
Idioma:
Español
Fecha:
Subida:
2021-02-10T00:00:00+01:00
Duración:
59m 21s
Lugar:
Curso
Visitas:
1.190 visitas
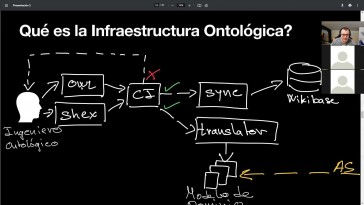
02_Ontología proyecto Hércules
Transcripción (generada automáticamente)
No lo vea al r.
Emilio ya te estoy grabando la cara,
no vale ahora más tu entonces
mejor guillermo
Sí sí sí muchas gracias a ver.
Ahora me parece, pero no
estoy compartiendo,
no ahora mismo no haremos.
Entonces, un momento.
Y es que le había dado a mi me peto.
Vale nada.
El que había puesto en modo creen
y vale ahora y yo creo que veáis
la pantalla no, más o menos
y se pasan las diapositivas no vale
vale bueno pues nada no sé si tenéis
alguna idea bueno ha comentado
este es uno de vosotros
que si lo habíais visto un
poco durante la carrera
y tal.
Entonces yo quería darles una
pequeña retrospectiva
un poco de lo que es la web
semántica y para rematar llegar al tema
antologías, que es una de las
partes clave del proyecto,
como comentó ya Guillermo.
En cuanto a la arquitectura
en general.
Entonces bueno,
básicamente la web semántica es una,
se puede ver como una web de datos
en el que no solamente hay
páginas web sino datos
y esos datos están enlazados entre
sí fue una idea de Tim
que veáis ahí que es hoy en día.
Bueno, era el consorcio y bueno,
es un campo que hoy en día
se puede relacionar mucho,
con Big Data,
que ya os sonará, la burbuja esta y
también con inteligencia artificial
la otra burbuja y bueno,
ahí tenéis debajo.
El ejemplo que os ponía guillermo
de Wikimedia wiki
data un poco que de esos va a hablar
más a fondo o Paulo en la siguiente.
Entonces, bueno, sobre quien consume
la información de la web está claro
que sobre todo las personas, no.
Cuando hacemos a través
de un dispositivo,
entramos, de manera que lo
entendemos nosotros,
pero por otro lado, también
están las máquinas,
es decir, programas informáticas,
informáticos,
que explotan toda esa información
que hay en la web.
Analizando la y también hoy
en día como sabréis,
hay muchos también que hasta dentro
de los mismos programas
que filtran un poco el contenido
nos hacen sugerencias
y todo eso entonces bueno
sin si por ejemplo tu
propia página web
no está muy bien no está muy bien
estructurada o no está muy bien,
digamos sí estructurada
o enriquecida;
por ejemplo, Google, o sea, es
como si no existiese un poco
lo que hay debajo era el.
Entonces, en qué se diferencia?
Cómo ve una web, una persona
y una máquina?
Pues evidentemente, claro, las
personas no somos autómatas,
entonces tenemos cierta creatividad,
tenemos imaginación.
Luego también cometemos errores, nos
cansamos ante tareas repetitivas
y tenemos una comprensión un poco
basada en el contexto.
Todo esto es diferente.
Respecto a las máquinas
que se suelen programar para ciertas
tareas específicas,
si están bien, cuando están
bien programadas,
no cometen errores a la hora
de explotar los contenidos
y luego, por supuesto,
pueden llevar a cabo tareas
repetitivas sin problema,
o sea, no tienen problema
en literario y terapia
algún tipo de proceso y luego
evidente también tienen.
Aquí sí que tienen dificultad
para entender el contexto.
Evidentemente, nos inteligentes,
como nosotros todavía no pueden
comprender un poco el contexto.
Entonces es información entendible
por las máquinas,
aquellos poner un ejemplo típico
de estos casi en el Pleno de
procesamiento de lenguaje natural
casi o de identificación de
nombres de entidades.
Entonces, por ejemplo, aquí
tenéis el caso de Oviedo
tiene una temperatura de
treinta y seis grados
Oviedo.
Puede ser la ciudad de España puede
ser la ciudad de Florida
o puede ser hasta el apellido
de un jugador
de fútbol sudamericano, por ejemplo,
y entonces claro,
cuando tiene una temperatura
de la cosa variar;
si son treinta y seis grados
centígrados para España
en Oviedo sería una temperatura alta;
si fueran Florida, sería
todo lo contrario
y sí y si hablaba hablásemos
del jugador de fútbol,
evidentemente, pues tendría.
Entonces es un poco.
Esto es.
Esto son un poco los contexto
de la información
tal como lo entendería una máquina.
Nosotros sí serían si tendríamos
un contexto a la hora
de hablar de Oviedo,
y sabríamos interpretar
inmediatamente esa información,
que son los grupos de conocimiento.
Sobre lo que se basa todo
esto, pues es un poco
el número de tripletes en el que
se basa la web semántica.
Aquí podríamos un poco determinarlo;
ahí tenéis un ejemplo
de un conocimiento sobre el piloto
de Fórmula uno, Fernando Alonso.
Hoy en día totalmente decadente
y acabado, pero bueno.
Aquí no tenemos algo así.
El nombre lugar de nacimiento;
la población del lugar de
nacimiento; es decir,
el número de habitantes de
Oviedo ahí tenemos;
de nuevo la temperatura,
tendríamos que Oviedo;
la capital del Principado de
Asturias ; la Comunidad Autónoma,
tendríamos una fecha de nacimiento
para él y también podríamos aplicarle
a enriquecer aún más dándole
contenido, un contenido más,
icónico visual añadiendo
una fotografía
y luego como cómo las
máquinas explotan,
como si, como como lidian.
Con todo esto de los grupos
de conocimiento,
pues aquí tendríamos un poco el
proceso que va de un lado a otro.
Partiendo de la realidad.
Que sería un árbol completamente;
tendríamos el modelo mental
que sí que hace un humano y
tendríamos sin embargo
por el otro lado.
El otro camino, los sensores,
todo eso avanzaría hasta
los documentos web
y todo eso y a la hora de recuperar
esa información
sería la máquina la que nos un poco
en base a ese grado de conocimiento.
Al usuario final;
ese contenido ya filtrado y
entendible para un humano,
en este caso cuáles son las
características de la web,
como como tal.
Pues sobre todo que no está
centralizada, es difícil.
Muy difícil garantizar la integridad
de la información.
Evidentemente para cualquier
concepto,
cualquier entidad que podamos
imaginarnos del mundo
puede tener distintas fuentes;
cada uno puede haber dado su punto
de vista y entonces está repetido;
y con distinta información también.
La información también es dinámica;
es decir, va cambiando imaginado.
Cuando hay un bulo o algo así
como se va corrigiendo
o cómo va evolucionando en
el currículum vitae
de una persona, dependiendo
si hay periodistas
que investigan sobre él y demuestran
que no había sacado titulación;
o bueno todo este tipo de cosas que
hoy en día se vean en España
y luego, evidentemente hay
mucha información
y un sistema no puede pretender
pretender incluir
toda toda la información que luego
también es importante.
El la, el principio lógico en
el que se basa un poco
la web semántica es, que es
lo de el mundo abierto,
cualquier cosa puede decir cualquier
cosa sobre cualquier tema,
desde entonces luego no basta
tampoco con publicar datos.
Evidentemente el mayor reto
es la integración,
o sea cómo podemos obtener
de lo veis.
Con todas estas iniciativas,
de big data
y de tratar de estructurar
todos los datos
que hay desestructurados en la web
y en el mundo es importante
que se proporcione una cierta
interoperabilidad
entre esos datos para
poderlos íntegra.
Entonces de aquí viene
el famoso modelo
de estrellas de Tim también, que es
el que diseñó para parar los datos,
o se ha decidido darles como
un ranking de menor
a mayor riqueza.
Entonces en el momento que
publica sólo los datos,
en cualquier formato, es decir,
cualquier página web que podamos
hacer nosotros mismos sobre nosotros
mismos y solamente tenga
sólo por el mero
hecho de estar enganchó termine,
ya, están en la web
y ser accesible por cualquiera,
le dan una estrella ya cuando el
tipo de formatos estructurado.
Imaginemos, por ejemplo, un
ayuntamiento que publican
este los datos de la iluminación
pública de las vías
o algo así eso ya le dan dos
estrellas porque el formato
está estructurado, pero, sin embargo,
aún no es propietario porque
estamos usando Microsoft,
no.
Por ejemplo, si en lugar de
estilo usamos cese v,
es un formato ya no propietario,
todavía ganamos una estrella
más y finalmente
sí podemos identificar cada recursos
a cada dato que tenemos como.
Una uvi que sea unívoca, es decir,
que no lleve el lugar a dudas,
llegamos a las cuatro estrellas y,
finalmente, si encima esos datos,
que ya están en formatos
no propietario,
o sea, en formatos no propietarios
y a la vez se enlazan
con otros datos que son exteriores.
Se consigue lo que se llama
la, las cinco estrellas del
de los datos abiertos.
Entonces, bueno, aquí tenéis el
ejemplo de los nuevos formatos
no estructurados.
Es decir, cuando tenemos formatos
de caja abiertas,
tipo de caja negra, es tipo
de imágenes vídeos,
música, luego, cuando ya son
binarios, estilo PDF,
se requieren tratamientos y técnicas
de este tratamiento
para reconocer los patrones, y aquí
también tenemos otro caso,
por ejemplo, de lo que es
un problema de pérdida,
se en el proceso de comunicación,
cuando la persona que va a publicar
tiene más información,
puede ser que esa información
se pierda en el proceso,
no a la hora de, dependiendo de
quién sea el consumidor un poco.
Entonces, por ejemplo, ahí tenéis
el ejemplo del próximo sábado,
podréis ir si ese próximo sábado
zanjó tan pesquero en PDF,
o sea, depende un poco de cómo,
de cómo se transmiten esos datos
eta el caso ya de los formatos
estructurados que os decía,
cuando ya hay una hoja de cálculo.
Por ejemplo, si el formato
es propietario,
lo comentaban que es mejor
que estén, por ejemplo,
en formatos estándares abiertos,
como cese v.
H. Temer de eso no quise que aún así
no resuelven del todo el problema
de la pérdida semántica, pero
ya es un paso más adelante.
Aquí tenéis otro ejemplo también
con el programa problema
que tiene html también no
como pueden diferir.
Aquí tenéis un caso, por ejemplo,
con Espanyol y alfabeto latino
y sin embargo, ahí tenéis un ejemplo
en alfabeto de Armenia
a la lengua Armenia, armenio, y
más o menos sería lo mismo.
Pero esto evidentemente, estamos
en lenguaje natural,
es decir, y las máquinas no
entienden el lenguaje natural todavía,
y luego lo mismo sucede un poco.
Con el formato de intercambio en
el que también puede ser,
o sea, también depende un poco de
tipo de documentos que tengamos
para hablamos de lo mismo.
Aquí tenéis el mismo ejemplo
como español y armenio,
y luego ya cuando añadimos la
siguiente capa, que es un poco
para identificar esos datos, las
cosas ya que es mucho más,
porque porque los navegadores
pueden detectarlo
y pueden devolver distintas
representaciones de algo.
Entonces, si te imaginabas,
si tenemos el concepto
que sea en base a un simple código
así por ejemplo hace z es
o lo que sea por poner algo, y eso
la máquina es capaz de entender
que en español eso significa España
y que en Armenia armenio, por
ejemplo, significa España,
pero en su lengua entonces ya
tendríamos todavía más riqueza
para identificar los datos
y finalmente aquí tenemos un
ejemplo de, por ejemplo,
de rsf aquí tendríamos el
caso del desempleo.
En este concejo de Asturias,
por ejemplo,
que ya vendría un poco bien
estructurado en las redes
no sé si os suena.
Supongo que no nos suena nuevos.
Voy a hablar un poco de redes.
Luego, claro, también el problema
de las representaciones,
o sea, como se puede, para
representar, por ejemplo,
una bolsa de patatas, cada uno
puede poner su propia imagen
o algo así?
No.
Entonces, lo bueno de la cual
se mantenga en eso,
es que se separan recurso un
poco de la presentación
y se le pueden poner distintas
representaciones
a un mismo recurso,
enriqueciendo aún más dando como
un poco más de una vista,
más caleidoscópica de un recurso
dado en este caso de patatas,
y luego ya llegamos al máximo de las
cinco estrellas que os decía,
cuando son cuando se pueden enlazar,
o sea, incluyen enlaces con
otros, como otros datos,
y esto permite que se
puedan reutilizar,
o hasta que se puedan descubrir
nuevos datos.
Porque esto imaginaros,
es como si tuviéramos una base de
datos que estuviera interconectada
con todas las bases de
datos del mundo
y entonces de manera unívoca
gracias a esa Sur y que nos decía.
No un identificador unívoco.
Entonces podríamos gracias a eso sí.
Otra base de datos, es más rica
en un área específica
de temática de lo que fuera.
Pues nosotros, desde la nuestra,
seríamos capaces.
Un poco de llegar a eso
y nos enriquecen todavía mucho más,
es el tope de cinco estrellas.
Aquí tenéis un ejemplo de redes
enlazado y tal, en el que podríamos,
en base a la información que estaba
publicado un poco en español
y en la página del desempleo,
en Asturias
y tal como sí sí lo pasamos a de veo,
o sea que en este caso es la sharía,
debe pedir pues podríamos sacar
todavía llegaríamos a más a más
información, porque si el municipio
en la página web
del Gobierno de Asturias solo lo
teníamos en español por ejemplo,
gracias a reconocer ese municipio
de manera unívoca,
con o Wikipedia o algo así
ya podríamos obtener
ese nombre del municipio,
en otros idiomas,
como inglés, francés o como se llame
y podría ser más fácilmente enlazado
y se podrían conseguir todavía
más, más más información.
Bueno, estos son los principios del,
intenta tampoco los cinco,
o sea utilizarlas para
denotar las cosas
es decir esos identificadores
unívoco que os decía permitir
que de esto, es decir,
por ejemplo que os comentaba
un poco del código,
ese de que España se se representase
por medio de un código,
por ejemplo, en este caso de
imaginar los el código iso de España,
que es ese cuando es de dos cifras.
O es cuando desde tres valores
no supe entonces gracias a esa
esto es de referencia
porque le podemos adjudicarle a ese
código que es unívoco siempre
una etiqueta que sea español,
España es el caso de que sea inglés
o España si fueran veraces,
y de esta manera.
Lo haríamos totalmente de referencia
y luego es importante también
como principio, que proporciona
un poco información útil
tanto para personas como
para máquinas.
Es decir, cuando tenemos
contenidos en html,
nosotros, si los podremos disfrutar
como personas humanas.
Pero si encima estamos en rdc pues
todavía es mucho más útil
para una máquina, para poder
enlazar a otros sistemas,
como decía, que ahí lo tenéis.
En el punto número cuatro,
un poco esto es un poco.
Una panorámica de la limpieza Open
Data usa los datos abiertos,
como fueron creciendo a partir
de dos mil siete,
que fueron un poco cada vez se
fueron creando más vocabulario
si todos ellos enlazados entre
sí y íbamos hasta llegar ya
a el último caso, por ejemplo,
en dos mil diecinueve,
cuando empezaron todavía salir más,
más, más y más vocabulario
si todos enlazados ante el
siento, estén ensayo
por colores un poco los que fueron
publicados publicando los gobiernos
de cada país los tenéis
un poco en naranja.
Bueno, en esa especie de naranja y
todo cuando son un poco de Biología
o de Ciencias de la vida lo tenéis
en rojo; cuando son vocabulario
es oh, oh, oh, oh, si vocabulario
controlados de lingüística
lo tenéis en verde!
O vamos todo eso un poco así?
Ese es un poco la filosofía, la
de la labor se mantiene.
Aquí tenéis algunos algunos ejemplos
de iniciativas muy, muy potentes.
Sobre todo sea uno de los pioneros
y los que más importancia
le dieron fue siempre el Gobierno
de Reino Unido,
Inglaterra simple, siempre mucho por
la transparencia y un poco,
y por la ue, por los datos
abiertos en España,
Bono.
Ponga un poco el ejemplo de Gijón
y eso porque vamos a aprovechar las
la positiva de cada presentación,
pero por un poco de historia fue el
Ayuntamiento de Zaragoza en España
el que el que uno de los
pioneros, un poco,
que sigue un poco la estela
del Reino Unido,
y fue de los de los que más
todavía hoy en día
es en los que más datos abiertos
tienen totalmente utilizables,
y esto a que os quiero
poner un ejemplo
de cómo se pueden utilizar
esos datos,
o sea, por ponernos un ejemplo, no
sé cómo cómo será en vuestra ciudad,
pero en Gijón, por ejemplo, todos
los datos de los autobuses
públicos de la Empresa Municipal de
Transportes Urbanos están en abierto
y están enlazados.
Entonces, cualquiera puede utilizar
esos datos para para, por ejemplo,
crear una aplicación como las
que hay para no ser, para,
para predecir por dónde
van los autobuses.
Cuántos minutos van a tardar un poco?
Supongo que en vuestra
ciudad también.
Tenéis algunas aplicaciones
que que chupen datos un
poco de esos besos,
esos catálogos de datos que
el mismo ayuntamiento
proporciona.
Entonces lo normal es que los
del mismo ayuntamiento,
porque tiene recursos para ellos,
pero cualquier usuario acuerdo,
por ejemplo, al principio,
cuando la primera vez
que los publicaron,
hubo una pequeña empresa
entre varios amigos
hicieron una primera aplicación
de la, de transporte,
o sea, de predicción de tiempo para
autobuses urbanos en Gijón,
y era totalmente ósea.
Era una iniciativa propia
de ellos, privada.
En este sentido,
y pero chupando un poco de los
datos del Ayuntamiento
hoy en día.
Bueno, eso ya pasó a la historia,
pero porque al final fue
el Ayuntamiento
que lo siguió explotando y luego
ya tenéis en Latinoamérica
tenéis el caso de aquí de la
parte de debajo es Chile,
uno de los países que lleva también
desde los pioneros
en Hispanoamérica.
Para eso, y bueno, aquí un poco los
beneficios del del Tata en esto.
Eso sobre todo eso, la apertura
de los datos,
o sea que sean abiertos y accesibles,
y se evitan pérdidas.
Se mantiene al pública, es decir,
porque en el momento que publica,
si esos datos ya dejan
casi de ser tuyos
y los ha aprovecha otra gente y
es casi un poco imposible,
que se pierdan del todo, bueno,
se pueden, evidentemente,
pero luego también se facilitan
la automatización de tareas,
y me he imaginado el ejemplo
que nos ponía poco
de las líneas de autobuses
de una ciudad
y luego gracias a que
están enlazados,
se pueden reutilizar por distintas
aplicaciones que ponía
y también se integran más fácilmente.
Las aplicaciones es la mejor.
Vamos, o sea básicamente un poco
lo que os comentó ahí abajo,
la mejor manera de explotar tus
datos se le ocurrirá seguramente a otra,
como el caso de esa aplicación
que os comentaba.
Buenas esas sombras, un poco
la la panorámica de las tecnologías
de la web semántica.
Esta famosa tarta de la
cual se mantenga,
o sea, desde más bajo nivel,
tenéis Único de para,
para que esté todo estandarizado.
Por ejemplo, estamos.
Os acordáis siendo como
somos españoles,
no la hay y siempre nos da lío
por ser por no estar incluido en
el catálogo de así entonces,
gracias a un único de todo el
mundo ya no hay excusas
para que lañ o otros caracteres
Asgard como.
Una vocal acentuada por ejemplo, o
algo así para que nos den lío
y luego tenéis también a muy bajo
nivel, la es la única,
que es el identificador básico de
todos luego una capa superior.
Tenéis XML enriquecido con
los y con el esquema
de que por encima tenéis
rsf rdc, esquema.
Encima, tenéis las antologías
que os voy
a hablar un poco al final
de la presentación
por encima de las antologías.
Hay la lógica que las antologías
proporcionan, cierta lógica,
pero todavía se puede mejorar
la lógica, por ejemplo,
con reglas que normalmente las
antologías no las incluyen
y luego ya claro,
y a esa la demostración
y a la confianza
un poco como como como colofón
un poco de la famosa Tarta
de la web semántica.
Entonces aquí esta es
la tarta original,
y esta es la tarta, un poco
que la más actual
no.
Los cambios que se han ido
produciendo entonces bueno
sobre todo por encima de ese esquema
tenéis seguir teniendo las antologías
y las reglas que nos decía y luego
tenéis un lado ahí podéis ver
las tenéis el cuello es
parte del parque
les vamos a hacer un lenguaje
de consultas para para rsf
y luego tenéis las se de esos va
a hablar sobre todo Pablo
luego una la presentación más
o menos la estructura
es un poco otras versiones
de la tarta dependiendo
de donde queramos poner el
foco por ejemplo bueno
ahí tenéis ya incluido ya son tenéis
incluido también un poco.
Con agradece a que riqueza ha hecho
temer entonces tenéis también
son como enriquece ahí son por
encima tenéis agradece de nuevo
los que nos habíamos estado antes y
luego por ejemplo tenéis cosas
como ponía arriba que es cosa
es como es un vocabulario antológico
para representar vocabulario
y controlados un poco
los y taxonomía,
si todo eso, que a veces no incluye
la misma misma página web
de eso ya vamos a hablar más
adelante también bueno
aquí están algunas de las de
las tecnologías de aquí
vamos a hacerlo muy rápido.
Porque ellos, sobre todo quería
llegar a las antologías
entonces voy a hablar a centrarme
sobre todo en verdades.
Para la descripción de
datos y parques.
Casi no lo voy ni a mencionar,
seguramente me lo salté sexta,
también me lo voy a saltar porque
de esto va a hablar más.
Pablo, y yo sí que me voy a centrar
un poco en rdc y en estos dos
van un poco en diagonal.
Entonces el acrónimo significa
restos de inscripción,
es como un marco de inscripción
para los recursos.
Entonces con ellos
describimos lo que es un recurso
en la web semántica,
es decir, se identifica un recurso
imaginar, por ejemplo,
una bolsa de patatas famosa.
Identificamos de manera unívoca,
como una uvi,
es decir, bueno y se
basa en tripleta;
es decir, hay un sujeto, un
predicado y un objeto que esto seguramente
ya os suena un poco de también de
cosas que visto en la carrera,
y eso este es un poco.
Aquí tenéis lo que es un sujeto,
lo que es un predicador
y es un objeto.
Entonces, como sujeto identifica
la Facultad de Biología.
Por poner un ejemplo como predicado,
tenéis la identifica.
La propiedad de creación y como
objeto tenéis a Juan,
es decir, esto se lee como como
cuando creó la Facultad de Biología,
un poco la estructura.
Aquí tenéis un poco como
sería el lugar,
fue un poco jugando, lo
tenéis o sea a rival.
Con un diagrama y abajo
qué aspecto tendría un poco
en blanco con un código.
Para que os hagáis una idea
de cómo es la sintaxis
y todo eso como pinta?
Bueno, es importante que decir que
mi alrededor es posicional,
es decir, aquí tenéis tener
su brazo arriba abajo
y todos esto se relacionan.
Es decir, ahí tenéis como
el recurso Ana.
Lo veis, que se aprovechan
el siguiente gráfico
y se vuelve y se vuelvan al
azar y vamos sacando
como más más información.
No, entonces tenéis a Ana Juan
como profesora de biología,
pero no tenéis a Ana que a la
vez que se dice que es
profesora, de biología es profesora,
de Química también;
o sea, de los estudios de
Química de la Facultad,
por ejemplo, y luego se añade a
Luis y Luisa da vez resulta
que también es becario, de
la Facultad de Derecho,
por poner un ejemplo.
Esto es como cómo se van componiendo
y se van aglutinando los
famosos entonces.
Bueno, aquí tenéis lo
que es el resultado de todo esto
ya de manera unificada.
Bueno, hay distintos formatos y
sintaxis esto no quiero aburrir
tampoco lo más importante siempre
es que es el modelo de ese
que vimos en los diagramas.
Pero luego eso el código lo podéis
ver en tres gr de XML,
uno, que ya está bastante caduco,
porque es muy hermoso;
luego, tendréis triples y echar
un poco de los que.
Tampoco.
Perdón, pero, bueno, esto era un
poco lo que es como esto.
Yo creo que no.
Os quiero aburrir mucho simplemente
quedarnos con es el lenguaje
de consultas para la web semántica
lo vamos a ver seguramente
sea al final proyecto si se
utiliza, por ejemplo,
para resolver las famosas preguntas
de competencia que le hacemos
a la antología que sobre la
Universidad de Murcia,
entonces solo veremos un poco
de manera práctica,
muy cascada,
para que no puedo comentar.
Por ejemplo, eso es una consulta,
para buscarme páginas cuyo
autor sea un profesor,
entonces aquí tenéis un
poco la sintaxis
de cómo sería la pregunta,
y como llegaríamos un poco
a la respuesta, no,
pero esto no quiere mucho esquema,
es ese esquema.
Queda un poco formato a al A r.
Entonces, esto, a lo mejor sí que os
suena un poco más ya informática,
más clásica,
porque, bueno, hay un
poco lo que eso es
la las entidades que son clases, las
clases, por ejemplo, imaginados.
La clase persona puede
tener instancias.
Por ejemplo, la persona
puede ser Juan,
puede ser.
Ana puede ser todo, es luego
las propiedades.
Es decir, que Ana es profesora
en la Facultad
y un poco, esa son un poco,
la las nos vamos,
las entidades que entran en juego.
En este esquema de redes,
aquí tenéis un ejemplo.
Bueno, tampoco me quería extender
mucho más inferencia;
esto es un poco decir páginas
cuyo autor sea una persona,
y entonces aquí llegamos,
o sea, con lo que me refiero
a que con diferencia,
es que es que, por ejemplo, a partir
de deducir que un profesor
es una persona, pues acabamos
obteniendo resultados
de la misma manera.
Ya llegamos al tema de un
poco de las antologías,
que es lo que más me interesa.
Esto tengo una presentación, que
la voy a presentar ahora aquí.
Esto que sirva un poco casi como,
como así como para que para
mi presentación,
o sea, de traducción, poco, es
que después de ese esquema,
se creó el lenguaje ya más específico
para crear antologías, que
es la base del proyecto.
Este, que del que os hacemos
toda esta formación,
es un hombre, añade más expresividad
porque se pueden formalizar dominios
concretos y es mucho más allá,
o sea, es, por así decirlo.
Es antologías como un vocabulario
más rico que una simple taxonomía,
porque se añade expresividad
y se añade lógica,
pues lo vamos a ver un poco en juego
tanto que os voy a hablar un poco
como, sobre todo el viernes
que os voy a hacer instalar un
editor de antología de antologías
para que, para que vosotros
mismos creáis creéis una,
algunas clases y todo eso, conmigo
y todos los y veáis un poco
cómo funciona, bueno, algunos mitos
sobre la web semántica que se podrían
haber deducido circular o en su día
y tal, yo voy un poco a mostrarla;
las dos caras,
la cara buena y la cara mala.
De todos ellos, uno del navegador
inteligente,
el mito, era que el objetivo
es conseguir
sistemas que naveguen por internet
de manera inteligente
y nos libre de todo un poco
la tarea de la realidad.
Bueno, pues que desarrollar
tecnologías
que faciliten este Procesamiento
Automático de Información web
sobre su integración.
No es una cosa tan trivial, es decir,
la semántica sobre todo no es
inteligencia artificial,
pero sí se pueden utilizar
algunas técnicas
de esa esa disciplina un poco.
Luego el mito de que se
basó en una nueva web
es la web tras punto cero,
una nueva versión de la web
que va a cambiar todo
lo que había y todo es eta y nada.
La realidad es que se propone un
modelo de transición gradual,
o sea si se puede ver cosas de web
semántica en la web de hecho
por poner un ejemplo cuando vosotros
buscáis un concepto
o algo buscáis en Google lo normal.
Si o sea lo normal es que
viniera simplemente
un listado de resultados,
no los típicos resultados que tenéis
en Google cuando eso,
pero si os fijáis de unos
años a esta parte
yo creo que dos o tres años y
aparece en la parte derecha
del resultado de Google aparece
como una cajetilla,
una especie de cajitas y con datos,
y esos son por ejemplo eso sí
que son datos semánticos.
Es decir, que pertenecen a un
párrafo para que veáis que de alguna manera
la web semántica sí llegó a a usar.
Si ha llegado a a a la
web convencional,
luego al otro mito era que vamos,
que se iba a generar una especie
de cerebro global que,
que nos iban solucionando
todos los problemas
y bueno, o sea eso
tampoco es así pero sí es un camino
hacia la inteligencia colectiva
en el sentido de que se facilitan
un mejor uso de los datos.
Quiero decir la web semántica
en su día fue una burbuja,
que luego la siguiente
burbuja fue un poco
el big data y la inteligencia
artificial,
y en realidad la el big data y
la inteligencia artificial,
y todo eso, mama un poco o
aprovechan algunos de los aspectos
de la web semántica.
Si luego la gran verdad se propone,
la creación de una única antología
con todo el conocimiento
de la humanidad y la realidad
es que no va más allá
que se fueron creando
diversas antologías
para diferentes dominios.
Es decir, al principio se pensó
en hacer más súper
sintieron lo que se llaman
antologías básicas.
Luego no voy a enseñar
economía pensadas
desde el punto de vista filosófico
para que se pudiera representar
cualquier cosa,
y todas esas fueron fracasando,
y se prefirió un poco más
a la modularidad,
es decir, se empezaron a hacer
cada vez más pequeñas
y más concretas para dominios
un poco específicos
que fueron un poco facilitando
la integración.
Entonces, todas esas antologías
básicas,
que se llamaban de alto nivel,
cayeron en el descrédito un poco,
y la prueba está en que Google
lo utiliza para otros son antologías
un poco para mostrar los resultados
y luego mito también lo de etiquetar
de manera unívoca.
Solo como una comuna como
identificador, cada cosa,
pues no es factible, evidentemente,
porque cada cosa lleva sus metadatos
y las, si aún así todo eso
son un coste más.
Ahí era luego otro mito uno, que es
que nadie querrá compartir datos.
Esto era lo que se decía, no todos,
todos esos datos están abiertos
en vez de este uso excesivo
y luego encima datos que
hacen como otros,
y que mis datos a disposición
de todo el mundo.
Esto nadie lo va a querer
hacer eta y la realidad
es que cuando se encuentra un
retorno de inversión adecuado,
si se da o sea, ahí tenéis,
por ejemplo,
el caso de esquema pintor y
principales buscadores,
que indexar datos estructurados
de esta manera
y tenéis la huella de Yahoo,
sean los principales.
Demasiada apertura, sabremos
datos, vasos de datos,
nos perderemos, y la realidad
es que sólo pasa,
o sea, y hay tecnologías para
limitar el acceso,
siempre sin controlar y seguramente
bastante más que yo,
un poco de seguridad y de todo eso
se puede declarar siempre también
de dónde vienen los datos o se pueden
estar establecer la propiedad
legal a los datos,
o sea, todo lo declarado o el
tipo de licenciamiento
que queramos poner a los recursos.
Son los otros mitos lo que va
a ser una moda pasajera.
La web semántica empezó siendo
algo nuevo y apoteósico
sea.
Todo el mundo se subiera
un poco a la burbuja,
lo amargo, porque ya se quedó viejo
cuando llegó el Big Data y todo eso,
y en realidad es que claro,
ya estaba planteada
en mil novecientos noventa y cuatro
y con una visión a largo plazo
y, y luego sin embargo, el aspecto
al demasiado entusiasmo,
demasiado escepticismo
sí que tenemos,
o sea, tenemos pequeños pasos.
Como supusieron un momento hubo rcs,
o los formatos verla era un poco
para datos financieros,
y todo es que realmente sea
no bajo ese dos formatos.
Pero sí están un poco incluidos
hoy en día,
como podemos verlo por los
buscadores principales, no, y luego sí
sobre todo que no hay una,
no lo que se dicen,
no se nos ha desarrollado una
aplicación y eso es verdad,
pero en realidad es necesaria,
tampoco es muy necesaria porque
podemos explotarlos igual
o sabiendo de qué manera explotan
los mismos datos
estructurados Google,
Yahoo, o todo eso,
pues podemos ver que en realidad
no, no es tan tan,
tan necesario y finalmente
bueno un poco.
Esto es la panorámica ósea
o en mí como decía,
las fases de desarrollo y un
poco de la de la web.
Se no, la primera fase fue
la de producción.
Ya se quedó lanzada.
Es verdad que luego cayó
un poco en descrédito,
pero, como vemos, la segunda
fase del consumo
está aprovechando a partir
del Big Data.
Todas las lecciones aprendidas,
un poco de esa primera fase,
y en base a eso se dio, se
nos dio un poco cuenta
y en esto coincide un poco con todas
la explotación del big data,
que la calidad cada vez más
importante, es decir,
los datos tienen que estar
muy bien etiquetado,
sí y va más o menos todos.
Esta es la primera presentación que
os quería que quería hacer.
Entonces, ahora no sé si tenéis
alguna pregunta sobre esta fase.
Os pareció muy oscuro.
Como visión general muy buena
y yo creo que sea un poco,
porque la presentación
es un poco más dura,
ya centrada en antologías y yo
vamos a ver nuestro perfil
y eso yo creo que está.
Vais a agradecer un poco más en eso.
Entonces voy a cerrar esta y vamos
ya a en que me queda un cuarto de hora.
Vamos a pasar, tampoco pasa
nada de menos álvaro,
no la percibe, igual me
pasa un poco a ver.
Bale se ve, ya no.
Pasan diapositivas, no vale?
Pues entonces que es una antología
esto, si recordáis,
la otra presentación un poco
era lo que nos decía,
que aparte de los de la fase
de los datos enlazados,
y todo eso basado en las redes,
otra de las piezas claves de lo
que era la web semántica
era crear ese asunto lógicas
que os comentaba
en un primer momento se pensó en
esas son superó antologías
de alto nivel.
Una de ellas era Elche o
tener asumo, que eran,
estaba hecha para que os hagáis
una idea por filósofos,
es decir, se partía desde
las cosas que eran,
que se llaman perduran Durant
para saber si una entidad
en el tiempo se modificaba o no
sea ponernos un ejemplo.
Si una piedra jamás se modifica,
pero un animal muere y se disuelve
y acaba en cenizas
y acaba en tierras,
entonces bueno y ahora a esas
distinciones tan de alto nivel,
que de hecho el equipo eran, sobre
todo italianos, filósofos,
y y partían desde ese nivel
hasta luego llegar
hasta lo que nos pueda interesar
a nosotros.
Por ejemplo lo que es una persona
y lo que pueda ser un trabajador
de una empresa
o un catedrático de universidad
entonces llegaban desde muy alto
nivel hasta eso pero sobre todo
lo que es una antología
tal como lo entendemos más
en la web semántica
digamos realista es la que formaliza
un dominio concreto es decir.
Vamos a dejarnos ya de las
antologías del súper alto nivel
que van desde desde la filosofía
más más más más más oscura
y más tal hasta lo que es ya
un dominio específico
que es muy concreto
y para el cual podemos definir
un vocabulario
que sea unívoco de nuevo hablamos
de las que se había comentado
y para compartir el significado
entre aplicaciones es decir
que esta antología se pueda
compartir y la pueda reutilizar otra otra.
Otras personas y todo eso y
a partir de eso inferir
nuevo conocimiento entonces
aquí tenéis los términos
relacionados que nos comentaba
antes una taxonomía.
Una taxonomía.
Supongo que os sonará un poco de lo
que es la web y tal es cuando,
cuando le cuando añadimos jerarquía
a una lista de conceptos
simplemente por el mero hecho de
decir que no sea un gorrión,
es un pájaro; un pájaro es un animal;
bueno, entonces eso ahí tenéis una
simple jerarquía, no, simple
y luego tenéis.
También añade definiciones
de los términos;
es decir, que tiende a ser como
una especie de diccionario,
pero que también hay jerarquía;
es decir,
y luego ya la antología
es como lo que está
por encima de estos dos tipos de
vocabulario, controlados;
es decir, tenemos definiciones
de los términos,
tenemos identificadores unívoco
y tenemos jerarquía entre
entre los conceptos;
o sea, podremos ver ahí un poco todo
lo que decíamos de Juan y Ana.
Son personas y todos entonces aquí
tenéis ejemplos de dominios
que se puedan coger.
Hay, hay miles no?
Evidentemente dentro de la medicina
y muchísimos en también.
Biología, aviación, animales comida.
Aquí tienes un ejemplo de lo que
sería las partes interesantes,
de una vaca para para casi pensando
en lo que es la por entonces partes
de una antología,
o sea que en qué parte se
divide una antología.
Pues primero lo que decía,
proporciona un vocabulario,
es decir, un vocabulario y
además que sea unívoco
para todos compartido.
Entonces tenemos una
serie de términos.
En este caso tenéis un corazón
y tenéis el corazón,
tenéis la sangre y lo que ha hecho
el sistema circulatorio,
y luego, entre esos términos
o conceptos que se trazan
son propiedades;
es decir, ahí tenéis.
Por ejemplo de ejemplo del corazón,
es un órgano muscular que es parte
del sistema circulatorio.
Todas estas relaciones entre
entidades ya supongo
que vamos a suena bastante supongo,
de otros ámbitos de la informática
y luego es un lenguaje formal,
es lógico, porque como podéis
ver aquí debajo
vamos a ver si se puede formalizar
de manera lógica.
Tipos de antologías.
Aquí es un poco lo que nos comentaba
antes las salas,
las que eran las que se hallaban
básica básicas que solo esas
que os comentaba yo está
una, que hoy en día
tiene bastante predicamento que
está bastante aceptada
porque es es ésta lava
y beige y forma
montón tampoco le comió la tostada
un poco a Elche y asumo en el sentido
de que la la simplificar un poco,
pero llega también a altos niveles
y ésta sería un poco
las fundacionales,
y las que nos interesan a nosotros
son las de dominios,
es decir, las que formalizan
ya un dominio concreto,
en este caso la universidad,
no como como sabéis,
de este proyecto,
y entonces se están definidas
para un vídeo concreto
y suele importar antologías
generales.
Es decir,
cuando tenemos, por ejemplo, es
catedrático de universidad,
no por ejemplo o o algún puesto
de estos de la universidad.
Eso son todo personas,
entonces persona
y ya está definido por el
vocabulario de alto nivel de arriba,
pero, pero nuestro dominio entonces
los aceptamos como clase
superclase sí es decir, como
en las capas superiores,
pero a nosotros lo que nos interesan
son las personas jugando roles
de nuestro dominio.
Entonces, bueno, estos son un poco
los vocabulario que os había
comentado en la otra rueda de prensa
que se les proporciona lo
que son los dominios.
Rangos, y sus clases un poco
lo tenéis escocés,
que esto es para esto, es un
vocabulario muy concreto
que no lo vamos a os.
Voy a dar muchos detalles
porque si os lo voy a enseñar un
poco en la sección práctica
para que veáis cómo se incluye esto,
esto es para vocabulario es
controlados un poco en este caso.
Para entonces, un poco lo
que nos comentaba,
que un test tiene ya jerarquía
y tienen las definiciones,
pues es como se pinta un
todo, lógicamente,
ese tipo de conocimientos
en una antología,
y luego ya el lenguaje por
excelencia de Deontología
para la web es tal, que es basado
en una lógica descriptiva,
pero que podemos realizar
las inferencias.
Como veíamos los ejemplos en agradece
y tal permite definir clases
y propiedades relacional.
Es distinguir entre clases,
relaciones individuos,
y luego tienes las distintas
versiones
y luego aquí está el editor de esto.
Si queréis podéis tomar nota ahora,
luego os voy a pasar por el Chatel,
el enlace para que si eso lo instale
antes de la sesión del viernes,
que el viernes
vamos a jugar con él es un editor
de antologías para hacer
los ejemplos que os voy a poner de
ejercicios un poco es de código;
o sea, es gratuito o totalmente
gratuito.
Podéis instalarlo gratis.
Además, es basado en independiente
de Windows y Linux o Mac,
o lo que queráis,
o sea, funcionan todos los sistemas
y vamos a esos nuevos paso el enlace
para que para que si no os importa
tenerlo ya instalado
y así aprovechar mejor el
tiempo el viernes,
si no, no pasa nada porque se
instala en dos minutos
y no nos cuesta mucho.
Bueno, cuáles son los elementos
de una antología?
Tenéis lo que son las clases, no
seas un conjunto de entidades,
o sea una clase, por ejemplo, sería
profesor y dentro de ese deseo
de la clase profesor tendríamos los
individuos, no, por ejemplo,
Ana Luis, aquellos profesores
que estábamos diciendo.
Si tenemos también la
clase asignatura,
pues tendríamos debajo, biología
general, uno,
biología general, dos bases de datos,
o sea, lo que fuera y luego
están las relaciones
o propiedades que relacionan
esas entidades
no eso por ejemplo ahí tenéis es
hijo de Eto o tiene edad tiene tiene
el primer apellido estos
son de tipo objeto
cuando se sea cuando cuando este
tipo de propiedades de tipo objetos
son los que los que relacionan
una base como una clase,
es decir, por ejemplo,
es hijo de podría
ser, por ejemplo, persona
es hijo de personas,
es decir, ahí tenéis dos clases
que están relacionadas
por medio de esta propiedad
de tipo objeto.
Sin embargo,
cuando son de propiedades
del tipo dato
esto va de lo que es una clase, por
ejemplo, persona tiene edad.
Entonces, en este caso está esta
propiedad, tiene edad,
es de tipo dato, porque lo que hace
es proporciona un número simplemente
a esa persona para definir su edad,
es decir, por ejemplo, Juan tiene
treinta y siete años.
Entonces esta sería la propiedad
de tipo dato.
En el otro extremo tendríamos lo
que es un número simplemente,
es decir, un dato en este caso
integrado por algunos antecedentes
de lo que son las antologías.
Esto no nos quiero aburrir porque
son poco a poco chapas,
espero poder hacerlo es un.
La misma palabra, antología, viene
un poco de lo que es la filosofía,
un poco lo que nos contaba de los
italianos de la odontología.
Pues bueno, ya la cosa se
remonta a Aristóteles,
asiste desde donde sea un
todo lo que es el ser,
y luego es el conocimiento.
El estudio de estudio
del ser eso sería lo que significa
antología de hecho, es un falso,
es un ósea, es es un poco ambiguo
el término antología,
porque filosofía la antología es
el estudio del ser de verdad
es decir la tecnología por ejemplo
pero bueno en nuestro ámbito
no tiene exactamente que sea.
No, no tiene mucho que ver con eso,
porque nosotros lo que hacemos es
un poco más de bajo nivel,
no de la Universidad, por
poner un ejemplo.
Entonces lo que sí es un
poco la formalización
de un dominio, entonces, nosotros
como solo nos interesa el dominio
de la Universidad no vamos a llegar
a todo lo que llegaban.
Los italianos un poco filósofos.
Las características que tenéis
ese vocabulario, compartido,
las antologías, siempre se
suelen hacer en inglés,
aunque luego lo de las traduzca
es un poco al Espanyol.
Pero vamos para que sea
interoperable.
Sí sean compatibles un poco
con el resto de comunidad
que las quiera reutilizar.
Se hace un simple inglés por defecto
y luego ya vamos hagas un
poco localización.
Internacionalización a la
lengua que te convenga,
luego otros precedentes
de las antologías
es la lógica en general.
Tenéis también la lógica posicional
esto no me quiero extender mucho aquí
porque esto vamos seguro
que nos aburre
y es muy importante.
Es un poco de historia solamente
luego la lógica
de dedicados tan también con
algunos de los ejemplos.
Aquí tenéis, de nuevo juego
un poco las propiedades
que subyacen a la antología.
No se os acordáis de las propiedades
y todo eso lo vamos como,
como la jerarquía de clases también
tenemos una antología,
la vamos a ver de manera
mucho más sencilla
en el ejemplo que en los ejercicios
que vamos a hacer el viernes,
pero vamos de ahí; viene otro claro
antecedente del asunto,
orgías.
En esto también eran las
redes semánticos,
que fueron varios lingüistas, casi
medio filósofo de muestras
como vamos a ir un poco si estos son
ahora ya me dio un familiar
de lo que acabamos de ver.
Como antologías,
ahí tenéis los dos tipos especiales
de relación.
Como Isa un gorrión es un no.
Entonces es ese es el tipo de
relaciones de pertenencia
y luego estaría también la inclusión,
no sea, por ejemplo.
Como cualquier otro ejemplo de
entre todos los mamíferos,
hay perros, hay ballenas, hay un
poco lo que sea incluyendo,
luego fue otra, estuvieron
un poco mejor también,
y de los filósofos, un
poco de la nada.
Después de la Edad Media,
que se considera una especie de
precedente de las antologías,
y luego esto, que ya sí que son
ahora más en el terreno de la informática,
los diagramas, de, entidad relación,
es claramente o sea,
es otro otro precedente claro de
lo que es las antologías,
no porque también se utilizaban para
para capturar un modelo de dominio
y también vamos a ir sobre
todo lo que se usan base
de datos.
De hecho, es una traducción
bastante habitual
llevar a cabo una traducción
desde una antología
a una base de datos y viceversa.
Se puede hacer fácilmente.
Otro también de los precedentes.
Fueron los tópicos mapas de tópicos
que esto un poco lo que solía hacer,
o sea, era formato xtb.
Yo creo que ya vamos poco
a poco, se utilizan,
pero estaba basado en XML,
dieron un poco también para que
se pudiera compartir también
y por supuesto los modelos
orientados a objetos que también tenía una,
tiene una traducción bastante
trivial de lo que es una antología a todos.
Estos temas y estos modelos
así está bueno,
ya lo vimos en la anterior
presentación,
me voy a extender mucho.
Aquí tenéis de nuevo la tarta,
un poco lo que nos contaba
antes de las clases propiedades.
Las jerarquías está también
está vista esta vista.
Esto también lo vivimos todo lo que
más nos ponía antes con profesores.
Aquí lo tenéis un poco con personas,
seres vivos y tal
y hagamos lo que más nos interesa
y aquí tenéis el espacio.
En la tarta de la famosa tarta de
la web semántica que nos enseñe
en la anterior presentación
aquí tenéis un poco
el espacio que ocupa lo que es
la lenguaje odontológico.
Estaría situado entonces bueno,
algunos presidentes antes un poco
antes de que de hecho este aprobase,
como estándar que previamente
había diseñado,
hubo iniciativas un poco
que era y hoy entonces
un poco estas acabaron fusionando,
dando lugar a un poco.
Aquí tenéis un poco los ejemplos
de antologías concretas
un poco la de la cic también
tenéis la Fe,
Montoro, allí y luego
no sé si os suena.
Bueno, es una especie de deontología
más bien de tipo lingüística
y también la gala en otras
así que son también
por un poco por por dominios.
Otra otras famosas
y decía que creo que había alguna
persona que era un poco más
de documentación de algo así no,
pues seguramente os suene
Dublín Core, pues también es
una antología por detrás.
Hay una antología bueno.
Estos son los proyectos conjuntos,
lo que os comentaba antes de la.
La fusión Dame hoy, el
que acabó dando.
Acabó desembocando un poco
y ya como están dando todo,
esté plenamente aceptado
a partir de dos mil cuatro,
con distintas versiones,
porque ahora está corriendo
un dos, me parece tres,
no estoy seguro, pero vamos ya
obtuvo el estándar por defecto
para parar las antologías,
luego el mismo lenguaje tiene
un poco tres niveles,
o sea, es decir, el folk
por población
a lo que es la unión total
de sintaxis centro.
Sin restricciones y calor no se
garantiza la eficiencia,
ni siquiera la civilidad
porque porque tiene unas
construcciones lógicas
muy muy, muy densas.
Entonces, al final, la que más se
usa y la que vamos a utilizar de hecho,
la que se usa en el proyecto, es
la que se basa en un desfile,
en lógica, descriptiva.
Bueno, aquí un poco tenéis
lo que son,
las características de Google
y tal; tiene la semántica,
bien definida,
las propiedades formales y
garantizan visibilidad,
cosa que no y también
garantizan un poco
la complejidad o sea complejidad;
también también los tiene algoritmos
de razonamiento bien conocidos.
Una antología siempre se le
puede aplicar un brazo
Nador, que son estos,
que podéis ver aquí esto vamos a
jugar un poco también con ello
el viernes seguramente,
es pasarle pasarle un rato a
la antología que hicimos.
Sirve para saber si hay alguna
ansiedad, por así decirlo,
una especie de valor lógico
para para saber
si metimos la pata en alguna cosa
sea imaginar lo que decimos,
que no sé qué.
Vamos a ver qué persona, persona
masculina y persona masculina
decimos que son disculpas, a lo
mejor eso a lo mejor por culpa
de decir que sean disculpas.
En razón, Nador no lo soporta,
ya veremos.
Ejemplos prácticos en la sesión
y bueno, un poco aquí tenéis.
Bueno, tiene distintas sintaxis un
poco lo que nos comente también
para agradecer y todo eso os
tenéis la las distintas.
Sintaxis y aquí tenéis un
poco lo que es la.
La ejemplo de código
de qué aspecto tiene
ahora lo veremos.
Aquí tenéis un ejemplo.
Tenéis estas posibles anotaciones
para parar
lo que son que se pueden aplicar
a los recursos, que creemos
o si tenéis la herradura sirve
para darle una etiqueta.
Es un poco, por ejemplo, lo que
decía de la sencilla realidad,
un poco de si ponemos,
por ejemplo el código iso
ese para España,
podemos ponerle unas redes
en inglés que sea Spain
o podemos ponerle un agradecer,
se la del portugués
que desea España, con NH un
poco eso y luego un poco.
Aquí tenéis lo del comete un poco
lo que es el comentario
de un recurso que se suele
usar para para decir.
Pero ejemplo
para definirlo, no, entonces,
ahí pondríamos lo
que sería, por ejemplo, la
definición de un catedrático de universidad;
por ejemplo, tal como aparece;
o sea, lo normal
es que se incluyan aquí definiciones
un poco, por ejemplo,
si seguramente una definición de
la ley española de universidad
para definir exactamente y sin
que haya duda malentendido,
que haya lugar a malentendidos
de lo que es un catedrático
de universidad,
algo bueno a estas ya son
más de metadatos.
No vamos a decir qué
versión de la la.
La la odontología es o sea,
también para para basa,
para referirnos a otros que nos
puede completar un poco
la visión quien lo define, y luego,
cuando no queremos importar,
por ejemplo, otra antología aquí,
tenéis algunas definiciones básicas.
Un poco aquí tenéis lo Juan que
sería una instancia es un alumno
y luego ya de tipo, o sea,
tiene como nombre
Juan Manuel, tiene como apellidos
Garrido y luego es amigo de Pepe.
No, la instancia PP. Aquí aquí
podríamos un poco esto es un poco
las triplistas que nos comentaba
antes y de los niveles un poco
de cómo es cómo de con posicional
puede llegar a ser también un todo,
lógicamente desde los párrafos de
rsf poco que os comentaba,
y luego también podéis decir
esto lo de las clases,
o sea, por ejemplo, que profesores,
una supuesta de persona,
es decir, no puede haber
un profesor que sea
que no sea persona, por ejemplo,
y lo mismo un poco bueno.
Hay una es un single, es
muy poco para decir,
es la clase, por ejemplo,
es la genética,
o sea, cualquier cosa lógica
de mundo abierto tiene
que ser siempre su clase
de esto ya lo veremos,
porque cuando juguemos
como poco y creamos,
creemos nuestra propia antología,
vamos a ver que siempre vamos
a tener que crear todo,
como su clase.
Bueno, aquí tenéis todos los
tipos de propiedades
que nos habían hablado antes,
cuando son de objetos, relación
a individuos
y cuando son de datos relacionados
un individuo con un valor,
un poco lo que nos comentaba
antes de la edad.
Frente a aquí sería aquí si sí que
sería entre entre objetos,
no voy a dar clase de imaginar que
personas da clase de asignatura.
Entonces, en base a esos individuos
podríamos decir
que cuando clase de biología general,
por ejemplo aquí algunas
de las diapositivas
se repiten un poco con respecto
a la otra, pero bueno,
más o menos íbamos a Giles
no creo que haya problema el
dominio del rango Raúl,
que esto también lo vamos a
ver de manera práctica
el viernes aquí entonces podríamos
definir lo que es el dominio y rango
de una propiedad.
Entonces para la propiedad a clase
de siempre tenemos que decir
que el dominio y el rango
un poco como el sujeto
y el predicado no, por así decirlo
entonces para la propiedad a casa
y siempre tiene que tener un
dominio del profesor,
porque son sólo los profesores
los que dan clase de algo
y luego de rango es se especifica
que sería simple asignatura.
Es decir, un profesor da clases de
asignaturas siempre y no podemos.
Esto sea.
Entonces no podría entrar ningún
individuo que no fuera profesor
ni ningún otro entidad que
no sea una asignatura.
Bueno, aquí podéis también vamos,
también se pueden jerarquizar de
alguna manera las propiedades
y especificar qué?
Que por ejemplo,
esto es padre de su propiedad,
es progenitor progenitor;
sería más genérica porque valdría
tanto para padre
como para madre.
Sin embargo, es padre de ella,
es un poco más específica
que el progenitor,
porque define exactamente la
figura del padre es bueno
y también se podrían.
También existe lo que
son las diversas,
no es padre de la inversa
de ese hijo,
es decir, vamos a la inversión de
la propiedad por medio de otro.
Bueno, disculpas, es que me
disculpas su momento
que íbamos a comentar una
cosa, cinco minutos.
No te voy escribir ahora por privado
Reyes vale, si puede parar
la grabación.
Segundo, mientras sí claro.
Propietarios
Proyecto Hércules
Comentarios
Nuevo comentario

