Una alumna de alumno de la
asignatura Estadística del Grado
en Ciencias Ambientales.
Hoy empezamos con este vídeo la
serie correspondiente al tema 7,
sobre comparación de
mates poblaciones.
Los objetivos y contenidos
de este tema
van a ser básicamente,
la de los objetivos
de extender la técnica del
tema anterior al caso,
y, además de mantener poblaciones
y, en particular,
por lo que haremos,
será la comparación de media en
el caso de mayor población,
y también la de comparación
de probabilidades
o proporcione en particular
en este vídeo.
Vemos una breve introducción
a la extensión
de esas técnicas del tema anterior,
casos más de dos poblaciones,
y empezaremos con lo que sería
la comparación de medias.
Entonces, como introducción al tema
no voy a insistir en la comparación
de dos variable o de proporciones
ya lo suficientemente
en el tema anterior,
con lo cual la motivación
sigue siendo la misma.
Lo único que ocurre ahora
es que nosotros vamos a tener esas
comparaciones al caso de Matt
del variable, al caso de Matt,
de sucesos o proporciones
en particular.
En este tema vamos a ver dos
técnicas muy concreta,
muy importante dentro del
análisis de datos
y por supuesto dentro de los
datos medioambientales,
como son el Anova y el contraste
de homogeneidad
en la nueva en la que se utiliza
principalmente para hacer
la comparación de poblaciones.
En realidad eso es utilizar
la técnica,
se llama el análisis de la alianza
y de manera abreviada,
usando su su notación en inglés
se le suele llamar Anova
a veces en castellano, lo
encontraréis también
como como abreviatura de análisis
de la variante,
pero la mayor parte del libro
aparece como Anova, que es la abreviatura
de la terminología en inglés,
que sería ambicioso
varios y, como digo, la otra técnica,
base del contrato de homogeneidad,
que es una técnica
que utilizaremos como la forma de
hacer la comparación de mate
del suceso o probabilidad en la Nova.
Lo desarrollaremos en la sección dos
el contacto de homogeneidad,
lo desarrollaremos en la sección
dentro de la Nova
y de lo que desarrollado
desarrollaron en la sección dos
solamente muy centrada en lo
que propiamente la nova.
Además, hay una serie de
cuestiones relativas
a la verificación de las
suposiciones iniciales,
etc. Que abordaremos en un vídeo
parte, por lo tanto,
en este vídeo me voy a centrar
en lo que obviamente,
el análisis de la variedad entonces,
la situación que se aborden en la
danza es de manera general
muy sencilla.
Simplemente consiste en una técnica
que va a permitir comparar
si la media de población
de cada variable
tienen la misma media o a una pareja
de esas poblaciones son distintas,
que fijaron que de primera
lo único que permite,
como primera aproximación
es ver si son iguales
o si son distintas.
Por tanto, esto es lo que hace es
extender el problema de comparación
de las poblaciones al
caso más general
de poblaciones donde esa población
en pueden ser incluso dos
de acuerdo.
Entonces, si tenemos 2, 3, cuatro
o cinco o seis las que sean,
podemos utilizar esta técnica
para decidir
si la media de esas poblaciones
son iguales
o son distintas el desarrollo del
contraste de desigualdad
de media, en lo que se conoce como
análisis de la alianza,
en este caso simple.
Hay otros análisis de la danza que
tienen otros apellido, simple,
de clasificación, doble.
Con la integración nosotros
en la asignatura solo
vamos a abordar el análisis
de la danza simple
y a partir del desarrollo,
si tuviera necesidad
de otras extensiones, no es
difícil a partir de esto,
pues aprender otra variación del
análisis de la alianza,
con lo cual nosotros nos vamos
a centrar en la nova,
sí?
Bueno, entonces, poniendo
ya detalles concretos
de nuestro estudio, las suposiciones
iniciales
de la nueva son las siguientes.
Nuestro punto de partida son
variables de acuerdo,
tiene nota, no quiso,
uno dos eclipsó,
la cual especifican las siguientes
propiedades.
La variable tienen que seguir,
una distribución normal.
Su media muy subí no tienen
por qué ser igual,
de hecho son el objeto
de nuestro estudio
y una suposición adicional
muy, muy importante,
es que vamos a suponer
en nuestro análisis
que la apariencia de la
variable son iguales,
son constante.
Esa constante a denotar, esa
igualdad de varias poblaciones,
se suele conocer cómo o Mocedades
tipicidad de la variable,
con lo cual nuestro punto de partida
son variable con distribución normal
o Mocedades tica comedia.
En un principio no tiene
porque ser iguale,
pero sí que es verdad que la medida
inicialmente son desconocidas
y de Puebla.
Otra suposición importante
es que las variables que subí
son independientes.
Por tanto, esta técnica lo
que hace es entender
lo que hacíamos en el caso de
muertos independiente,
al caso de más de dos variables
que son independientes.
Por tanto la no, que la nueva no
va a suponer una extensión
de la comparación de media cuando
estamos en el caso de muestras
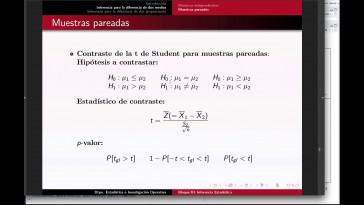
paredes existe una nuevo para ese
caso la muestra variada,
pero nosotros por cuestiones de
tiempo no lo vamos a poder ver,
con lo cual el problema que
estamos entendiendo
es el caso de comparaciones de
media de dos poblaciones
que son independiente.
Al caso de más de dos poblaciones
que son independientes bien el en Anova
como objetivo tiene contratar
las hipótesis que aparecen
a continuación como hipótesis
nula lo que considera
es que la media de esa variable
son igualen.
Frente a la hipótesis alternativa
de que hay una pareja,
no sabremos cuál.
Es decir,
el contraste nos permitirá decidir
si son iguales, son distintas,
pero en el caso de que sean
distintas no nos va a decir
cuál puede ser alternativa,
lo que tendremos,
que nos dirá que por lo menos
hay una pareja no sabemos
cuál en las cuales un medio
son distintas,
con lo cual no habrá igualdad
entre la variable.
Bien.
Entonces este análisis de la
variedad para poder llevarla a cabo,
recordar que lo que nosotros estamos
considerando, repito,
son una serie de variables,
con distribución normal,
con la misma comedia que
pueden variar o no,
que son independiente
y a esa variable
lo que hubiera ser aplicable
en la nueva para contratar
como hipótesis que la
medida se iguale
frente a que haya una pareja
que sea distinta,
como llevamos a cabo ese
análisis de la danza,
como llevamos a cabo este
contrato hipótesis,
pues, como siempre, tomando muestras
de cada una la variable,
entonces te cuenta que
lo que vamos a hacer
es entender el problema que teníamos
de dos muestras para dopar,
el que soy independiente, que
sería esta situación.
Aquí tendríamos dos muestras por
separado, independientes,
con conjunto de individuos
distintos con tamaño.
Demuestra que no tienen, porque
coincide al caso general,
en el cual en vez de tener solamente
dos variables tenemos
le gustaba ser nuestra
situación de partida
para hacer el contacto de
hipótesis anterior.
Vamos a hacer ahora va
a ser un ejemplo
con el que vamos a ir ilustrando
la de la técnica de la nova,
a la hora de calcular bien.
En este ejemplo se plantea
la siguiente situación
que la de detectar si
cinco laboratorios
ofrecen los mismos resultados
a la hora
de analizar el contenido muestras
de una determinada sustancia.
Entonces se envían muestras
preparada con el mismo nivel de concentración
a los cinco laboratorios.
En total se envían tiempo, muestra
cada laboratorio,
y los resultados que se obtienen,
pues son los que aparecen fijaron la
diferencia entre este ejemplo
y el que hicimos en el caso donde
planteamos la realización
de contratar al caso parada,
porque no se podía garantizar la
homogeneidad de las muestras.
En este caso la muestra
sí que son homogéneos
fijar que se envían muestras
preparadas
con el mismo nivel de concentración,
con lo cual no hay ningún problema.
La muestra son homogéneos
y se pueden enviar muestras
independientes
a cada uno de los laboratorios.
La idea es ver ahora si
estas mediciones,
que provienen de una variable,
tienen el mismo comportamiento
estadístico o no,
y eso es lo que resolveremos.
Con el análisis del.
Volviendo a las suposiciones,
en nuestro caso de acordar
que tenemos que identificar
cuáles son las variables
que maneja esta variable y
si las identificamos,
sería el nivel medido
por el laboratorio
y donde el valor ley puede
ser un laboratorio
o el 2, tres o 4, 5.
Esos niveles medios
por cada laboratorio son lo
que lo notaremos por XP,
y nuestra suposición de partida
que la variable
son una distribución normal.
Todas tienen la misma zona
de acción típica
y son independientes entre sí
y nosotros lo vamos a hacer
con la nueva base contratar si esas
cinco de los cinco laboratorios
son iguales de acuerdo
frente a la hipótesis alternativa
de que existen, por lo menos
-2 laboratorios,
en los cuales sus medidas
son distintas,
lo cual nos llevaría a pensar
que, concluir, mejor dicho,
ha caído el laboratorio, que ofrecen
mediciones distintas
y no son homologables.
Los resultados de uno otro.
Bueno, pues para ilustrar
esto voy a recuperar
los datos que consideraron
anteriormente de acuerdo y lo dato
lo primero que tendremos que hacer
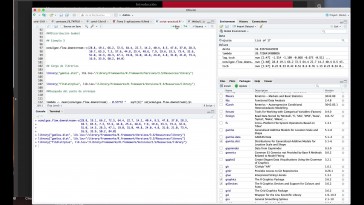
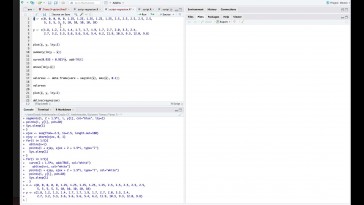
será introducirlo en un vector
de datos que yo haya llamado
a sus vectores de datos.
La 1, La dos La la cuatro cinco
ocurre lo siguiente.
Esta presentación del dato
no es suficiente
para poder hacer el análisis,
en concreto,
para poder hacer el análisis con r
necesita que todos estos datos
estén introducidos en un único
vector de acuerdo todo correlativo,
siguiendo una detrás de otro,
y además necesitamos crear
un vector adicional que
lo que llamaremos
un vector de factores en el
cual esté identificado
cada una de las observaciones
del conjunto total
que vamos a considerar identificado
al laboratorio,
pertenece cada 1.
Bien,
vamos a ver cómo se pueden
construir esos lectores.
Es muy sencillo, aquí voy a ponerlo.
En primer lugar, hemos creado
un vector donde están
todas las observaciones,
ese método nuevo
lo llamamos dato punto ejemplo
uno lo único que he hecho
ha sido con los datos del laboratorio
uno con los laboratorios laboratorio.
Entre el laboratorio, cuatro
el laboratorio,
cinco de acuerdo.
De hecho, si nosotros vemos ahora
ese vector de datos fijado.
Sí sí si, como ha quedado
su veto de dato fijado,
que tanto los datos del 4,
el 13, cuatro o cinco tanto
están consecutivo
y al final tendremos 50
observaciones ya,
lo que necesita otro vector,
que ya manifestó de factores
donde vaya diciendo
en orden a qué laboratorio pertenece
cada una de estas observaciones
que aparecen aquí evidentemente
las 10 primeras pertenecerán
al laboratorio.
Primero la 10 siguiente,
pues pertenecerán al laboratorio;
segundo,
al día siguiente al tercero
y así sucesivamente.
Así que yo necesito crear un vector
de factores donde de alguna forma
tenga indicado que la primera
son del laboratorio,
primero la segunda de laboratorio
segundo, y así sucesivamente.
Entonces, la forma de
crear ese momento
de factores mediante comandos
que aparece entonces
la función que permite crear el
vector factores y secta,
y lo que he hecho ha sido
después ese método
de factores dando nombre sobre
todo de factores.
Le voy a llamar la así
que en ese vector de factores
la voy a meter,
esa identificación de donde procede.
En cada una de las observaciones
de vector anterior,
donde están todas las observaciones
de la cuenta que ahora mismo
aquí no hay distinción
de laboratorio,
pertenece a cada 1, con lo cual
necesitamos identificar
entonces la función que permite
generar ese método
de en lo que se llama
la función factor,
y entonces la función factor fijado,
que lo que hacemos es introducir
los argumentos,
que eso.
El segundo argumento, más sencillo.
El segundo argumento es un vector
donde nosotros digamos,
escribimos como quiero etiquetar
la observación,
podemos elegir etiqueta
de todos los tiempos,
a veces un 2, 3, cuatro o 5,
como que yo he elegido como
etiqueta llamarle,
identificar si son de un laboratorio
otro como La 1,
La 2, La cuatro cinco de acuerdo,
fijará que tenemos que ponerlo
en el mismo orden de acuerdo
en el que hemos introducido o los
cinco vectores anteriores.
De acuerdo no tienen por
qué coincidir Agüero
fue claro que yo he puesto
una letra mayúscula.
Podría haber puesto a
de lo que ocurre,
que si lo ponemos con La 1,
la, la, la cuatro la 5,
después los resultados que vamos
a ir estudiando son más fácil
de analizar, porque la etiqueta hace
referencia a las variables
que estaban manejando simplemente, y
aquí ahora lo que tenemos que hacer
es decirle cuántas veces cuanto
a cuántos factores distintos
tengo que crear y cuánto tengo que
repetir cada uno de ellos.
Entonces eso se hace
con este argumento
que aparece aquí entonces, en
este documento que aparecen
y que en lo que hago lo
que hago es decirle
que yo voy a tener que crear
cinco factores de juego.
Ese será el número de variable
que en general
hemos llamado, que estamos manejando
nuestro ejemplo
y después aquí lo que tenemos
que hacer es con un vector
y manteniendo un orden con
el que hemos creado
con vectores anteriores.
Decirle cuántos observaciones hay
de cada uno de los vectores.
El laboratorio uno 10,
pues en primer lugar, por
10 del laboratorio,
ponemos aquí 10 así sucesivamente.
De acuerdo fijado para
poder hacer efecto,
vosotros tenéis que ir a
los vectores de datos
y ver cuál es el tamaño.
Muestra de cada uno de ellos lo ve.
Entonces, como paso previo,
tenéis que ver cuántas observaciones
hay en cada uno de los casos
para ir poniendo correspondiente
otra forma de evitar ese problema.
Lo que pasa es que el comando
sale mucho más largo
y ya en cuestión de preferencia.
Es simplemente decirle que el
número de repeticiones
que vayan en la etiqueta
se corresponda.
Se corresponde,
se corresponda con la longitud
del lector correspondiente.
Si aquí tengo que poner cuanto antes
dato hay en el vector la Bono,
pues puedo decirle directamente.
Aquí me introduzca como valor
la longitud del lector
y tendría que hacer eso con
todo lo que aparecen
en el recuerdo.
Tercero.
El cuarto.
Que lo tendríamos que construir
de esa forma
cualquiera de los dos métodos.
Es decir,
que si hacíamos la generación
vector de factores,
está bien de acuerdo y le
pedimos que me digan
cuál es, que me diga cuál es
ese lector de factores,
fijaron que con el primer método lo
que hace repetir en la q1 10 veces
el acto 10 veces y así sucesivamente
de acuerdo,
si lo hubiéramos hecho con
esta institución de aquí
de acuerdo con esta institución.
Aquí tenemos lo mismo.
Si yo te digo que me diga
ahora ese lector
ese es el nombre es el mismo.
Solo que he cambiado cómo
se construyen?
Tenemos la misma situación que de
acuerdo, lo único que ocurre
es que te más sencillo, pero estoy
aquí arriba más sencillo
y estén más largo de construir.
De todas forma, como el ejemplo
que voy a hacer,
o el tamaño de muerte está indicado
y muchas veces suelen ser iguales
o los tamaños de vuelta,
son muy sencillo de identificar a
partir de los datos del ejemplo,
directamente podéis poner
cuál es su tamaño aquí
y evitar escribir todo esto
que aparece algo bueno
ahora que cuanta más largas
son las instrucciones,
más posibilidades tienen de arroz
en la construcción del comando
y más problemas pueden tener.
Entonces la sesión más sencilla
sería estar aquí y después
otra versión que se pudiera utilizar
en otras situaciones.
Nos muestra más difíciles
de identificar,
pues lo podéis construir Teresa Bono
entonces para hacer nocturnas;
y si no solamente vamos
a necesitarlo;
dato, porque eso va a ser una
cuestión importante.
Los datos necesitamos tenerlo
en vectores individuales
y en un vector agrupe o agrupado
junto con su vector
de factores necesitar; es otra forma,
cuando ya tenemos hecha esta
construcción de los dos formatos
de los datos podemos ver pasar
a hacer nuestro bien.
Una primera aproximación sencilla
a problema es la siguiente.
Puesto que yo tengo datos
que son normales,
proviene del supuestamente
distribución normal.
Tengo que las medias
muestran de mínima
María de la media de cada variable,
así que ello podría tomar
la media de cada
una de las variable y calculadora
como una primera aproximación
para ver cuál es el comportamiento
de la media de esa población.
De acuerdo.
Entonces se cuenta en este caso.
La media es un cuatro con tres
con 97, cuatro con 46,
valores que están en torno al 4.
Entonces, en un principio
podría ser parecido,
pero fijaron que aquí aparece
una media de puntos, 12,
una medida que el punto de 24,
que se alejan mucho lo adecuado.
Luego si éstas son aproximación
a las medidas reales,
seguramente lo que va a ocurrir es
que la media de esos variables
que estamos considerando
son distintos.
Lo que vamos a hacer ahora es
confirmar estadísticamente
que hay diferencia con un
contrato hipótesis,
usando la técnica del análisis
de la variedad.
Bien, pues lo que voy a
hacer para ilustrar
cuál es el procedimiento que hay
debajo de la comparación
de media voy a utilizar un ejercicio
bien utilizado,
tanto artificiales para que
ve en qué consiste.
Bien, entonces lo la situación
en general
que nosotros estamos planteando
en esta situación.
Es una situación en la cual tenemos
una serie de variables
que son normales, de acuerdo y de
los cuales cada una de ellas
lo que hemos hecho es obtener
una muestra.
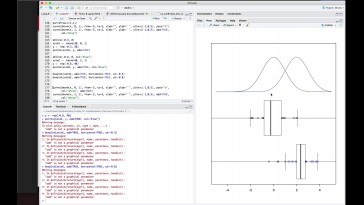
Así que, por ejemplo, aquí
tendríamos una primera variable normal
con su medio y lo que hacemos es
sacar una muestra de ella
tendríamos una segunda
variable normal.
La media puede ser distinta
de acuerdo,
su media no tiene por qué coincidir
con la anterior
tendríamos un muestra correspondiente
y eso serán los datos que tenemos
y por último, tendríamos.
Otra variable con distribución
normal de acuerdo con su medio
y con su muestra aleatoria, fijará
que en en esta situación
solamente consideran el caso para
que haya más de dos de acuerdo
y sería una situación similar
a la que hemos visto.
Vale?
Entonces la cuestión ahora es
que nosotros desconocemos
la posición de esa distribución
normal,
porque no sabemos cuánto vale su
media en ninguno de los pasos.
Ahora lo que queremos ver es
si esta muestra me dan
evidencia suficiente para señalar
que la media son distintas
o, por el contrario, no hay
evidencia suficiente
y tengo que considera que
las medidas son bueno,
pues cómo vamos a hacer esto?
Pues lo vamos a hacer de
la siguiente forma.
Recuperar el ejemplo.
Estamos jugando bien.
Vamos a hacer lo siguiente.
Voy a coger todas las observaciones.
Y la puede juntar en un único
conjunto de datos,
es decir, voy a coger todas
esas observaciones.
Y lo pudo poner junta en
un único conjunto,
parece yo haga lo que voy a hacer,
más a ser comparar esta situación
con la situación en la que
todas las medidas
son iguales imaginar que en
vez de ser la distinta
la media hubiesen sido igual.
Esa situación sería la siguiente,
tendría una primera volea consumo,
hasta tendría una segunda
variable con su muestra
y tendría una tercera variable,
consumo, es decir,
habría adjuntado verticales
en la misma posición
a donde aparece aquí y lo
que hago es comparar
esta situación con estar aquí
hacemos lo mismo de antes, me hacía el base
apuntar todas las observaciones
en un solo conjunto.
Es un punto rojo que aparecen aquí
y esta, las dos situaciones
que tenemos.
Si las variables tienen
medidas distintas,
tendríamos esta situación
y si la variable fueran iguales
en cuanto a su media,
tendríamos esta situación.
Si bien la diferencia fundamental,
cuando miramos el conjunto total
de observaciones cuales fijaron
en este conjunto conjunto
con otro rojo y el conjunto
de puntos azul,
cuál es la principal diferencia?
Que ve bien, pues básicamente la
principal diferencia que vemos
es que en este caso las
observaciones están más dispersa.
Hay una mayor variabilidad
en este caso,
y en este caso hay una menor
variabilidad de acuerdo,
porque en un caso hay
más variabilidad,
y en el otro caso hay
menos variabilidad,
pues, por lo siguiente fijaron que
intrínsecamente dentro de cada
una variable.
Hay una variabilidad de acuerdo,
es inevitable,
porque la variable tiene
una danza que positiva
la que sea, 1, 2, tres la que sea,
y eso es lo que hace que
función normal,
pues tengo una amplitud, y eso es
lo que hace que se separen,
la observación de esa distribución
normal.
El hecho de que cada una
de estas variables
tiene una manera positiva,
pero esta situación,
que también ocurre aquí no es
suficiente para explicar
la variabilidad que hay aquí y
aquí también hay viabilidad
y la variabilidad también proviene
de esa diferencia de perdón,
de esa variedad.
Dentro de cada la variabilidad,
en este caso no solamente proviene
de esa variedad,
sino también proviene del hecho de
que las medidas son distintas.
El hecho de que la media,
en unos casos,
se desplacen hacia la izquierda
o hacia la derecha hace
que la observación aquí
en conjunto total
se separe, mientras que
aquí esa separación,
por la diferencia de la
media no aparece.
Simplemente aparece el
efecto de la marea.
Luego la principal diferencia entre
esta situación ya está aquí
es que aquí en la variabilidad
del conjunto total
de observaciones sólo
aparece la variedad
y la variabilidad que aparece
aquí aparece la alza,
más el efecto que tiene que las
medidas sean distintas,
fijaron que esta situación
es la hipótesis nublan,
y esta situación en la hipótesis
alternativa,
con lo cual decidir si estamos
la hipótesis nula
o la potestad alternativa
se va a poder concluir que
se va a poder decidir
en qué situación estamos a partir
del estudio de esta variabilidad,
y ver si en la variabilidad aparece
el efecto de una posible diferencia
entre la media sin la variabilidad
de los datos aparece
que hay una variabilidad que
proviene de una posible diferencia.
Diré que las medidas son distintas.
Si la variabilidad no
aparece el efecto
de la diferencia entre la entonces,
diré que las medidas son iguales.
Entonces, cómo podemos llevar a cabo
ese análisis de la variabilidad?
Bueno, pues para hacer la discursión
de todos los análisis
de la variabilidad, necesitamos
previamente
una serie de anotaciones teóricas
para explicar,
así que ahora mismo vienen un
poco de desarrollo teórico,
pero necesario para poder explicar
cómo decidimos si estamos
en una situación, vamos a volver
a la transparencia.
Entonces, pues bien, de la
transparencia vamos
a empezar a fijar una dotación.
Recordar que la situación que hemos
planteado anteriormente
es que tenemos una serie de muestras
de cada una de las variables.
El tamaño de muestra de cada
una de las variable
lo hemos derrotado por
su jota de acuerdo
y con anotación general.
Esta anotación en una donación
están dentro de la Nova,
no solamente la voy a desarrollar
aquí sino que usualmente,
aparece en cualquier libro donde
se trate el tema Sí
que es una noticia bastante bueno,
pues entonces el tamaño de cada una,
la muestra pone poner su jota,
tendremos quienes un insulto a
quienes y el total de observación,
será la suma de esos, tienes
ojos del lado humano,
tan por 1.
Así que, el número de
observaciones total
es que aquí de acuerdo
es en mayúscula,
en nuestro ejemplo, el valor de 50,
en total teníamos 100.
Observación, 50 observaciones.
Vale recordar que la observación
se nota por su hijo.
Tiene 2.
Su primer, su índice,
indica qué lugar ocupará la
observación en la muestra
y el segundo.
Su índice indica a que población
pertenece a la muestra,
con lo cual, la observación
XP y j va a ser el dato
y simo de la muestra de
la población js.
Por ejemplo, insulto.
3.
La observación segunda de
la población tercera.
Bueno, todo a partir de estos
valores podemos calcular la medida,
mostrando el dato de cada
una de las poblaciones.
Lo único que tengo que hacer
es calcular la media.
Mostrar de las observaciones
de esa población junta
y dividir por su tamaño.
Le muestra fijado, que lo
que tengo que hacer
es recorrer toda la muestra
para los valores,
que tiene el segundo j.
El segundo es un indicio es decir,
que eso no es emocionante de la jota
y lo que hago es hacer
todas la suma de lo
y uno hasta su jota bien,
esa media muestra de la población
de cada variable
se van a notar de esta
forma, como siempre.
Barra de acuerdo,
y después se le va a añadir
2, que son sus puntos j.
De acuerdo.
El índice j corresponde a
la variable población
de la que considera la modesta
y el psuv, índice punto
para indicar que hemos humo
respecto de la primera,
coordinada acuerdo.
Ya digo.
Esta anotación es bastante común,
simplemente añadirle un
puntito delante de j,
igual que hemos hecho en otros
casos, en barras hubo 1.
Por lo que vamos a hacer,
añadimos el puntito.
Vale?
Ya digo que se podría dejar el equipo
Hadj simplemente, pero por mantener
la anotación estándar
que aparecen muchos libros,
lo vamos a dejar así
una vez que tenemos eso también
puedo calcular
la media de toda la observación,
es decir,
con todas las observaciones,
cálculos de acuerdo en el ejemplo
sería coger los datos de
las 50 observaciones
y calcular su media bien.
Entonces, cómo se calcula?
Pues lo que tengo que hacer es sumar
todas las observaciones
y dividir por el total de
observaciones que hemos llamado
anteriormente, en mayúscula.
La suma de todas las observaciones
se nota por su punto,
por punto punto.
Es una anotación.
La asumimos y seguimos para
adelante y la media
mostrando todas las observaciones.
Se nota por equipar Navarra,
su punto a punto,
pero esta sería la media de
todas las ovaciones,
la anotación común que se suele
dar a esta media del total
de todas las observaciones de agua.
Entonces conecta anotación
al recordar
que anteriormente hemos calculado
la media de cada laboratorio,
cuando lo que hemos hecho
es calcular,
que hemos calculado la media por
cada uno de los laboratorios,
pues a nuestro ejemplo lo que
tendríamos que, por un lado,
la media de cada muestra
por separado,
eso sería, por ejemplo, en
este caso para su punto,
equipar sus puntos y
equipar sus puntos
y después tenemos también en
el cálculo de la media,
de todas las observaciones que lo
que me llama equipar barra
su punto.
Bueno, pues con esos valores ya
más vamos a hacer el análisis
de si las medidas son iguales
o distintas.
Fijar una primera cuestión si
estamos en esta situación
aquí abajo, barra, punto
uno a punto de.
Vienen a estimar el mismo
valor de acuerdo,
con lo cual eso te sería
muy parecido.
Pero no solamente eso, es que fijaba,
que si yo me fijo en todas
las observaciones
todas las observaciones
pueden entenderlo
como una muestra mucho más grande,
pero de la misma variable,
puesto que no hay distinción
entre la variable,
como si yo estuviera juntando
en una sola muestra toda
esta observación.
En una muestra más grande
de la misma variable,
luego la media muestra el
conjunto observaciones.
También el mismo valor, que
ocurriría entonces,
puesto que repuntó uno equipar
a punto entre barra.
Punto punto, estiman del mismo color
eso que deberían de ser parecidos.
No es lo mismo que esta situación,
de aquí sí calcula la media muestra
de este conjunto observaciones,
evidentemente va a ser distinta, muy
distinta de la media muestral
del total de observaciones.
Así que una primera idea es que
si la media son distintas,
estas cuatro estimación
sean parecida,
pero sí son distintas y diferencia.
Entre esas cuatro estimaciones.
Bueno, como he dicho, la comparación
de la medalla se va a reducir,
a analizar cómo en la variabilidad
de este conjunto de observaciones.
Por eso la técnica que permite
distinguir diferencia
entre las medidas se conoce como
análisis de la danza,
porque lo que hace es analizar
la variedad
o la variabilidad del total
del conjunto de datos.
Cuando juntamos todas
las observaciones
en una única base, entonces, cómo
analizamos esa variabilidad?
Pues lo vamos a hacer de
la siguiente forma.
Buena anotación.
Yo puedo medir la variabilidad
o la danza.
De este conjunto, observaciones
puedo calcular perfectamente,
muestra su danza muestral
es simplemente la suma
de la diferencia
entre las emociones, menos
un ere ha cuadrado,
y me estoy refiriendo al
conjunto de Barcelona,
donde, junto a todas las
muestras, una sola,
vamos a analizar su variedad a
su variabilidad de entonces.
Con esta dotación que hemos fijado
la marea onza se ha denominado
se vierte al presidente,
aquí alguien tiene la suma
de la diferencia
entre las observaciones y su media.
Al cuadro le falta al término
del tamaño de datos,
pero ahora mismo es solo,
como bien de acuerdo.
Entonces esto no me diría
la variada zanahoria,
habilidad de todos los datos
que aparecen en ti.
Bueno, para esa variabilidad
se tiene una identidad que se puede
desarrollar matemáticamente.
Nosotros no vamos a hacer
que la siguiente,
y es que esa alianza variabilidad,
fijar este número es un
número positivo,
puesto que es una suma de cuadrado.
Se puede escribir, como la
suma de este término
y más mal la suma de términos
que aparecen.
Bueno, fijar que tanto él como
este término son positivo.
Lo que estamos diciendo
es que va a variar la variabilidad
de los datos.
Se descomponen, dos términos
que son positivo
y ahora tienen lo que mide cada uno
de estos términos positivos
que aparece aquí puedo fijarlo
en este término que aparece,
que lo que estamos viendo es
la diferencia que hay
entre la media muestra y la media
total del conjunto de observaciones;
es decir, estamos viendo
la diferencia
que hay entre medias muestra
la medida muy grande.
Aquí entre esta medida muestran
la medida muy grande aquí
y entre también muestran
la media muestra
de aquí que hemos dicho
anteriormente que si la media son distintas,
la diferencia van a ser notable.
Por lo tanto, esa diferencia del
cuadro son unas cantidades grande
y si por contra, la media son igual,
estos valores de media muestra se
van a aparecer a la medida del total,
con lo cual la diferencia entre
las medidas actuales
y la medida total va a ser pequeña.
Así que efecto práctico.
Si hay diferencia entre la media,
esta diferencia del cuadro grande
y este término se va a hacer
bastante grande,
pero si no hay diferencia
entre las medidas,
estas diferencias pequeña
y, por tanto,
la suma de esa diferencia va
a ser un número bajo,
ya que tenemos en este término
de aquí fijaron
que aquí lo que vamos haciendo en lo
siguiente lo que voy haciendo
recorre cada una en la
población el mover,
y de una tacada, lo que enciende
y recorriendo la variable 1,
la doble hasta la calle dentro
de cada una variable.
Lo que hago es tomar la diferencia
entre sus observaciones y la media,
mostrar que eso es algo una
constante en la cual la María Zabala
de cada una de las muestras
de la variable.
Así que, salvo la constante
del denominador,
ese término lo que está haciendo es
coger la crianza de aquí la danza
aquí aquí y sumar ahora fijarlo.
Bien, ese término en esta situación
y ese término de esta situación
va a ser muy parecido
que lo estoy haciendo calcular,
la y la danza.
Aquí la variabilidad cambia
de población,
no porque todas las poblaciones
tienen la misma Lugo,
ese término se va a comportar igual,
tanto si la variable son
variables distintas,
como si las variables tienen.
La misma media ha variado en
cada una la situación
es la misma, con lo cual este
término que aparece aquí se comporte
de la misma manera.
Tanto si la media son iguales,
como si las medidas son
distintas nuevo
aquí en este término, lo
que hago lo siguiente.
Cuando analizó la variabilidad
de todas las observaciones
hay una parte que proviene
de Sigma Cuadrado,
del efecto que tiene Sigma cuadrado
hacer que mis observaciones
se separen dentro de la muestra
y otra parte que proviene
de la posible diferencia
entre la media
se diferencia este término
se hace grande
y sin diferencias.
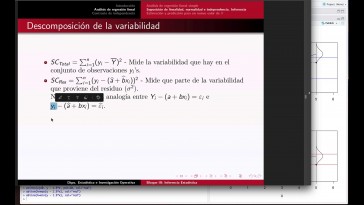
Así que, en resumen, lo que
tenemos es lo siguiente,
que es que, en primer término,
en la variabilidad
de todas las observaciones mide
la variabilidad total
en el conjunto de las observaciones,
de manera general,
ese término se le suelen dar por ese
total la suma de cuadrado total
y se escribe de manera inmediata
de esa forma.
Ya digo esto en una anotación común
en todos los libros de Estadística.
El siguiente término que hemos visto
en la composición anterior
era el que la diferencia entre
las medidas muestras
de cada muestra y la media, mostrar
de todas las observaciones,
pues lo que hace medir la parte de
la variabilidad que provienen
de las posibles diferencia muy
importante que hay entre la media
esa suma se le llaman a su madre
cuadrado entre de acuerdo entre grupo
y se suelen anotar.
De esta forma, y ya en último término
lo que tenemos es lo que llamaremos
la suma de cuadrados,
dentro que lo que hacen medir la
parte de la variabilidad total
que proviene de la fase inmaculada,
pueblo y esa variabilidad,
pues denota por Efe.
Así que, en resumen y esto es lo
que tienen que quedar claro,
es que la variabilidad total de las
observaciones se descompone
como una variabilidad que proviene
de la posible importante posible;
diferencia entre la media y
otra parte que proviene
de la manejabilidad dentro de las
poblaciones que está marcado
por la variedad Simón.
Esto es lo que tienen que
tener en cuenta,
no podía pedir que aprenden ninguna.
Esta fórmula de desarrolla la
fórmula para que veáis
cómo se puede ver cómo se interpreta.
Pero al final lo que tiene
que quedar claro
es que en estos problemas yo
puedo aplicar una fórmula
para analizar qué parte
de la variabilidad
proviene de la posible diferencia
entre la media
y qué parte proviene de la alianza
y a partir de esa descomposición
voy a decidir si estoy
en esta situación
aquí o esta situación
en esta situación.
De aquí el término de ese centro
tendrá que ser alto
y en esta situación de aquí el
término ese centro va a ser bajo
y a partir de esa desgana,
razonamiento es cómo vamos a
realizar el control de árabe?
.
720
00:40:15,520 --> 00:40:15,980
Lo que hacemos, básicamente,
es comparar esos valores
de la descomposición.
Yo voy a comparar el accidente
con el de dentro y la idea
en la siguiente.
Si hay una diferencia entre
la media de balón
se va a hacer grande y, por lo tanto,
va a ser alto en comparación con
ese fin, dentro de acuerdo,
y al revés.
Si no existen diferencias, este
término se va a hacer pequeñito
y va a ser que se hace grande.
Que la variabilidad constante
en la muestra,
la variabilidad constante, ya nunca,
voy a repartir las dos términos,
si unos grandes, porque el
otro se hace pequeño.
Luego, si ese centro se hace grande
porque se queda pequeño, y
si ese centro pequeños,
porque se cee dentro, se hace grande.
Entonces, lo que hagamos para eso
termina ver dónde se desplaza más
la variabilidad, seas, si hacia
ese centre o hacia ese centro
de acuerdo, a cómo puedo comparar
esa dos cantidades,
pues una forma sencilla
es simplemente coger
el cociente de Soto, el número,
si de ese accidente, y ese centro,
pues, lo que tendréis que
cuando esté consciente,
se haga grande, valores
mucho mayores que 1.
Porque éste terminó legando el
de abajo y, sin embargo,
si el cociente se hace bajo
porque ese dentro le gana
y a partir de ahí puede decidir
si las medidas son iguales
o son distintas.
Lo que ocurre es que por una
cuestión de tipo técnico
y por una cuestión que no hemos
abordado antes, que era la fórmula,
no hemos dividido por tamaño, te
muestra esa tamaño de muerte
que incluyeron, la discusión hay
que modificar ligeramente,
se cociente para poder llevar a
cabo el contrato de acuerdo,
sea consciente dentro hay que
modificarlo, aún así;
la interpretación sigue siendo
entonces como la modificación,
pues la modificación en la siguiente.
En vez de considerar ese
excedente tocado,
considera ese centro del
partido por caminos.
Todo lo que hace tener en cuenta
el número de poblaciones
que estoy manejando fijará
que por por da una idea,
aunque no es un detalle completo,
pero la comparación de ese centre,
cuanto más variable haya, más
diferencias se pueden incluir,
el término sabía más grande entonces
para tener en cuenta el tamaño
de población en dividimos por
caminos y eso me genera un término
que lo que llamaré el cuadrado medio.
Entre el grupo que mide el efecto
que hay en los datos,
a partir de la diferencia
entre la media,
teniendo en cuenta el tamaño,
el número de policías
y después el término de
ese centro médico,
dividir por Menorca que tiene
en cuenta el número total
de observaciones y el
número de grupo,
y eso me genera humor número
que voy a llamar cuadrado
medio dentro del grupo
que me permite medir
qué variabilidad proviene
de inmaculado.
De hecho, no voy a desarrollar aquí
pero que también están en relación
con la estimación de Sigma.
Entonces mí lo que me importa
es que sean consciente
de que este término ecm
entre mide la diferencia entre
la media del mismo,
lo que hace medir el
efecto que tiene.
La apariencia sobre y ahora voy a
hacer considerar ese cociente
de santo cantidades como herramienta
para decidir entonces.
Ese cociente en lo que
se llama usualmente,
muchas tablas de Anova, les suelen
llamar la razón de variedad
y se le nota por Efe mayúscula
de acuerdo,
siete cociente tomaba el asalto,
aceptar la hipótesis Hsu 1.
Hay mucho efecto de la diferencia
de la media
y considero que es una cierta,
y si fuese consciente, tomaba
valores bajo entonces
consideró que el efecto que
tiene la diferencia
entre las medidas muy pequeños puede
considerar considerarla, iguale
y lo que realmente tiene efectos
en la variabilidad,
nota.
El factor sima.
Cuadra ahora cómo decidimos si este
valor es grande o pequeña?
Pues simplemente, como siempre,
a partir de entonces el valor
no tenemos calcula aquí
y en función de ese estadístico aquí
recordar que yo pongo la fórmula
pero nunca lo voy a pedir,
lo vamos a aceptar
y este valor que depende de Efe
tiene la característica
de que cuando efe grande es pequeño,
y cuando efe, bajo el
valor de Fernández,
al final que lo que hacemos siempre
nosotros decidimos a partir de ahora
en Mallorca recordar que el
balón es grande es alto.
Si el valor del estadístico es valor
estadístico, pequeño entonces sí;
pero no es exacto, porque
estadísticos pequeños
y todo lo que hacemos esta noche,
su cero en caso contrario,
se estaba bajo porque lo grande
te consciente grande.
Esto le gana.
El honor le ganan denominado, y
aceptaría una hipótesis bien.
Una cuestión muy importante que
voy a añadir antes de seguir
con el ejemplo es que toda
esta información
y esta composición de la variabilidad
para decidir las medidas son
iguales, son distintas,
sea resume siempre en lo que se
llama la tabla de la Nova
que vamos a construir a continuación.
Entonces la tabla la nova,
es una tabla con esta estructura
o estatal.
Una ola voy a pedir como parte
de la resolución,
de los problemas que tiene que
acostumbrar a buscar la parte
de esta tabla.
Lo que aparece es en una columna.
Aquí aquí aparecen varias columnas
por identificar la, la variabilidad,
de dónde procede aquí una columna
que se le llama que la libertad,
que no tiene por qué incluirla
me acuerdo,
yo lo pongo porque la mayor parte
de los libros incluida,
pero sobre todo aquello que
interesa a esta columna
aquí donde esté donde está indicada,
como la de composición
de la variabilidad,
total en términos de la diferencia
entre la media y de la apariencia,
en una serie, en una columna,
a continuación se calculan las
modificaciones de Soto.
Término es excedente, se sucede
dentro como cmt,
icm dentro y por caminos,
1, poner en Menorca
y a partir de aquí fijado, que ésta
se obtiene a partir de vivienda
dividiendo por caminos y actas,
sostiene Martínez,
está dividiendo por el enemigo
y a partir de aquí
lo que hacemos construir en
la razón de varias Efe
no puede ser lo que va a ocurrir.
Es que no estoy de acuerdo.
Voy a ver en la tabla para
afrontarlo y después veremos cómo construir.
Lo bien que hace la tabla no
va para vuestro ejemplo,
es estar aquí de acuerdo.
Entonces, lo primero que hacemos es
mirar la descomposición de la marea
y observa que la variabilidad total
del total de 50 observaciones,
de acuerdo,
la suma de su hijo da menos su media,
36 puntos, 5, 7, 8, lo que tenemos
es que de esa variabilidad,
de esa variabilidad hay
casi 14 unidades más,
el 30 por 100 de la variabilidad
que provienen de la diferencia
entre la media y el resto,
proviene de la variabilidad que
hay dentro de la variable,
pues viene de la apariencia.
Entonces, fijará que aquí
hay un porcentaje alto
de la variabilidad que proviene
de las posibles diferencias
entre la media,
lo cual ya no da una indicación
de que seguramente
la media van a ser distintas,
ahora que lo que ocurre,
que como aquí no está incorporada
la información del tamaño
de la muestra y el número
de poblaciones,
tenemos que modificarlo.
Cuando hacemos la modificación
nos damos cuenta,
pero ahora la diferencia que
proviene de la variabilidad,
que proviene de la diferencia
entre la media,
ya es un valor bastante alto
como 53, 45, pero,
y sobre todo cuando lo comparamos
a la variabilidad que proviene
de la diferencia de la variabilidad
que proviene de la, que en este caso
es un punto 51, planteamos
que efectivamente,
aquí la medición del efecto de
la media es muy grande,
comparándola con la medición
del efecto de la variante.
De hecho, cuando calculamos
el concierto.
Sal, un valor bastante alto,
seis puntos 77 de hecho,
con ese, con esa razón el balón
sale prácticamente nulo,
con lo cual para cualquier
nivel de significación
ya no solamente cero o cinco sino
también para hacer el punto cero
al ser dolor tan bajo aceptarían
una hipótesis
alternativa?
Es decir, existen diferencias
entre la media,
en concreto parado de laboratorio?
La media son distintas entre sí
por lo menos para una pareja
de acuerdo.
O bien volveremos ahora.
Sobre esas conclusiones y lo
que quiero hacer ahora
es ir al ejemplo y hacerlo con él.
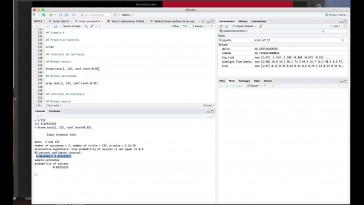
Voy a obtener la tabla.
Entonces la tabla no va
como la obtengo.
Bueno, pues la tabla no la
obtengo con este comando
y fijar para hacerlo.
Necesito.
El lector, tanto todos los datos
y el vector de factores
si no, no pudo hacer
y fijará también que están separadas
por el simbolismo,
que encima de lañ de acuerdo entre
cada uno envuelto teclado
como lo puede obtener, usualmente
con la tecla y la letrañ
se puede obtener pero puede variar
en función del acuerdo como forma su
escrito, este que estoy utilizando
para hacer la nova a la una virtual,
pues también podéis copiar el
comando y quieren simbólicos como bueno.
Entonces fijado que necesito
esa estructura
para componer tanto funcione,
de acuerdo, está funciones,
está este comando
de la composición de la función
a v análisis de la alianza,
Anova con la función.
Sabe que lo que hace darme un
resumen de todo el análisis que aparecen
y en concreto se resumen lo que me
da es la tabla del análisis
de la fijará.
La tabla no está completa, la
entrada no está completa,
fijaron en ndr solamente natal,
la suma de cuadrado
entre y dentro sea fijado en todo.
Dado que aparecen aquí que
corresponden al otro dato
que aparecen en que después siquiera
tengo los cuadrados medio estadístico
de contrato y fijaron
que no hay problema
en recuperar este dato porque
según lo que hemos dicho
anteriormente, este dato es
la suma de esta cantidad
y esta cantidad.
Así que nada de acuerdo y hemos
hecho todo lo que tienen que hacer.
La suma correspondiente.
Recuerdo.
Bueno, entonces con eso,
cerrando ya el la primera
parte de este tema,
hemos visto cómo construir la tabla
de la nueva que se sube más simple
para 1, para un dato,
cómo se interpreta y cómo se
concluye entonces muy importante la tabla.
Hay que incluir siempre en
cualquier análisis,
no solamente para el examen,
sino para cualquier estudio
científico de datos, su tabla,
incluirla.
Hay que hacer una lectura de la
descomposición de acuerdo
y después ver la conclusión
correspondiente.
Ahora aquí nos hemos dejado varias
cosas por el camino de acordar
que lo que hemos hecho
ha sido centrarme en lo que eran
de la danza, de acuerdo,
y que dan una serie de
cosas pendientes.
Entonces, qué cosas quedan
pendientes?
Bueno, tendríamos que verificar
si las variables
y una distribución normal
acordaron que la parte
de las suposiciones iniciales en
eso no hay ningún problema.
Tenemos la técnica de Spirou para
estudiar la normalidad
uno de la variable.
La otra suposición importante
que hemos manejado
es que la apariencia eran igual.
Lo que hemos dicho como Homo decimos
supuesto que la población en seda
o Mocedades tendremos que ver
una técnica para verificar;
es de acuerdo.
Eso no puede verificar lo que
se llama el contraste
de entonces.
Tenemos esa primera parte
en su posición inicial,
pero después el anual se queda cojo
en el siguiente sentido,
y es que con el ejemplo anterior
que hemos dicho,
pues siendo el laboratorio que
tienen medidas distintas por lo menos -2,
pero podemos identificarlo
-la Nueva Numancia.
Entonces nosotros vamos a necesitar
una técnica adicional que no permite
decidir cuáles poblaciones
son las que podemos considerar
que tienen distinta,
y no solamente eso, sino también ver
si podemos decir en el caso
que sean distintas, cuál
es mayor que la otra.
Bueno, pues estas dos cuestiones
son las que vamos a abordar en
las próximas elecciones
y formarán el contenido del segundo
vídeo de Por otro lado documental,
una cosa.
Aquí hemos hecho
o una extensión de un problema que
vimos en el tema anterior,
pasando de dos poblaciones
a la población.
Entonces podríamos pensar
que por qué no directamente
utilizamos esta técnica puesto
que también vale parados.
Bueno, pues de lo que hemos visto y
lo voy a remarcar ahora dará cuenta
que la norma tiene una serie
de limitaciones.
La primera limitación de Anova
es que solamente abordar el caso de
muestras, que son independientes,
entonces necesitaría un
caso muy parejo.
De acuerdo, por otro
lado, esta técnica
solamente permite decidir si son
iguales, son distintas,
pero no permitiría cómo contactar la
lectura muestra independiente,
decidir cuál de ellos es mayor que
la otra, luego de acuerdo,
y, por último, la limitación
de la moción.
El contrato de la destitución
se puede hacer
para la Alianza igual o distinta,
y en la Nova.
Entonces, esa entre limitaciones hace
que no podamos utilizar, que podamos
utilizar esta técnica,
pero en una situación en más
reducidas que la que podemos abordar
con el contraste de la lectura,
en parámetros independiente,
cuando tenga motor, tenemos
todo nuestro arsenal
con el contrato de el
montón de cosas,
pero ahora sí tenemos más
de dos poblaciones.
Por lo que hacemos utiliza
la técnica de Igualdad.
También podríamos pensar que por qué
no vamos cogiendo por pareja
y cómo comparando, pero pasan
dos cosas darnos,
cuenta que tendría que realizar
muchos contrastes de hipótesis.
De acuerdo.
En este caso tendría que hacer.
Por ejemplo, si tengo cinco variables
tendría que comprar la primera
con las cuatro siguientes
tendrían cuatro la segunda
con la siguiente
obtendría entre siguiente la
tercera, con las dos siguientes,
y en total tendría que hacer
unos 10 contratos
y, por otro lado, esa técnica de
hacer comparaciones parciales
no asegura que el error de
tipo uno que yo tengo
en cada uno de los contratos se
pueda mantener en general
para todas las comparaciones.
Es una cuestión bastante técnica,
pero hace que, en el caso de,
tengamos que optar por de toda forma
alguna de las cuestiones
que hemos tenido,
de que tienen que ser Mocedades
óptica de de plantear
si son mayores o menor,
etcétera, etcétera,
veremos cómo técnicas que
son alternativas.
Con un vídeo de hoy y nos vemos si
nos unimos próximamente un saludo
y que vaya todo bien.