Una alumna del uno
de la asignatura de Estadística
de Ciencias Ambientales
en este segundo vídeo del tema de
las relaciones entre variables.
Vamos a continuar con el análisis
de regresión lineal
y, en particular, vamos
a ver cómo se hace,
inferencia en este modelo, que
estamos considerando.
En el análisis de regresión línea
recordamos que la situación
que estamos considerando
es el estudio de una relación
entre dos variables,
y si a partir de un conjunto
de observaciones,
desató variable conjunto
de observaciones,
subí y subí en la suposición
que estamos considerando
en cuanto a la forma en que
se relacionan la variable
y la variable que lo hemos puesto
como las suposiciones,
normalidad e independencia,
comentamos en el vídeo anterior
que la modelo que estamos
considerando
que los valores de Kisufim,
que son valores que fija
el experimentador,
son valores que se relacionan
a través de la variable
en la historia y sui esta cantidad
es aleatoria mediante esta relación
en la cual la variable
ley se descompone,
en un trozo que es una
relación lineal,
con la variable más otro trozo,
que es un trozo que es aleatorio
y ese plazo aleatorio,
considerábamos que sería una
distribución normal
de medio hacer o equivalían obstante,
sin más cuadra, comentamos
en el tema anterior
en el día anterior que ese
modelo se puede escribir
de manera equivalente diciendo que
en realidad para cada equis sui
lo valore y suya solo asociados.
Son valores aleatorio,
que tienen distribución normal,
que son independiente
y verifica que su media tienen
una relación lineal
con el valor de la equis y
su alianza constante.
Se recuerda es el ejemplo artificial
que utilice para explicar algunas
de las ideas de este modelo.
La idea era que cada vez que fijamos
un valor de que por ejemplo equis,
igualado los valores de la
variable y son aleatorio
y se comportan como una distribución
norma donde la media
de esa variable normal está
colocada sobre la recta
mas ve que la apariencia de
esas poblaciones normales
son constantes.
Lo que comentamos en un último vídeo,
que lo único que nosotros conocemos
son las observaciones,
lo único que vamos a conocer,
su punto de aquí
y lo que queremos es hacer obtener
información sobre esta recta
y también implícitamente ya veremos
dónde parece eso tenemos que vamos
a obtener información
de sin más cuadra
y a partir de ahí que eso es lo
importante y muy interesante,
nosotros vamos a poder utilizar esta
estructura para lo siguiente,
ya que si yo fijo un valor de nuevo
a partir de la estructura
creo que hemos ajustado
a partir de lo tanto.
Podemos hacer una predicción de
cuáles serán los posibles valores,
de ahí que yo voy a observar
para ese valor
y es aquí donde entra en juego
la inferencia estadística.
Entonces, volviendo a
la transparencia.
La cuestión ahora es que lo primero
que me va a interesar
es ver cómo puedo hacer una
estimación de esos parámetros.
Hay, ve que es un desconocido
recordar
que los parámetros desconocidos
son A, b y se inmaculada,
pues lo primero era ver cómo se
puede obtener una estimación
de esos parámetros,
de acuerdo a las ideas de timadores
que hemos visto en el tema 5.
Bien, en este caso los de ahí debe
no hay que preocuparse o por ellos,
en el sentido de que son ya valores
que nosotros conocemos.
Eso de ahí debe,
vienen dados por el coeficiente de
la renta de mínimos cuadrado,
que ya en el tema de Estadística
descriptiva y lo que vamos a hacer
ahora es recordar las expresiones
que tienen esos parámetros
de la recta de mínimo escuadra.
Entonces para obtener la expresión
de eso, de esa pendiente
y esa constancia en la recta
de mínimos cuadrados
se utilizaba de manera
indiscriminada datos estadísticos,
que son por uno la cobardía; danza,
entre las parejas que subí y subí
o el coeficiente correlación
entre las parejas equis.
Subí y si cuando vi efectos
estadísticos
el tema estadística descriptiva lo
vi como unos estadístico descriptivo
que intenten estudiar el grado de
asociación entre la variable equis
y y aquí lo que vamos a utilizar son
esos estadístico como herramienta
para hacer estimaciones de esos
valores que son desconocidos
en términos de estos estadístico,
lo que parece la renta de mínimos
cuadrados que ha quemado
se pueden escribir de esta forma
Fórmula uno o de esta forma,
formulados en el primer caso,
tenemos el valor de la constante en
la recta de mínimo cuadrado,
que viene en término de de varias
muestras de media,
muestra, no es importante ahora
es la expresión que tiene,
puesto que eso va a calcular r,
sino que seamos conscientes
de que estas expresiones
dependen de estadístico,
muestran que dependen de equis
y di descriptivos,
que dependen de esa de un conjunto
de puntos equis,
subí y subí y, por otro lado, la
estimación de la pendiente
de la renta de mínimos, que viene
dada por esta expresión,
que también depende de esos
estadísticos árabe.
Qué relación tienen estos?
El tríptico descriptivo con
la estimación de aire?
Bueno, pues eso es lo que vamos a
ver en este vídeo en concreto.
Bueno, recordar que con esos
dos valores se construye
una recta que lo que se llama la
recta de mínimos cuadrados
y que nosotros en este contexto
vamos a llamar la recta de regresión
di sobre ello simplemente la
recta de mínimos cuadrado.
Lo que ocurre
es que aquí nosotros estamos
metiendo una información extra,
porque recordar que ahora los
valores de la de los valores de la variable
y los valores de vih que observamos
son aleatorios,
con lo cual esta recta ya tiene
un componente aleatorio
que lo convierte en un estadístico
dentro de la inferencia estadística,
y lo mismo ocurre con estos
dos parámetros
de la recta mínimos cuadrado,
al depender de los valores
de y que son aleatorios se
convierten ahora en estadístico.
La cuestión ahora es ver
si esos estadísticos tienen
alguna buena propiedad
a la hora de estimar,
y la respuesta es que
si lo que veremos
es que es un estimado de mínima
varía de esos dos parámetros,
con lo cual ya tenemos resuelto
el problema.
Aquí simplemente una observación
de acuerdo.
Que toda la construcción
de ahorro y gorro,
así como en la recta de
mínimos cuadrados,
se puede obtener para cualquier
conjunto de pared
de punto.
No, no, no hay ninguna restricción.
Ahora lo que ocurre es que estamos
metiendo el hecho
de que los valores de un aleatorio
y por lo tanto todo valores
que aparecen aquí se convierten en
estadístico y de hecho vamos a ver
que son estimados.
Les vale recordar que los valores
de que no son aleatorios
están prefijados de antemano
antes de observar.
Los valores de y podamos
considerarlo como valores constantes.
Simplemente van a depender como
estadístico de los valores,
y si bien pues entonces la
respuesta a la cuestión
de qué tipo de propiedades
tienen muy sencilla
lo vamos a ver a continuación.
Antes de eso, simplemente
para que lo viera.
Y cómo funciona en este caso
pues podéis ver cómo queda
la recta de regresión sobre
el conjunto de puntos.
Luego parece ser que esta recta
describió bastante bien
el comportamiento,
y lo que voy a hacer es ir a la red
para recuperar el comportamiento
de esa recta de la abstención
de esa recta regresión
eso es algo que.
Dijiste el tema voy a
volver a recuperar.
Entonces recuperando nuestros
vectores de datos.
De acuerdo.
Ante esta opción que aparece
aquí pudimos recuperar
la recta de regresión de acuerdo
éste sería el valor de uso
del término ahorro y
este de aquí abajo
sería el valor del término de
gorro y podemos pintar
y obtener la gráfica anterior a
través de recorriendo la recta
aguarda un gorro a partir
de estos balones
que aparecen aquí los construimos,
los pintamos y obtenemos
la gráfica anterior.
Me acuerdo bien.
Entonces ahora
qué relación tienen estos dos
valores que hemos calculado aquí
con los valores de aire desconocido
de la recta agresión?
Pues lo dicho anteriormente van a
ser estimados indicado de mínima
variar el resultado que asegura.
Eso es un resultado muy conocido.
En la estadística, que se llama
el teorema de caos,
marcó este teorema.
Bajo distinta suposición.
Se obtuvo en Porto matemático.
Nos digamos que los resultados.
Se complementan por dos de los
matemáticos más famoso
entre la probabilidad y como
son Gaos y Marco, y bueno,
caos es uno de los matemáticos más
conocidos de la de las Matemáticas.
En general.
Entonces teorema nos dice que,
efectivamente esa expresión
en un oído de agosto y
me gorro notables
timadores de mínimo.
Hasta aquí añade un término
adicional,
que es el hecho de lineales,
y eso se incluye porque,
excepto o sea, ese valor de, en
realidad se pueden poner
como combinación lineal de
los valores de eso,
y es una cuestión técnica.
La indicó por.
Porque tenga más claro lo
que estoy haciendo,
pero no es determinante para
entender que lo que estamos manejando
son estimado en ese estado
de mínima o alianza
bajo determinadas condiciones que
lo realmente importante.
De acuerdo, este teorema se
podría aplicar incluso
aunque la variable que estamos
considerando,
si no fueran normales.
Aquí estamos suponiendo
adicionalmente que son normales
y por lo tanto sigue siendo
vale acuerdo bueno
pues lo que hace lo que acabamos de
hacer es simplemente justificar
que esos dos parámetros de la
recta mínimos cuadrados,
que ahora se llama la regresión
de y sobre que me producen
dos valores, que es una aproximación
muy buena de los verdaderos valores
de-y ahora una vez que hemos
llegado a este punto,
no vamos a plantear una cosa.
Las dos cosas principales que
nos vamos a plantear
van a ser el modelo anterior.
El parámetro b puede ser 0, no
estamos descartando la posibilidad
de que la constante que usa la
pendiente de la renta sea 0.
Por lo tanto, sería interesante
descartar esa situación.
Evidentemente, cuando nosotros
vamos a dar ejemplo
y vemos la estimación
debe de acuerdo.
Eso nos da una dedicación que casi
seguro que va a ser distinto.
Lo que queremos es hacer, confirmar
que distinto de 0.
Por qué?
Porque si ve fuera cero en realidad
la variable y no tienen
ninguna relación con la variable y
nos podemos olvidar completamente.
Todo lo que vamos a hacer
es confirmar
que la pendiente distinta de 0,
con un contraste de hipótesis, de
acuerdo y la otra cuestión,
es que yo quiero utilizar ese modelo
que estamos construyendo
sobre los datos para poder dado
ahora un valor de cualquiera.
Por ejemplo, en el ejemplo
hemos visto valores
de igual a 0, 1, 25 con 5, 5.
Pues imagina que yo ahora quiero
considerar el valor de 3,
puedo saber yo que le va
a pasar a los valores
de y cuando el valor de xs iguala,
pues eso es lo que veremos a
continuación y en ese proceso
tanto de contestar, si la pendiente
es igual a hacer o no
y cómo puedo predecirlo de ahí en
función de la vamos a introducir
un elemento que es el coeficiente
de determinación,
que va a servir como herramienta
para decidir
si el modelo es suficientemente
bueno para predecir los valores
de y en función de Laiki.
Pero eso será más adelante.
Bien, entonces cómo vamos
a hacer el contraste
de si la pendiente es igual
a cero o distinta?
Pues lo vamos a hacer de
la siguiente forma.
Vamos a volver al ejemplo,
que estábamos considerando
artificial de acuerdo
y vamos a considerar la situación
que estamos abordando,
en la cual nosotros teníamos
esto grande de acuerdo,
y tengo estos puntos de acuerdo
donde proceden de esta variable
y que son nada, y aquí tenemos
una situación muy pendiente,
distinta.
Bueno, por lo que voy a hacer va a
ser algo que os va a recordar mucho
a lo que vimos en el tema anterior,
Dano lo que vamos a hacer,
ver estos valores.
Di en su conjunto en realidad
cómo se comporta.
Es decir, yo lo voy a hacer ahora va
a ser coger todos esos puntos.
Lo voy a juntar en un único conjunto.
Tú y voy a ver qué comportamiento
tiene este conjunto
ahora comparándolo con la situación
en que la pendiente de
fuera igual acero,
es decir, nosotros tenemos ahora
este conjunto de observaciones
de la pendiente distinta,
cero noroeste y voy a compararlo
con una situación
en la cual la pendiente en vez de
ser distinta es igual a 0.
Los puntos, pues ahora
se quedan por encima
y por debajo de la recta
de forma distinta.
Seguimos considerando que
está en este modelo.
La variable son normales
con la misma alza,
solo que ahora la media no cambia
respecto a la medida es constante
en esta situación.
Y voy a coger ahora los puntos
de esta situación.
Y lo pudieran comparar con los
puntos de esta situación fija.
La principal diferencia que hay es
que la movilidad del conjunto
de datos la separación entre los
datos es mucho más grande
que en esta situación, y aquí
ocurre una situación muy
parecida a la que vivimos en
evidente en los vídeos correspondiente al tema
a fijar que lo que ocurre ahora
es en las variables
y hay una variación que proviene
de el factor sima,
cuadrado de acuerdo, puesto que hay
una fase inmaculada en esta
variable,
pues se producen desviaciones
entre la observaciones,
pero ahora, cuando yo introduzco
aquí en la recta un parámetro distinto
de cero por el parámetro expositivo
de la recta,
sube hacia arriba, que
es lo que hace,
separa los puntos.
Cuanto más distinto sea la pendiente,
cuanto más exagerada se la pendiente
más se van a ir separando
los puntos.
Entonces, fijará que en
estas situaciones
tienen que los valores tienen una
variabilidad que depende,
por un lado, del factor sima
cuadrado de la variación que hay
dentro de cada una de las variable
y, por otro lado,
depende de cómo la pendiente de
distintas, cuanto más distinta
de hacer más variabilidad entonces
lo hago me pasó lo mismo que era,
no voy a descomponer la variabilidad
de los datos,
y subí en una parte que proviene del
factor sin y en otra parte,
que proviene del factor b.
Si ve distinta de hacer
esa variabilidad
que proviene debe distintas,
pero se va a hacer grande
en comparación con la variabilidad
que proviene de Sigma Cuadrado,
y a partir de ahí vamos a documentar.
En contraste de hipótesis ve igual
a cero frente a distintos.
Volviendo a la transparencia y ya
entonces lo que vamos a tener
es que vamos a poder contactar
como hipótesis nula
que fue es igual hacer frente a
la igualdad es exacta nativa,
de que ve distinta, y ese contraste
se va a realizar
a través de la siguiente,
de composición,
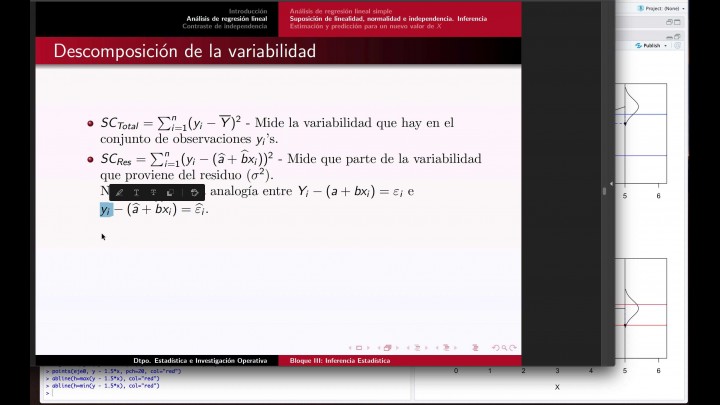
de la variabilidad en concreto.
Vamos a utilizar esta fórmula que
aparece en esta fórmula.
Aparece una serie de términos
que de primera
no está muy claro,
pero que vamos a ir estudiando
poco a poco.
Entonces, vamos a ver cómo
vamos a ir interpretando
cada uno de los términos
que aparece entonces,
el primer término que aparece
aquí esta suma de acuerdo.
En realidad lo que estamos haciendo
fijaron que calcula la diferencia
entre las observaciones
y su media al cuadro,
pues algo denominado en realidad
lo que tenemos ahí en la cuasi
de los datos y sui y eso terminó
lo único que hace.
Es medir la variabilidad que el
conjunto de observaciones
y si la que básicamente ese término
lo que está viviendo
toda la habilidad que hay en este
conjunto de observación
vale ese término, al igual
que en la Nova.
El tema anterior se va a notar por
la suma de cuadrados total.
Pues si volvemos a la
ponencia anterior,
hay otro término aquí un poco
más vamos a interpretarlo
en qué consiste ese término entonces
que termine aquí lo que hace medir
las diferencias que hay entre y subí
y el valor de la recta de regresión
en cada uno de los puntos que subí
sea.
Lo que está haciendo esta diferencia
es que la observación
al respecto de la media de
la red de represión
cómo se comporta y fijaron en la
amplitud de esa distancia,
de quien depende simplemente de
Sigma Cuadrado, cuanto más grandes
e Inma cuadrado más se van a poder
separar esos puntos de la agresión.
De acuerdo.
Así que este término en realidad
lo que está midiendo
es que parte de la probabilidad
proviene de Sigma Cuadrado.
Indicó además que la parte
de la variabilidad
que proviene del residuo, recordar
que en el desarrollo del tema
hemos considerado un término subí
que se sumaba a la renta
y generar valor de, y subí de acuerdo
entonces ese término le
llamó el residuo,
pudo haberlo y fijaron
que lo que estamos considerando aquí
son diferencia entre los valores de,
y subí y diferencia entre los
valores de la recta de regresión
en los que subí.
Es una aproximación de este valor
si no se puede justificar
teóricamente, pero se declaró
que estos valores de aquí
lo que están haciendo aproximar
estos valores de aquí de acuerdo.
Pues bien, en realidad lo que
nosotros estamos aquí haciendo
es una suma de esos aproximaciones
del residuo cuadrado.
Por eso podemos decir que mide
qué parte de la variabilidad
proviene del residuo y recordar
que el residuo?
La magnitud del residuo depende
de su alianza cuanto mayor
sea la fianza, mayor base
del valor del residuo.
Por eso, adicionalmente, ponemos
también que la variabilidad
que proviene de Sigma se puede
decir de una forma
o de otra.
Lo interesante tener en mente
esa dependencia,
porque eso, bueno, vamos a explotar.
En distintos sentidos y después
tenemos un último término
estoy aquí me acuerdo
que lo que hace.
Es medir que parte de la
variabilidad proviene del efecto
que tienen pendiente fijar o que
aquí lo que estamos viendo
es la diferencia que le
entregó a-b o requisó
-vih sea lo que hacemos para acabar.
Aquí no vamos a dar recta venimos
aquí de acuerdo,
y lo comparamos con la media de
todas las observaciones fijado,
que este es el término que
estamos calculando,
y eso le va a marcar la diferencia
que hay de ese cálculo, en este caso
en que la pendiente distinta de cero
en este caso la pendiente
es igual a 0,
puesto que aquí el término.
A Gorman subí puesto que ve 0,
pues ese término prácticamente
borró de acuerdo;
y podéis ver nuevo teóricamente,
y de mucha forma ese término
lo único que está haciendo
es estimar la media de la variable,
así que fijará lo que tenemos.
Es un término que sí ve distinto
de cero marca,
una diferencia muy grande
respecto de la media.
Muestran de la de observaciones.
Pero si ves igual,
acero que este término de aquí
y esté terminado aquí
se tienen que parecer mucho, dijeron
que en este caso valores
que van a salir más se parece
mucho a la media;
muestran y aquí se va diferenciando
mucho más
los valores de la recta regresión
en esos puntos,
así que en realidad este
término se hace grande
si ve distinto, 0, pero
sí ve igual, acero.
Este término se va haciendo
muy pequeño,
así que determinó que parte
de la variabilidad
proviene del efecto que tiene la
pendiente, que es la constante,
el término que propina el residuos
es una demanda de esta forma
como la suma de cuadrados residual,
y la parte que proviene
de la pendiente
se suelen llamar la suma de
cuadrados de regresión,
así que en terminante esa
dotación en realidad
nosotros lo que estamos diciendo de
acuerdo a la fórmula de acuerdo
en la fórmula anterior,
y es que la variabilidad total en
el conjunto de observaciones,
se puede componer una parte
que proviene del residuo
o de la danza,
y en otra parte que proviene de
la pendiente de la recta.
De regresión me acuerdo
y vamos a hacer ahora
un juego muy parecido al de la nueva.
Lo que vamos a hacer es comparar
la variabilidad
que proviene de la pendiente
con la variabilidad,
que proviene del residuo o
variar si este término
es muy grande en comparación
con este.
La idea es hacerlo,
y si este valor es pequeño
en comparación con este,
la idea sería que la pendientes igual
hacerlo en concreto y oyendo a la al
detalle, tenemos que si la hipótesis
una cierta es decisiva,
es igual hacerlo.
La relación lineal con los
que subí desaparece
y, en realidad, tenemos una serie de
poblaciones que son todas iguales
que si mira en la fórmula, tiene
media constante igualada.
El acuerdo por lo tanto en la
media de todos los datos
y es lo que me llamó Ibarra,
así como el valor de la recta de ser
el punto de que soy, es decir,
en realidad son estimaciones
de la media y, por tanto,
la suma adecuado de regresión
toma valores bajos,
por lo que este término y esté
terminado aquí estiman
la misma cantidad y por contra,
el valor de la suma de
valor residual.
Por valores, tanto la variabilidad
de los dato se reparten los términos
que son positivo,
sino un pequeño.
El otro tiene que ser alto.
Como consecuencia, una forma
de identificar,
si el Parlamento ve cero
o no vas a comparar,
eso me acuerdo, y la
forma de hacerlo,
pues va a ser inicialmente tomando
el cociente entre esa cantidades,
siete cociente toma valores bajo,
porque la suma de regresión
es pequeña en comparación,
en la suma,
cuando te represión pendiente
es pequeña en comparación
con la suma de residual, y
entonces la pendiente,
pero si por contra, que cociente
toma balones altos.
Entonces, hay una gran variabilidad
que depende de la recta de regresión
y concluyan que la pendiente
es distinta.
Como ocurre en el tema del del Anova,
es el cociente original, tenemos
que modificarlo
para tener en cuenta el número
de observaciones etc
etc y en particular en este caso
hay que modificar el término
de la suma de color residual
y dividirlo por entonces.
Este cociente
y ha modificado incluimos
abajo, en la, como está
aunque a de todas formas,
lo vamos a renombrar
y tendremos dos términos, que son
el cuadrado medio de regresión
y el cuadrado medio de los residuos
y la interpretación en la misma.
Siete cocientes bajo la pendiente
distinta de 0,
si el cociente es alto,
porque la pendiente, perdón,
si es consciente, es bajo,
porque la pendiente es igual, hacer
y ser consciente es alto
porque la pendiente es distinta.
Bien, en todo este apartado estoy
utilizando el término de Anova
en regresión.
Acuerdo.
Por qué?
Porque seguimos con la situación,
seguimos con la situación donde
lo que estamos haciendo
es analizar la variabilidad
de los datos,
y, por eso, seguimos utilizando
el término Anova,
análisis de la variación al alza.
Lo que hacemos ahora es
ponerle el apellido
de que este análisis de la alianza
es dentro del contexto de regresión.
Bueno, pues entonces lo hubiera
dicho cuando inconsciente,
Antonio tuvo dolor bajo.
Lo identificamos como desigual acero,
y si tengo valores distintos ahora,
como decidimos eso, pues bueno,
ese cociente es un estadístico
y a partir del estadístico
que va a ser un atentado
con carácter calcular,
el valor se calcula a través
de esta fórmula,
aunque nosotros no la
vamos a utilizar r
va a ser el que no de él.
Además, en el cálculo de este valor
y sus interpretaciones,
como siempre, pero valor bajo,
rechaza mucho sucio la
pendiente de hacerlo
y, en caso contrario,
aceptaría opciones
y, por lo tanto, la pendiente de
hacer yo incluyó esta fórmula
y esto por completo, pero ya
sabe que tanto el estadio
como el que va o no va
a dar ahora bien
esa descomposición de la
variabilidad y el cálculo estadístico
y el valor se resumen siempre en
una tabla que en este caso
se llama la tabla del análisis
de la crianza
en el modelo de regresión
y es una tabla similar
a la que utilizamos en la Nova.
Por un lado, tenemos una columna
donde aparece la descomposición
de la variabilidad total en términos
de la variabilidad,
de la regresión y la habilidad
del residuo.
Después se calcula eso valore
fundamentalmente viviendo
la suma de los residuos, el partido
por 1, 2, cuando ya tenemos esto,
el conscientemente determina
la estadística de Contact
a partir del cual se
calcula el valor.
Esta tabla, al igual que
en el tema anterior,
es obligada a incluirla en cualquier
problema de análisis
de análisis, de regresión, línea
de vuelo aquí tenéis.
El esquema y tenéis que reproducirla,
la tenéis que reproducir a partir
de los Valores correspondiente
que obtenga ese y vamos a ver cómo
se obtienen esos valores.
Entonces, volviendo a
nuestro ejemplo,
acuerdo que esa tabla
se puede obtener
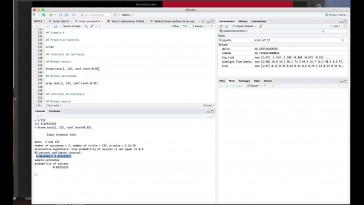
a través de este comando que
aparece aquí parece Anova.
Aquí lo que parece es
que hace referencia
al modelo de regresión,
línea la variable,
y quieren la que hace de entonces
ejecutamos ese valor,
ese comando que obtenemos estatal,
la que aparece aquí.
Esta tabla en la que
tenemos que volcar
el modelo de tabla anterior aquí
tenéis la suma de Regresión.
La suma del cuadro residual, la suma
de acuerdo total no aparece,
pero recordar que se obtiene
como la suma de este valor
y estoy aquí lo tendré que hacer
a mano cuadrado medio.
Aquí solamente tenemos que modificar
la suma de cuadrado residual,
la tenemos que vivir, porque ese
es el valor que se obtiene
el cociente de los cuadrados medios
lo tenéis aquí y aquí
tenéis una indicación del valor
del valor de este problema,
a veces r por cuestiones
de aproximación,
no puede ofrecer directamente
cuál es el valor exacto,
pero sí que puede dar una cota.
Entonces, por ejemplo, aquí
con esta anotación
lo que os indica es que
el valor que es menor
quedó por dos por 10 elevaba
al menos -16 saques,
que se valore es prácticamente
nulo, y con esa información
ya podemos resolver.
Así que toda esta información que
nos da para nuestro Anova en regresión
con nuestro Tato lo recuperamos, lo
volcamos en una tabla que quedaría
de esta forma irregular.
Pero yo recuerdo eso obliga
a incluir esa tabla.
En cualquier ejercicio que resolver.
Bien, pues entonces para
los datos del ejemplo,
la tabla que se obtiene ese día
está simplemente volcado,
los datos anteriores, y aquí lo
único que tengo que hacer
es incluir en la tabla de la nueva
la suma de cuadrados total,
que no viene en la tabla anterior,
pero sí que podría obtener
sumando esta cantidad.
Con esta cantidad, al final fijado,
que dice que del la variabilidad
total del conjunto de observaciones,
y subí 293 con 40,
de las cuales 282 unidades provienen
de la regresión y 10
provienen del residuo, con
lo cual se ve claramente
que la mayor parte de la
variabilidad proviene de la rendición,
y la conclusión, casi segura, va a
ser que la pendiente distinta
lo confirmamos calculando nuestro
estadístico de contraste,
y nuestro pueblo, como
ya hemos dicho.
Pero no era menor que
dos por dos por 10
elevado a menos -16 por tanto, ese
valor es prácticamente nulo.
Va a ser menor que igual que el
nivel de significación que consideramos,
y tenemos que aceptar la hipótesis
alternativa de que ve distinto.
Bueno, pues la parte diferencia
ya lo hemos terminado,
podemos estimar, podemos estimar b y
adicionalmente podemos contactar,
si la pendiente es distinta.
Pero esta tabla no va a servir
para una cuestión adicional.
Porque recordar que el objetivo
último del análisis
de regresión lineal es ajustar un
modelo que me sirva para predecir
el valor de y en función
del valor de la equis,
pero recordar que la variable ley
depende no solamente de la Ekhi,
recordar que nuestro modelo.
En nuestro modelo.
En un modelo volviendo aquí fijado
cuál es la relación de estar aquí
pero no solamente depende de la
equis también depende del residuo
y el residuo que sea, más
grande, más pequeño,
depende de su alianza, es inmaculada,
luego la variable y depende
de la relación lineal,
con términos inmaculada ahora,
aunque la pendiente de
sea, distinta de 0.
Si resulta qué hay una dependencia,
aunque sea distinta de acero baja
respecto de qué depende
más del residuo,
lo que nos vamos a encontrar
es que todo aquí
no va a ser suficiente para obtener
un posible valor de la variable,
y el modelo va a ser bueno cuando
dependa casi todo el comportamiento
de la variable.
Respecto de Ekhi y depende
un poco del residuo,
ahora podemos medir nosotros si
la varita es la variable
y depende mucho o poco de la recta
de regresión sobre aquí fijado,
que ya no estoy intentando comparar.
Qué magnitud de la variabilidad
depende de éste con la magnitud
de la variabilidad que
depende del residuo?
Estoy comparando esto con esto.
Lo que estoy diciendo esto aquí
depende mucho o poco de esto,
pero solo podemos hacer de
forma muy sencilla,
puesto que ahora que nosotros
ya hemos puesto
que ahora nosotros ya hemos obtenido.
Mientras la composición
de la variabilidad
y sé que parte de la
variabilidad total
depende de la regresión y qué
parte depende del residuo,
puedo obtener un criterio?
Pudo determinar un criterio para ver
si el modelo va a ser bueno
para predecirlo, en función de
que observando que parte
de la variabilidad total proviene
de la agresión,
vale entonces en particular
lo que vamos a hacer
es considerar de aquí y
este término de aquí
es un término fijado, que es un
número que está entre cero 1,
puesto que es un cociente
de un número positivo,
y el es siempre más pequeño que
denominado lo que me va
a decir en tanto por 1.
Qué porcentaje de la variabilidad
total proviene de la regresión
y cuanto más cerca de uno
más indicación tengo
de que la principal fuente de
variación de la variable
y la recta de regresión,
y eso me va a llevar a que el modelo
va a ser bueno para predecir
los valores de y en función
de la idea,
está de que quiere decir
que el modelo
vaya a ser bueno para predecir ahora
mismo está un poco en el aire.
Pero cuando pasemos al apartado,
estimación y predicción
prolongó valor de que lo veremos
con más detalle,
vale?
Yo lo que quiere es que ahora
mismo, con esa idea general
de que al final yo quiero predecir
el valor del año
en función del acuerdo, quiero
sabiendo la Ekhi
decir cuánto vale ahí y ahora
necesito medida una forma,
lo bueno que va a ser el modelo para
hacer esa tarea de predicción.
Entonces eso lo vamos a hacer
en términos de 30.000,
lo que parece el coeficiente
de determinación
entonces fijará ese coeficiente
de determinación
como cuando lo multiplicamos
por 100 no va a dar.
Qué porcentaje de la variabilidad
de los datos, de la variable
y están explicado por el
modelo de regresión,
y ese término se conoce como
coeficiente de determinación,
vale.
Simplemente que calcular eso
casualmente y no tan casualmente
ese coeficiente de determinación
es simplemente coeficiente
correlación adecuada.
El coeficiente de coronación
muestral,
que estoy viviendo en los temas
de Estadística vale,
y entonces la forma en que
se usa ese término
es simplemente intentar ver qué
porcentaje de la moneda
ya lo tanto está aplicada por
el modelo de regresión.
Es nuestro ejemplo, el valor de
creciente determinación.
Toma esta cantidad, no lo
tenéis que calcular
Amano hará después recuperaré cómo
se puede obtener de acuerdo
y por lo tanto, que sirva para
atraer lo que me dice,
se terminó tanto por 196 puntos,
cinco por 100 de la variabilidad.
Los datos está explicada por
un modelo de regresión,
y eso me da una idea
de que la variable ley
va a poder predecir,
se bastante bien en términos de
la variable, que es decir.
El modelo va a ser bueno
para predecir la ley en términos
de la función de la variable.
La cuestión ahora es cuando
consideramos que es bueno
cuando malo.
Bueno, pues eso no hay ningún
criterio, pero bueno,
en general se considera
que cuando cociente
determinaciones superior a
9, el modelo es bueno,
porque el 90 por 100 de la
variabilidad de la variable
y depende de que con lo cual
conociendo el valor
de que voy a poder explicar
el 90 por 100 de ahí
y cuando ya nos quedamos
por debajo del nueve
nos vamos alejando hacia cero no
vamos a hacer canciones de 0,
perdón, cuando estamos perdiendo el
modelo como un modelo bueno,
para apreciar los valores de función.
Ahora nosotros hemos llegado un
punto, el paso siguiente
va a ser cómo pudo usar el modelo
para predecir el valor
de y en función de la, pero eso
ya será el contenido del
vídeo tercero de este.
Por tanto lo dejamos aquí
y en la próxima entrega
veremos cómo se verifican las
posiciones iniciales
del modelo de análisis
de regresión lineal
y cómo, una vez que hemos
determinado que el modelo es bueno
para predecir la palabra y en función
de cómo hacer esa técnica
de predicción.
Todos estamos aquí y nos vemos
si no soy un saludo
y cuidaron mucho.