente
más participaciones
a una cola.
Las cosas se pueden dividir al final
y las participantes podrían
estar distribuidas.
Pero bueno, eso es otro
tema que igual
no, no hace falta entrar tan
al fondo de la cuestión,
lo si hay fallos de algún consumidor,
pues lógicamente no va, no va a
afectar al al conjunto del sistema
o no va a afectar al resto realmente
de consumidores.
Bueno, como decía, estas colas,
pues realmente se denominan
topics valer y un topic,
pues es un tópico topic no deja
de ser una estrella,
una cadena de un flujo de
mensajes relacionados.
No encajamos como veamos.
Después tengo teníamos varios topics
topic del modelo de gestión,
el topic de del modelo
de entrada, etc.
Etc. Entonces, digamos que
cada uno de sus topics
sirve para una fundación finalidad.
Por eso por eso hablamos de
mensajes relacionados.
No deja de ser una representación
lógica
estos tópicos,
pues son definidos por los
desarrolladores más
que por los desarrollados,
por la propia aplicación en sí misma.
No, cada aplicación,
pues va a necesitar una serie de
de toque y, si bien es cierto
que, dependiendo de la configuración
que le queremos al a Kafka,
podría ser necesario crearlos
ya previamente.
En cuanto a la relación
topic productor,
pues vamos a tener una
relación en enero,
podría?
Podríamos estar un mismo producto,
podría estar escribiendo
en diferentes tope,
y si este es uno de los casos
que hablábamos antes,
como en el tema de la tele
-escribíamos en dos tópicos.
Una coloso, objetos sin relaciones,
los objetos planos y otro tópico
con las, con las relaciones,
y ahí también podría ser al revés,
tener varios productores para
parar el mismo tope,
aunque eso podría,
bueno, habría que ver el caso el
caso de Eto o pero bueno
podría por ejemplo el caso de Elliott
al que tengamos varios dispositivos
leyendo información de temperaturas
en diferentes momentos, por ejemplo,
una cadena de frío?
Vale?
Pues todos ellos podrían estar
enviando a la misma la misma cola,
de al mismo tope,
y entonces ahí podríamos ver
ese ese posible y bueno
número de topics y limitado
dentro de evidentemente
la capacidad del sistema
Bale y posibilidad
de dividirlo en partición es que
nos van a permitir hacer,
añadir o eliminar consumidores
para hacer un procesamiento
en paralelo por ejemplo entonces
bueno un poco como cómodo
como decía entendemos esas en este
caso cuatro cuatro participaciones
y tendríamos un un productor que
estaría escribiendo en el topic
y Kafka, después, internamente
de forma transparente,
al productor,
iría asignando a cada partición cada
uno de los de los eventos.
Normalmente es la clave de registro
en la que determina
a qué partición podría ir.
Bueno, realmente digo que es
un poco el que nos lo va,
nos lo va a gestionar.
Las participaciones, como decía
se podría facilitar.
Se podría utilizar para facilitar el
tener consumidores en paralelo
para poder consumirlos?
Hasta el número de partición
es, por ejemplo,
podríamos tener consumidores
distintos consumidores?
Como vemos antes, para
distintas cosas,
y eso es son distintos consumidores?
Vale, son distintas finalidades,
pero un mismo consumidor lo
podríamos tener replicado en veces?
Estoy hablando de este caso
no de tener varias réplicas
para para darle escala,
habilidad a esa a esa parte.
Entonces podríamos tener en este caso
pues, por ejemplo cuatro
consumidores del mismo sistema,
cada uno leyendo de una de las
de las participaciones.
Entonces esa de esa manera podemos
darles a esa flexibilidad
esas esa estaba escala habilidad
para mejorar el rendimiento
del del sistema por culpa
de este tema?
O bueno principalmente es por lo que
es uno de los puntos principales,
por lo que no se garantiza el orden
también no, porque al final
cuando estás leyendo no tienes,
porque exactamente leer en
el orden que te lleva,
porque puede estar leyendo
una partición,
primero un mensaje que ha llegado
después de otro mensaje.
Que estén otra partición que todavía
no has leído, por ejemplo?
No?
Entonces este es uno de
los de los puntos.
Otro de los motivos por los que
no nos garantiza un orden
en este caso.
Entonces básicamente, lo que
es una partición vano,
viene a significar, está esto,
no deja de ser una,
una colección en la que al final
vas escribiendo elementos
o sucesivamente se forma
de forma secuencial,
1, uno tras otro a la paz
que va escribiendo,
como es el caso de la cajita verde.
Vale, podíamos tener varios, varios
consumidores en este caso
como mal caso los cajitas
-azules, vale?
Sería un poco el caso que
como decía antes,
vamos a tener en el procesamiento
de eventos que nosotros vamos
a tener dos ahora mismo no?
Pues aquí vemos como uno de
uno de los sistemas,
el sistema está leyendo a la
el evento número cuatro
mientras que el sistema b va,
va mucho más rápido y ya está
leyendo el número 10,
vale?
Entonces son, es algo que nos va
a facilitar este sistema,
a este sistema para poder
para poder llevarlo,
para poder llevarlo a cabo.
Vale.
Bueno, entonces este esta
forma de trabajar,
este estilo arquitectónico realmente
suele denominarse arquitectura,
vale y suele materializarse
mediante el uso de casco
como como estamos viendo entonces
este uso del casco
a cómo va a permitir utilizar
ese distribuido como fuente
de de verdad.
Desarrollar diferentes vistas
de los mismos datos
ha visto puede ser una base de datos
rdc o índice de búsqueda
como bueno va a permitir
un poco conectarlo.
Hay, si la aplicación productora
de eventos comenzó a fallar,
generando datos incorrectos,
relativamente sencillo modificarlos.
Los consumidores también de eventos
para adquirir los datos erróneos.
Si algo es una base de
datos más al uso,
se se corrompe su restauración.
Podría ser más complicada.
La la la decoración puede
ser más más sencilla
en el ojo de solo escritura;
que una base de datos
que se modifica continuamente,
puesto que los eventos pueden
volver a ejecutarse,
para explicar qué ocurrió una
determinada situación,
es decir, cualquiera podríamos
volver a coger el look.
Decirle que él volverá a hacer
un rol vaca un momento dado
y volverá a acoger todos los eventos
desde un punto en concreto
desde un objeto, desde una cajita.
En concreto,
es decir, por ejemplo, en este caso
podríamos volver a coger
el programa que se ha corrompido,
sistema b, desde totalmente,
pues podríamos decirle: volverá
a hacer una limpieza,
limpiarlo por completo y volver
a aplicar todos los eventos,
diciéndole que empieza a leer
en el cero de nuevo,
con lo cual esto esté este tipo
de arquitectura capa,
pues nos va a facilitar este está
esta situación para volver
a restaurar la, la información.
Bueno, para el modelado de datos,
autorización de un look que
solamente permite añadir datos,
puede ser más más sencillo, que
el uso de transacciones,
así sobre base de datos relacional
y el hermano,
el patrón encaja perfectamente
con esta pasta,
estilo arquitectónico,
también puede facilitar el análisis
del dato de un dato posterior,
es decir, vamos a saber cómo hemos
llegado a una situación
da en concreto después,
ya que podemos analizar
todos los décimos,
cómo hemos llegado a tener, cómo
ha llegado el consumidor,
vaya a tener esto.
Podemos ir viendo desde
desde cómo ha pasado
desde desde el cero hasta el 10 que
que eventos que ha ido sucediendo
en el sistema es muy fácil de
seguir en ese en ese caso
y por supuesto, esto,
el desacoplamiento de la publicación
de los consumidores
como, como decíamos, todo esto
parece repetido de lo que ya hablando.
Pero bueno, estoy relativo a
la arquitectura capa vale,
lo cual encaja perfectamente,
como, como decía, con con
un motor de streaming,
como puede ser, al que Kafka tienen.
Tiene inconvenientes, como
ya he comentado antes
y no está diseñado para garantizar
el orden de los eventos enviados;
habrá casos en los que,
si hace falta,
garantizarlo entonces para ello
vamos a optar por un sistema tipo jm sé
cómo es como vale aquí dicen que
es un bloque de mensajería,
como hacía jm o pensó;
implementa simplemente la
especificación j j meses y además
nos garantiza que preserva el orden
de los de los mensajes enviados,
lo cual es muy, muy importante
como contrapartida,
pues tiene otras implicaciones,
como tiene un mayor consumo de
recursos en el sistema, etc.
Etc. Con j.
M es en concreto,
pues podemos tener la opción de
publicar mensajes a un tópico
o a una cola Bale.
En el caso de Cascos
solamente teníamos la
opción de tópico.
Hay una diferencia fundamental entre
entre las dos puntos de vista
vale que está un poco ilustrado,
aquí está en este esquema un Topic,
reenvía o envía el mensaje,
desde el productor a varios
consumidores,
al mismo tiempo se la envía el mismo,
el mismo mensaje a todos ellos.
Es una especie de realmente no final.
Lo comentábamos antes en el caso
de la gestión de eventos
para el procesador de eventos para
para los diferentes almacenamiento
y al final es el sistema de gestión
que está insertando un evento
ahí y lo van a recibir, lo
vamos a tratar todos.
Los procesadores de eventos van
a tratar el mismo evento,
pero habría otra otra opción
en el caso de caso
de otra mesa que sería la cola vale?
En este caso.
En este caso también vamos
a tener consumidores,
pero cada uno de los de los
mensajes o eventos
se va a dirigir a un solo consumidor.
Solo un consumidor va a tratar,
es el mensaje.
Entonces, digamos que aunque
tengamos varios,
vale entre ellos, se van a acabar
dividiendo la la carga
y van a estar haciendo un trabajo
de forma de forma secuencial,
dividiéndose, dividiéndose, cada uno
de los de los mensajes por turnos.
Realmente es una especie de,
pero no en ese sentido,
en este caso, la de la aplicación.
Bueno, como decíamos, lo vamos
a utilizar en esa parte
del procesamiento de eventos
para garantizar el orden,
y lo vamos a ver, lo vamos
a usar como un tópico,
vale para ser la forma más parecida
a lo que es un Kafka,
vale lo que a lo que estaba pensado
originalmente y como tiene que
funcionar esa esa parte.
Pero, además, dándole un plus,
que es garantizando
esa ordenación,
que era el problema que nos estaba,
que nos estaba dando a Kafka en,
y por ello hemos decidido ir hacia
hacia un modelo con j vez,
utilizando.
En cuanto al proceso de
generación de rdc,
vale?
Bueno, ya hemos visto un poco
las piezas principales,
más o menos, pero volviendo a
hacer un poco hacia atrás,
cuando nos llegaba a este modelo
de gestión el dato
lo que nos estaba llegando
era lo que nos está enviando
a grandes rasgos.
Lo que nos va a llegar son esos
ojos, esos objetos, planos,
esos objetos que ya están
transformados
en lo que en lo que define,
porque de alguna manera la
Odontología mal en ese formato
que se va a insertar en el sistema
y vamos a tener que generar
el rdc a partir de ellos, es decir,
nosotros ahora mismo lo que tenemos
unos objetos con unos datos,
una estructura de datos, pero
no tenemos errores
y no tenemos los tripletes poniendo
desde ello ello lo va a llevar a cabo
el sistema de gestión.
Realmente vale yendo un
poco más a detalle,
que ya lo comentaba.
No son sólo los ojos,
no va a tener algo algo que sea
poco lo que nos va a llegar,
sino que se va a dividir en 2.
Por un lado,
han estado los objetos planos, los
objetos sin las relaciones,
y, por otro lado, las relaciones
ahí por lo que lo decía,
para gestionar que no me llegan,
relaciones con o enlaces
con algo que todavía no tengo,
el sistema madre
de esta manera, primero proceso,
todos los objetos, planos planos,
los incierto en el almacenamiento,
y luego ya con las relaciones,
pero sabiendo que ya
tengo los objetos
a los que voy a relacionar, es
un poco un poco el motivo
por el que se hace entonces,
nada.
Con todo esto el sistema de
gestión va a generar,
finalmente el.
El rdc, por ejemplo, un un
ejemplo de objeto plano
de los que nos va a llegar
desde la tele
va a ser pasar esto vale, no
deja de ser un un Jackson,
aunque luego al final se
pueda traducir en un.
En una clase objeto de una clase
vale un objeto plano?
Pues va a tener esta pinta,
va a tener una operación que va a
ser bueno hasta caso de inserción,
pero también podría ser
de eliminación
o de modificación de datos?
Vale, y luego va a tener los
datos en sí mismo, no?
Pues pues vamos a saber qué
es de tipo proyecto
en este caso Bale,
y además va a tener toda esta
toda esta información.
Todos estos datos son los que son,
las que va a tener Bale.
Como veis, no tiene ningún tipo
de relación con nada.
Esto es el que que es
el deseo es objeto,
es objeto plano, sin más,
con los datos básicos,
con todos los literales,
por así decirlo,
que nos va a permitir darnos de alta
en el proyecto luego luego ya
cuando no nos una vez estaba
el objeto plano.
Nos va a llegar más?
Está mal el título, aquí
sigue como plano,
pero sería este sería el la relación,
las relaciones Bale, esté vacía,
una vez procesados.
Todos esos objetos, planos
ya tenemos,
todo insertado, vale, toca unos
con otros para para formar
todos los datos enlazados.
Y entonces nos va a llegar otro
otro tipo de objetos
a través de otra cola
o de otro topic?
Vale.
Quién nos va a decir qué
relaciones tiene,
por ejemplo, volviendo al caso
del proyecto anterior?
Vamos a decir que este proyecto
10.154 Stalingrado
por un lado hay Boix,
en este caso bueno,
pues resulta que no tenía
ninguna ni ningún lío,
pero, bueno, nos de otras maneras no
nos venía, nos venía ahí pero sí
que está ligado a ciertas personas
no personas que formaban parte
de ese proyecto, que sería todas
estos identificadores que nos viene
aquí y entonces el sistema.
El sistema de gestión va a
saber cómo, cómo hacer.
Esos haces láser
para tener que generar
esas tripleta para,
para enlazar los datos,
unos con los unos a los otros,
los recursos o, mejor dicho,
unos con los otros para hacer
toda toda esta inserción,
por decirlo de alguna manera,
para hacer toda esta esa
generación de redes,
para generar los recursos hay
una cosa muy importante.
Es decir, el sistema de
gestión por sí solo
no va a ser capaz de hacerlo,
no va a ser capaz de.
Iba a tener que apoyarse en
otros en otros módulos,
y en otros sistemas adicionales.
Por un lado, vamos a tener que
generará una vale al principio
de la sesión.
Cuando empezamos a primera
hora os comentaba
que todo todo recurso en el sistema
va a estar identificado mediante una
mediante una uvi.
Por ejemplo, antes veíamos
que el recurso Picasso
pues tenía una orilla identificaba
que ya está el punto de Barra,
Picasso que nos habló de memoria.
No vale esa esa identificación.
Nosotros por sí solos no
vamos a poder hacerlo,
porque no vamos a poder hacerlo,
porque de alguna manera tenemos
que mantener un registro
de esa surfista que podría
identificar.
Luego no nos va a venir otra
vez el mismo dato.
En el caso cierre de la misma,
uri mal entonces digamos
que el sistema de gestión no va a
poder saber hacer hacer eso.
Es tema de gestión lo que va
sin saber es general,
pero para ello tiene que saber
las escuelas que tiene
que trabajar, tanto, tanto
las áreas de,
de que identifiquen al recurso
como las cámaras
para identificar cada uno
de los atributos
que va a tener ese recurso.
Porque los atributos,
los suelos valores,
pero los tributos van a ser
también tripletes,
como, como también veíamos que, como
por ejemplo el nombre o Bueno,
volviendo un poco poco atrás,
pues todo esto,
pues la modalidad, la fecha de
decidir la descripción, etc.
Etc. Este se va a traducir en lo que
es una Uriz dentro del ecosistema
de una hora y general para todo
este objeto María Mateo.
Este recurso, pero luego cada
una de las de los atributos
va a tener su propia obra y que
lo identifiquen además,
y luego también que va
a tener otra Ory.
Bueno, pues todos los objetos
de las relaciones.
Evidentemente, antes veíamos,
como el nombre era una era
un literal que al final
era una cadena que era Pablo
en el caso de Picasso,
pero podríamos tener relaciones
con otros, con otros,
con otros recursos también,
no que no sea que nos
fuesen literales,
sino que fuesen otros otros objetos
y otros recursos que tengamos
en el sistema
y así ir enlazando generando
todo todo, todo el grapo.
Para ello es para,
para lo que tenemos este, esta
factoría de Ulissi,
el servicio de descubrimiento, la
factoría de, Uriz como una médica
la que se va a encargar de asignar
esas esas subidas
a los recursos generados de acuerdo,
también a una política de Hury
que haya que establecida
en el sistema no es el que va
a saber cómo, cómo hacerlo,
como no al sistema de gestión le da
un poco igual, como cómo se genere,
simplemente quiere tener una nueva
y se tiene que cargar de ellos
este esta factoría de de un gris,
pero luego también también muy
relacionado con todo esto,
vamos a tener que realizará otra
labor muy importante,
que sería la parte del
descubrimiento y la conciliación de entidades.
Claro que es.
Cuál es el cuál es el problema
para que para que lo veamos
yo me tiene que se me
llega a algo decir.
Si me llega un recurso nuevo, si
me llega una actualización
de un recurso o me llega
una inserción,
también podría ser de otra
fuente de datos.
Podríamos estar hablando
del mismo recurso,
es decir, un mismo mismo
investigador,
por ejemplo.
Podría venirme a lo mejor espero no
estar diciendo una barbaridad,
pero podría venir de una universidad
de la Universidad de Murcia,
por ejemplo, también podría venirme
el mismo que ha colaborado
en un proyecto la Universidad
de Oviedo,
por decir algo o no.
Entonces, de alguna manera
tendría que poder saber
que ese mismo investigador
es el mismo.
Estábamos hablando del mismo recurso
y ahí es donde entra en juego.
La librería, de descubrimiento, de
la librería descubrimiento,
lo que va a hacer es es aplicar
diferentes mecanismos,
diferentes algoritmos para
poder identificar,
para poder saber si es
o no es el mismo
el mismo investigador que
estamos hablando.
Vale.
Si si tuviese un mismo identificador
en ambos sistemas,
sabríamos que no habría forma,
habría forma de poder identificarlo
fácilmente,
pero muchas veces no es el
caso y muchas veces
pues a lo mejor nos va a llegar
con cada uno de cada uno
de esos sistemas con diferentes
identificadores,
pero sabemos que el usuario, que
el investigador es el mismo
porque se parece en un grado alto
de un porcentaje muy alto,
no?
Entonces tenemos que poder determinar
que sea que sea el mismo porque
se llama y se apellida igual,
porque porque vive en el mismo sitio,
porque la fecha de nacimiento
es la misma, por ejemplo,
no por poner dos ejemplos.
Entonces eso es lo que se encarga
del esa librería de descubrimiento.
Habrá otros casos.
Habrá otros casos en las que
no sea posible hacerlo.
Mediante un proceso automatizado,
que una máquina no sea capaz
de identificarlo entonces,
en esos casos por sí que habrá que
hacer una, una labor manual,
y, de hecho así está previsto
que haya una cierta manera,
una forma manual
de resolver aquellos casos
que no sea la máquina,
no sepa cómo cómo resolverlo.
Entonces, esa esa labor es la
que va a llevar a cabo,
la librería de descubrimiento bale.
Entonces, bueno, hasta hasta aquí
finalizamos un poco lo que es la
generación de rne y demás.
Así que si tenéis alguna duda, me
imagino que muchas todo esto
y otras maneras Oslo va a contar
a profundizar mucho más
en sesiones posteriores de
esta de esta parte.
Justamente que estamos hablando,
estamos hablando ahora.
Yo tengo una pregunta.
Una, qué pasaría si el procesamiento
de las colas cae?
La máquina supongo que se tira,
indicó y luego se recuperará?
Levantarse?
Sería así si en ese caso, si
se cayese a la máquina,
digamos que como tú tienes
constancia de dónde está la leíste,
el último elemento,
cuando se vuelva a levantar
la máquina,
cuando se vuelva a recuperar
seguiría leyenda en el último que ha dejado,
con lo cual no habría ningún
tipo de pérdida.
Es una de las ventajas que tiene
este sistema de procesamiento
en streaming, bale y luego otra
cosa cuando ha dicho al final
que el mecanismo de disco a
bajar tendría que actuar.
Una persona para resolverla,
ambigüedades, una persona informática
o una persona usuaria, una, una
persona experta en el dominio,
por decirlo de alguna manera,
tiene que ser alguien capaz
de resolverlo.
Luego a esa persona habrá que
ponerle los mecanismos
para que pueda hacerlo, ya sea a
través de una interfaz más,
más amigable.
Ha trabajo o a través de un
fichero, por ejemplo,
que se procese eso habría que
todavía está sin terminar
de definir esa esa parte,
pero desde luego tiene
que ser alguien que sepa
que conozca el dominio
y que sepa como cómo resolver
el conflicto.
Lógicamente bale era bueno.
Yo tengo otra duda con
oye, perfectamente,
con respecto a los topics
y los eventos
cuando no me ha quedado claro,
cuando creo que, por defecto,
el cuando terminaba de procesar un
tópico se avisaba todos los altos
los eventos.
Pero vosotros lo tanto creo que era
ti o algo así me solo avisaba; vais
al al evento o al consumidor,
que lo requería en que
requería ese gato?
No.
La transparencia no me
quedaba muy claro,
porque estaba el modelo p2 p;
y el modelo está transparencia.
Si vale haber aquí la diferencia
entre entre ambos modelos.
Digamos que, por un lado, si
nos vamos al modelo p2 p,
que además que los consumidores
estarían procesando.
Los datos por turnos,
digamos que ejemplo, si yo
voy metiendo en datos,
llevamos por ejemplo el primer
consumidor necesario
el primero el segundo el segundo el
tercero el tercero Bale el cuarto
el cuarto y luego evaluaría otra
vez a al primero otra vez,
dirían por turnos cada uno un
dato, no, no todos todos
los datos,
como el otro modelo en este caso
se lo irán repartiendo,
por decirlo de alguna manera.
Si con eso queda cada día más
claro se va repartiendo
el trabajo de los consumidores.
Es el modelo p2 p, con
el modelo de cola,
vale de en el ecosistema jm.
Sin embargo, en el otro modelo,
el de y suscripción mal
el modelo de topics,
digamos que todos los consumidores
van a estar leyendo en paralelo más,
pero van a la van a hacer, van a
leer todos los los mensajes que se envíen
a la al tópico.
Es una especie de épocas
en este caso,
pero la solución adoptada
aquí cuál ha sido
la esta última que acababa
de comentar?
Por qué más se parece a Kafka?
En ese sentido, Kafka?
Trabajar de esta manera,
precisamente como si fuese
un Rocas y cada uno lee,
y si me interesa lo coge,
y si no es apto para correr
un poco más atrás.
Aquí vale, por ejemplo, si si vemos
en este caso la iigm que va la parte
del hay en la parte del centro
un poco hacia la derecha,
vale.
Y lo que vamos a tener son
dos procesadores,
vale, bueno para y otro para Bale,
pero a cada uno de ellos tiene
que recibir todos todos
los mensajes que reciben los todos.
Luego, ya que si internamente decide
no procesarlo es problema
del consumidor.
Pero llegarle vas a llegar al nivel
en el cual llegan sin intereses
la procesión,
y, si no, no es actor exacto.
Si no lo desperdició
ya estaba deshecha
y hasta me había quedado claro
cuál era la opción que sabía
que sabía si es es la de publicación
y la, por decirlo de alguna manera.
Gracias.
Una pregunta más.
Que queráis comentar.
Si no tenéis adicional
al final, lo bueno
cuando sea sin problema.
Propietarios
Proyecto Hércules
Comentarios
Nuevo comentario
Serie: Formación Martes 26 Enero Izertis (+información)
Descripción
Videos de formación

Canal
