Con los nuevos alumnos y alumnas de
la asignatura de Estadística
delegado de Ciencias Ambientales,
siguiendo con el desarrollo del tema
seis en esta segunda entrega,
lo que vamos a ver va a ser la
comparación de dos variables.
En el caso de muestras
independientes.
Me acuerdo.
Antes de empezar, voy a recordar
un idea del vídeo anterior
entonces recordar
que en el vídeo anterior comenté que
la comparación de dos variables,
en el sentido de ver cuándo
una era más grande
que otra, tenía sentido en,
por ejemplo en el caso de las
distribuciones normal,
porque el hecho de que decidamos
una variable
más grande que otra nos lleva
a que las observaciones
que se puedan producir de cada
una de las variables
tienden a estar en zona diferenciada,
y la variable que tiene tomar
valores más grandes.
Se encuentra el intervalo posible
valore en una zona más
hacia la derecha que en el
caso de la variable,
donde hay un desplazamiento
hacia la izquierda.
Estoy documentando también
que, bueno, para decidir si
hay ese desplazamiento
entre las funciones de densidad,
lo que conduce a observaciones
diferenciada en cuanto al intervalo
que toman esos valores
se podía hacer.
En el caso de distribución normales,
de una manera muy sencilla,
porque simplemente lo único
que tenemos que hacer
es comparar esas dos medidas
de la variable
y decidir si son iguales,
son distintas
o una mayor que la otra.
Así que el problema de decidir si
dos variables eran distintas
y si una era mayor que la otra,
la podríamos reducir al
estudio de la media.
En el caso de las distribuciones
normal.
Volviendo a la transparencia
del tema,
también os comenté que hay una
diferencia muy importante
a la hora de llevar a cabo el
análisis, que era distinguir
si las muestras eran independientes
o las muestras eran pareja.
En el caso de muestras
independientes tenemos dos variable
sin ninguna relación variables
independiente
de cada una de las muestras o de
cada una de las variables
obtendremos una muestra
siempre por separado.
De acuerdo.
En el caso de nosotros tenemos dos
variables que eran dependientes
que se miden a la vez sobre
un mismo individuo,
lo que va generando pared de
observaciones, en nuestro caso,
lo que vamos a analizar, la
situación de muestras independiente,
y es lo que vamos a analizar en
esta segunda entrega bien.
La situación, entonces,
que estamos manejando
en esta situación,
en la siguiente tenemos dos
masas independientes,
no imposible.
Las relaciones entre los valores,
observando una muestra de la otra,
no hay ninguna relación
entre una variable
y otra ni entre una muestra, y otra,
la situación de la que partiremos,
será variable,
con distribución normal, con
una media y una variedad
de acciones concretas que suponemos
que son independientes.
Como objetivo final, nosotros
lo que pretenden,
lo que pretendemos es obtener
información sobre la diferencia
de las medidas de esa variable.
De acuerdo,
esa información sobre esa diferencia
la vamos a obtener,
o con algún intervalo de confianza
para esa diferencia
o a través de un contraste
de hipótesis,
para esa diferencia.
El punto de partida desde el
punto de vista práctico
es tomar una muestra para cada
una de las variables.
Como he dicho, ante los tamaños,
de momento no tienen
porque ser iguale
y para el resto de cálculo
que tendremos que ver,
vamos a denotar por equipar
las uno ese uno cuadrado,
la media y la cuasi bonanza muestral
de la muestra la variable que sube,
uno con un suv, iniciado,
los mismos valores.
Pero para la muestra de la
variable e insultos
y los tamaños que pueden ser
distintos lo notaremos en su pueblo
y en eso.
Entonces, lo que planteamos
es analizar
si las diferencias a medias
es igual o menor o mayor
que el 0, dependiendo de su valor,
pues tendremos que la media están
ordenadas en un sentido
u otro, o serán iguales me acuerdo,
si musulmana nosotros es igual,
nacieron las medidas, son iguales,
Simó supone menos, mucho menor que 0,
lo que tendremos que supone el
menor que hemos vuelto.
Hicimos un buen uno menos
Mosul, todos en mayor,
que entre los muchos buenos era mayor
que fruto de allí se
podremos concluir.
Si hay diferencia entre la variable
y las medidas son distintas,
pues serán distintas variables
o serán iguales,
y también podamos decidir cuál de
ellas la tomaba lo más grande
que la otra.
Aquella variable que tengo
una media mayor
que la otra será la que tiene a
tomar, valoran más grande.
Bueno, para hacer todo este estudio
nos vamos a hacer un ejemplo
que tiene puesto en las fotocopias y
en este ejemplo lo que se trata,
de hacer un estudio para saber si
la concentración de mercurio
en el agua suministrada por
dos fuentes distintas.
Una, por el servicio municipal
de agua y otra por.
Una empresa privada tiene unos
valores de concentración
de mercurio similar.
Entonces esta medición es muy
variable en la mayoría,
son la concentración de Mercurio;
por un lado analizaremos
las contracciones
las concentraciones de mercurio
en agua municipales,
esa variable, la de Notre
Dame por su pueblo,
y, por otro lado, analizaremos
las concentraciones
de mercurio en agua de semana
ante el privado
que notaremos por el asunto.
Se cogen muestras de las dos
fuentes de acuerdo,
y los valores que se obtuvieron
son los que aparecen.
Cómo ve los tamaños de muestra,
no tienen por qué coincidir.
Bueno, entonces, por la forma en
que se han tomado los datos,
estas muestras son independientes.
Son mediciones en dos localidades
totalmente
de dos fuentes totalmente distintas.
No hay ninguna relación de las
mediciones que hagamos
en un caso en otro, y se trata
de un caso típico
de muestras independiente.
Lo conjunto de individuos o
elementos son distintos.
Bueno, pues lo vamos a hacer.
Es ir a Brno para empezar
el análisis de datos,
recuperando el ejemplo anterior que,
aunque nosotros, la situación
que vamos a plantear
ni conocemos la densidad de una
variable ni la otra densidad,
lo único claro va a ser trabajar con
la muestra de esa variable.
Evidentemente, cuando yo tengo dos
muestras de dos variables
y hago un estudio
como el que tenemos por
aquí, por ejemplo,
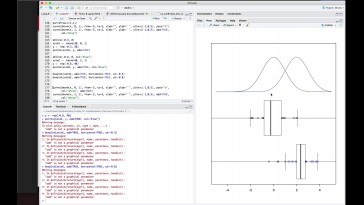
trabajando con los diagramas de
caja de las dos variables,
ya vemos que un desplazamiento
de un conjunto observaciones
hacia la izquierda y otro conjunto
luego son puede ser ya una indicación
de que en realidad las
variables de partida
tienen distintas.
Aun así podría ocurrir que por azar,
puntualmente en algunas situaciones,
nosotros no encontramos que aunque
la variable tienen la misma forma,
es decir, que tuviéramos una
función de densidad común
para las dos variables, por
cuestiones de azar,
una muestra se desplazará
hacia la derecha,
y otra muestra se desplace
hacia la izquierda.
Nosotros lo vamos a ver ahora,
a través de las técnicas
de inferencia; verificar
que esa diferencia
que hay entre los dos conjuntos es
lo suficientemente significativa
para decidir que efectivamente
esas medidas son distintas
y que en algún sentido está ordenada.
Una primera aproximación
es de tipo descriptivo
y de pueblo, que pretendemos, con
un contacto de hipótesis,
confirmar que esa diferencia
entre los dos conjuntos
realmente significativa bien,
pues para eso vamos a salir a dar y
vamos a analizar otro conjunto.
Aquí tenemos las 2,
muestran que almacenado en dos
vectores y podemos ver,
los diagramas de caja bigote
de esas dos muerto.
Como vemos en un principio,
el comportamiento
aquí es un poco más amplio que
no tienen un valor atípico,
que puede que a lo mejor
podría estar.
Aquí; podrían tener un
comportamiento similar de gama de caja
y en un principio de caja
no señalan más bien
que no hay diferencia entre
los conjuntos de datos
y, por tanto, que la variable
de partida
no tendrían por qué diferencia.
Lo que vamos a hacer va a ser
contactar con un contrato
hipótesis que también aparece
intervalo de confianza.
Que, efectivamente, esa don
conjunto de muestras
no tiene ninguna diferencia
que sea significativa.
Bien.
Entonces, volviendo a al texto,
está claro que lo primero que
tenemos que hacer será verificar
que las variables y una
distribución normal,
recordar que todo nuestro punto
de partida es que,
como la variable son normales,
la comparación de varias puede
reducir la comparación
de las medidas, pero necesito
saber que la variable,
si una distribución bueno en este
caso no hay ningún problema,
porque nosotros podemos utilizar
el contraste de esa huelga
que hemos visto en el tema anterior
para verificar esas hipótesis
de normalidad de la.
Entonces.
Volviendo a nuestro ejemplo,
podríamos hacer nuestro
contrato Teresa.
Vieron, como veis, tenemos un valor
lo suficientemente alto como cinco
o como 0, uno para aceptar la
hipótesis y concluiremos
que la primera variable a
partir de esa muestra,
si una institución a la misma
tendríamos que hacer con
la segunda muerta, tendríamos
que hacer un.
En este caso el valor es esta
cantidad de aquí también
es un valor suficientemente grande,
tiene ambos casos,
tendríamos que la variable sigue
una distribución que es
nuestro prime.
Nuestro primer paso que
tendríamos queda,
y como hay normalidad
las dos variables
podemos seguir ya con nuestro trabajo
para poder hacer inferencias
sobre esa diferencia
de media por una cuestión técnica
necesitamos saber primero
si la pareja de las dos poblaciones
son iguales
o son distintas.
Ahora veremos cuál es la
diferencia técnica,
que la variante sean iguales
o sean distintas, pero
este primer paso
no tenemos ahora mismo ninguna
herramienta de acuerdo.
Lo que vamos a ver es que podemos
utilizar para verificar es bueno,
pues la herramienta que podemos
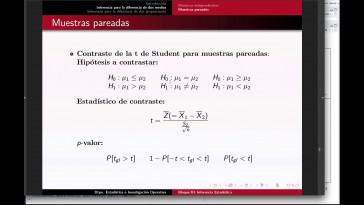
utilizar es el contraste de acceder.
Es uno de los contratos más conocido
y es un contrato que sirve para
verificar como hipótesis nula.
Si la alianza son iguales
o son distintas,
dependiendo de si la venganza son
iguales o son distintas,
los estadísticos que se utilizarán
para hacer inferencias
sobre la diferencia de media varía,
por eso es muy importante verificar,
primero esa igualdad y
decidir qué fórmula,
que utiliza bien el contraste
de la con detalle
es un contraste que permite
contactar esta hipótesis.
Si las desviaciones típicas de
la variable son iguales
o son distintas, se podría
formular igual.
Entre uno de la danza, es decir,
podemos plantear como hipótesis
las hicimos una cuadrado es
igual sin más cuadrado,
frente a que Simon o cuadro sea
distinta de Sigma dos Cuadrado.
Lo cuenta que si la desviaciones
típicas son iguales,
son distintas la crianza, que son
el cuadro de esas cantidades
también van a ser igual
o son distintas.
Luego Podemos plantea
como hipótesis nula
la igualdad de las desviaciones
típicas,
o la igualdad de la pared
estadístico de contraste que se utilice
en este caso es el cociente de las
de acuerdo que se obtiene
a partir de las muestras
que hemos manejado,
y el su cálculo tiene una
fórmula explícita,
pero por ahorrar complicaciones
de desarrollo que en realidad
vosotros no vais a tener
que utilizar,
iremos directamente a su cálculo con.
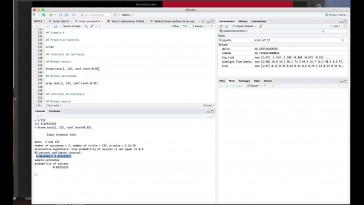
Bueno, pues cómo se lleva a cabo
este contraste de la.
Es muy sencillo.
La función que permite hacer este
contraste de hipótesis
en la función bar.
Punto test, y lo único que tenéis
que hacer es indica
quiénes son las dos muestras de las
variables que estamos considerando.
Una vez que lo tenía escrito de esa
forma, lo ejecutan de acuerdo
y que obtenemos el valor de
contraste que recordarlo tenéis que anotar,
y, por otro lado, tenemos
el valor del contraste,
que en este caso cero puntos.
Por tanto, con ese estadístico
y ese regalo obtener que,
como contraste para nuestro ejemplo
decidir si la alianza va bien,
cines típicas son iguales
o son distintas
que con el siempre valor el valor
mayor que Alfa ya sea igual a cero
un 12 cinco cero punto cero uno
por lo tanto y la Alianza
serían iguales.
Este contraste lo tenéis que incluir
en el desarrollo de la respuesta
y tienen que plantea el contraste de
de Equo con su hipótesis mola,
con su hipótesis alternativa,
incluye estadístico de Contact,
incluir el color y después
la conclusión.
Qué hacemos ahora cuando tenemos
esa conclusión?
Bueno, lo que ocurra ahora
es que nosotros nuestro
siguiente paso base.
Hacer un intervalo de confianza
para Moix.
Hubo un insulto o un contrato
de concesión para ver
si hubo un insulto, son iguales o se
ordenan en algún sentido bien
el.
En cualquier caso, se pueden
realizar estas dos operaciones,
tanto el intervalo como el contraste.
Lo que ocurre, como he
dicho anteriormente,
es que la fórmula varia yo voy a
incluir las fórmulas en cada caso,
aunque vosotros no las tienes
que utilizar de acuerdo,
pero la puede incluir para que
veáis la diferencia efectiva
que hay entre un caso y en otro.
Entonces, en el caso en que
la pareja fueran iguales,
el intervalo de confianza
tiene esta expresión
se fija en el intervalo de
confianza para Mousse.
Hubo uno menos muy fruto, es un
intervalo cuyo punto central,
en la diferencia de la media
mostrarle ya se diferencia
de la muestra, se dueña de
una cantidad que se suma
y se recta para construir.
Aquí aparece un valor que es
bueno que está descrito.
Cómo se construye.
Vosotros no lo tenéis que hacer,
así que nos preocupe y le
pueda parecer un valor,
ese mayor, una que se calcula
con esta expresión
que aparece en el caso del
contraste de hipótesis.
En este caso lo que podemos realizar
en lo que se llama el.
La de parados poblaciones.
Recordar que en el caso de
muestras independientes,
que es el caso que estamos
trabajando entonces,
ese contacto de las poblaciones
con muestras independientes
permite contactar los siguientes 3.
Parece hipótesis que aparecen aquí
que nosotros tendremos que decidir
en función del ejercicio.
Por ejemplo.
En este caso vamos a
hacer el contraste
de si las medidas son iguales
o son distintas,
podrían hacer cualquier acuerdo.
Voy a hacer uno para que
un ejemplo bien
el expolítico de contraste es estoy
aquí estoy de contraste.
La diferencia entre la media
muestran el partido por la cantidad
de ese que hemos visto en
el resultado anterior
de confianza.
Ese valor de ese que aparece aquí
es el que vamos a utilizar
en el que contacte y el valor.
La fórmula correspondiente,
que nosotros calculamos siempre
con lo que pasa.
Si la apariencia son distintas,
pues han dado
al intervalo de confianza para
un musulmán es muy parecido,
aparece como valor central
del intervalo.
Su número se equipara, resultó
la diferencia a la media
mostrarle ya esa diferencia.
Me voy a mostrarle cantidades
donde está multiplicada
por un término a ese prima,
a diferencia al término
de ese que aparecía anteriormente.
Que ahora tiene esta expresión,
que aparecen como podéis comprobar
en la expresión
y está entre sí hay una diferencia
bastante notable
y, por lo tanto, es muy importante
decidir si la prensa son iguales,
son distintas, porque la forma
totalmente y radicalmente distinta
me acuerdo si lo que queremos hacer
un contacto y hipótesis,
entonces podemos hacer el contraste
de la lectura para las poblaciones
de nuevo en el caso máster
independiente,
pero ahora bajo la suposición de que
la apariencia son distintas,
las hipótesis que se puedan contactar
son las mismas que en el caso
anterior, es decir,
el resultado que podamos conseguir.
El contrato de la lectura
para dos poblaciones
de muestras independientes
es el mismo.
Tanto si la apariencia son iguales,
como si la apariencia son distintas,
lo que ocurra ahora estadística
de contraste es distinto.
Aparece la expresión ese
prima de Spring
mal visto anteriormente, y difiere
del caso anterior,
al cual diría,
por ese valor de la expresión que
hemos comentado anteriormente.
Así que nuestro caso excesivamente
contrate
y el cálculo del color también
tiene diferencia
en la que no voy a entrar.
Entonces, lo que sí quiero
que os quede muy claro.
Es que el contrato era para
dos poblaciones.
Como estas independientes, consiguió
al final lo mismo.
Contratar cualquiera,
perdón, contraataque cualquiera
de estos tres pares
de si cualquiera, pero los
estadísticos de contraste
que se utilicen los valores son
conforme a una actitud
totalmente distinta.
Bueno, pues lo que vamos a
hacer va a ser utilizar,
en nuestro caso la información
que hemos conseguido,
de que la pared danza eran iguales
para obtener tanto
un tema de confianza
como en contacto.
Bien.
Voy a empezar con.
En primer lugar, el contraste
de la gestión.
El contacto de la detective en cómo
se consiguió en este caso
se consigue mediante esta función
que aparece aquí
no es una función nueva.
En la función.
Te punto solo que en la
lección anterior
nosotros lo utilizamos para hacer
un contrato sobre la media
de una única variable,
sino recordar los argumentos
que utilizábamos.
En ese caso poníamos un argumento
que oponía igualaron para indicar
que el contrato se está aplicando
solamente para una variable.
Bien, ahora,
como nosotros estamos utilizando el
contrato para dos variables,
ya podemos ponerle dos vectores
de datos de eso,
de esas muestras para esa variable.
Tal y como parece de acuerdo
una cuestión muy importante que aquí
tenemos que poner en primer lugar,
la en la muestra de la
variable comedia,
muy supo.
Uno según hayamos plantado
contrate hipótesis,
y aquí tenemos que poner el vector
de datos correspondientes
a la muestra de la variable
comedia, muy fruto,
tenéis que respetar el orden
con el cual hay,
plantea vuelto contacte de hipótesis,
mira aquí aparecen un tupper del
argumento que pudiera comenzar
y lo que hubiera un foco a focalizar
ahora mismo en la atención,
en el resultado de esta función.
De terminaremos, de comentar
los argumentos,
bien si con si ejecutamos esa
función, tenemos, por un lado
el valor estadístico de contacto que
recordarlo lo tenéis que anotar,
y aquí tenemos el volviendo
a la transparencia,
con ese tipo de contraste, y con ese,
como que valore mayor que Alfaya se
alzó con la puntuación cinco
cero punto cero uno aceptaremos
puede ser nula y por tanto la media
son iguales.
Es decir, la medida de concentración
de Mercurio son iguales punto para
la la fuente del manantial
privado como para el agua del
servicio municipal de acuerdo.
El caso del intervalo de
confianza muy parecido
al que ya habíamos hecho
anteriormente
en la lección anterior, la
función de Punto Temes,
especifica el nivel de confianza.
El director para la muestra
comemos uno
Everton dato para la muestra de
la humanidad le convirtió
en un susto lo ejecutamos.
Yo tendríamos el intervalo de
confianza que estarían ese intervalo
es el que recuperamos para plantear
un intervalo de confianza
para nosotros, la información
del intervalo.
Muchas situaciones,
pues se puede utilizar ya
para decidir un poco
cómo se comporta la diferencia
de media.
Porque fijado que en esta situación
la diferencia de media está en torno
al cero lo que al final
nos han contactado de
la mesa son igual.
También he dicho
que una cosa en vez de plantear
el concepto de estudio
para ver si la diferencia de medias
es igual a cero o mayor que 0,
distinta de 0, directamente
reescrito esas desigualdades en términos
de si la media son iguales,
son distintas o una mayor
que la otra.
Entonces, para evitar tener
que plantea primero
como la diferencia puede concluir,
si la medida son iguales,
son distintas,
directamente podemos plantear si
volvemos a, por ejemplo, al caso
este general, pues directamente aquí
ya tenemos plantada el contact
de la diferencia en términos de
desigualdad o igualdad mediática,
una de las variables recuerdo bien.
Entonces, con con este ejemplo,
habéis visto cómo se hace
el desarrollo.
De acuerdo.
Yo ahora lo que quiero hacer es
una serie de observaciones,
como habéis visto muy sencillo.
Normalidad igualdad de Valencia y
después ya intervalo o contact
para ver qué le pasa a las medidas
de las dos variables,
después haré un resumen
de todo ese trabajo.
Bien, volviendo a lo que
estamos comentando,
alguien quiere hacer una observación.
El la hipótesis nula y la alternativa
son las que definen el contraste
y recordar que ya lo hicimos
con la contrata para
una sola variable.
Teníamos que especificar cuál era
la hipótesis alternativa.
En nuestro ejemplo hemos puesto
que la hipótesis alternativa
es tu Sainz, que ya comenté
en el caso anterior.
En la lección anterior,
que se corresponde a la
hipótesis alternativa
de que la media son distintas,
si nosotros quisiéramos especificar
cualquiera de las otras hipótesis
que aparecen en el contrato de la
textura un bombo uno menor,
como su autor o musgo uno mayor
que resultó en alternativa,
tenemos que pedir alternativa
iguales o internet alternativa igual a 20,
respectivamente.
Les querría decir que supo
una menor que el insulto
y que supongo mayor que nosotros.
Bien, además, he dicho.
Hay que dar más información de que
la apariencia son iguales,
como ha indicado eso.
Bueno, pues aquí he puesto
un último argumento.
La función, que era el argumento,
va al punto igual,
a igual, igual que lo que
hace sin mi cable r,
que la apariencia son iguales.
Si en un ejercicio el contrato
de la FP da como resultado
que la ponencia son distintas,
entonces lo tendríamos que haber
indicado como var punto
y cual igual a Falqué.
Nuestro caso correspondía igual a tú,
y, así como la de Motegi fijarlo
para intervalo de confianza.
También tenemos que indicarle,
claro, me acuerdo,
y entonces, los argumentos del
intervalo de confianza
son simplemente la tope de datos.
El nivel de confianza,
y sin aparecer son iguales
o no el contrato,
al igual que antes de dato.
Cuál es la concesión alternativa
y que le pasa a la pared?
Ha hecho Jesús Nación
sobre la función.
Te punto.
Voy a hacer ahora una serie de
observaciones generales
sobre el contrato de las muestras
independiente.
Bien hemos supuesto a lo largo
del desarrollo anterior,
que la variable son normales
y hemos dicho.
Bueno, hay que verificar
que esta suposición,
no hay ningún problema, ya tenemos
una herramienta que contrate a Spirou
y darnos cuenta que tenemos
que realizar un contraste
por cada muestra.
Es un error bastante común juntarlo
los vectores de datos en uno solo
y hacer un test de Spirou al
anotó, conjuntos de datos
a la vez no tiene que hacer un
para cada una de la muestra,
que es lo que hemos hecho
en el ejemplo,
y no hay ningún problema porque
había que aún así
la variable, no sea una
distribución normal.
Entonces vamos a hacer
lo que hemos hecho
en el tema anterior.
Consideramos como alternativa
la distribución,
lo normal para la variable.
Analizamos si la normalidad, igual
que hicimos en el tema anterior
y si lo molida podemos abdicar
el intervalo,
el contraste de la contractura,
pero a los datos transformado,
por el organismo imperial,
igual que hicimos en el caso
de una sola variable.
Ahora bien, podría ocurrir
que no fueran.
La normal es que no fueran
tampoco los normales
y entonces en un principio no
podemos utilizar las herramientas anteriores
que podemos hacer.
En ese caso.
Bien, bueno, si la tamaño que
muestran son mayores que 30,
podemos aplicar tanto el contrato
como el intervalo
visto anteriormente, no
hay ningún problema,
se pueden aplicar el intervalo
y el contact,
pero necesitamos tamaño.
Te muestra mayores.
Puede ocurrir.
Yo soy bastante común en situaciones
donde los tamaños de muestras
sean menores que 30 fijado,
que es cierto
que hoy en día podemos obtener el
tamaño que muestra muy grande,
pero hay situaciones donde
los tamaños demuestran.
No pueden ser tan grande porque
obtener una observación
es muy costoso, recuerdo muy costoso
por cuestión logística.
Imaginaba que hay que ir una zona
donde es muy complicado llegar
y no se pueden estar tomando
observaciones cada dos por 3.
Entonces, no puedo dedicarme a todas
las asociaciones que quiera,
estoy limitada por una cuestión
de logística,
o también puede ocurrir que sea
muy costoso por dinero
alguno, que no voten tamaño
está tan grande.
Bien, si alguno de los tamaños
de muestran menor
que en 30 no he podido aplicar
el contrato de la lectura,
porque ni las variables son normales
ni las variables son los normales,
podemos aplicar un contacto
que se contrate de huecos
son más Wayne, que nos permite
detectar diferencias
entre la variable a partir
de sus medianas.
De acuerdo, ese contraste lo voy a
ver después de las observaciones,
pero sería nuestra alternativa
en el caso
de que no pudiéramos hacer nada y
uno última observación importante
dentro del contexto de estudios
medioambientales,
y es que una aplicación muy concreta
que contacte la determinación de sí
un área que está contaminada,
ha quedado limpia
o ha sido un área que se
cree que está limpia,
puede haber quedado contaminada.
Esta determinación de
estas situaciones
se reducen muchas veces a la
comparación de variable
de sustancias que, digamos,
son contaminantes,
y lo que queremos analizar si
la media de esa sustancia
está por encima de uno valore lo
cual indicaría contaminación
o están por debajo de unos valores,
lo cual indicaría que la zona
no está contaminada.
Usualmente.
Lo que se suele hacer es comparar
esa zona con zonas
que se sabe que es tan
limpia de acuerdo
si el comportamiento de las dos
variables en la misma,
la zona considerada limpie,
pero sí la medición de esas
sustancias contaminantes,
son mayores que la medición
de una zona que se sabe
que están limpiando concluir
que está contaminado.
Entonces, la cuestión ahora es.
Cómo hay que formular una
hipótesis alternativa
en cada uno de los casos?
Bien, entonces hay una diferencia.
Si la zona no ha sido declarada
contaminada,
y lo lo único que ocurre
es que hay sospechas
de que pueda estar contaminada.
Entonces, la hipótesis nula debe ser
que el área no está contaminada.
Eso, en términos prácticos,
cómo se realizaría?
Pues cogería una sustancia
contaminante,
específica de interés en este caso
y se trataría de ver como
hipótesis nula.
Si la esas mediciones del área
que está que supuestamente puede
estar contaminada son menores iguales
que la de una zona que se
sabe que está limpia.
Si nos quedamos por debajo
de los valores
de una zona que no está contaminada,
de acuerdo,
podemos asumir que esa sustancia
contaminante
no está por encima de un valor
que podemos considerar
suficientemente alto para
que esté contaminada;
iríamos contaminación que,
como en los contratos de importes.
Si la probabilidad es de tipo 1,
lo único que controlan una
conclusión significativa
no diría que el área
está contaminada,
es decir, si el valor es muy pequeño,
la probabilidad de equivocarte
en este caso es decir
que la zona está contaminada,
pequeñísimo y entonces la conclusión
de que está contaminada
es significativa.
Por contra, la zona
ha sido declarada como contaminada
lo que nosotros querríamos ver,
es si el área ha dejado
de estar contaminada.
De acuerdo.
En esta situación se producen
a través de limpieza
y lo que se quiere ver es si el área
que deja de estar contaminada.
Entonces, en este caso,
la hipótesis nula
debe ser que el área
está contaminada,
es decir, que los valores de
esa sustancia contaminante
están por encima de los valores
de zona que se saben
que están limpias, en este caso.
De la misma forma, una conclusión
significativa
sería que el área ya no
está contaminada.
La probabilidad de equivocarnos
aquí sería muy pequeña,
la probabilidad de equivocarnos
al decir
que el área no está contaminada.
Imaginar los riesgos que podrían
haber sido una zona que se contamina
después de tareas de limpieza yo
determinó que no es tan limpia
cuando en realidad está contaminada.
Entonces podríamos tener
consecuencias muy graves
para tener el más pequeño posible.
La cuestión es plantear
como hipótesis nula
que el área, si está contaminada
y, en ese caso una conclusión
significativa
sería que el área ya
está contaminada.
Hay ejercicios de problemas
resueltos de esta situación.
Posiblemente ahora mismo
no queda muy claro.
Yo lo que quiero es que lo pensé.
El ejercicio de cómo haremos o
subirán los problemas resuelto
y además haremos videoconferencia
pues cualquier cosa
que quede sin aclarar la terminamos.
Pero primero quiero que
vosotros lo penséis.
Bueno, entonces,
volviendo al problema de la
comparación de medidas,
cuando no hay normalidad, cuando
no hay normalidad
y cuando el tamaño de muestras
son pequeños,
por hemos comentado anteriormente
que lo que podamos llevar a cabo
es el contraste de Wilco, que
te contacte muy de hueco,
lo que permite comparar
los valores e Mesut
y Mesut donde Messi y
son las medianas,
de las poblaciones que
quiso uno que quiso,
dos respectivamente, aquí
quiero hacer un inciso.
Hasta el momento el concepto
de mediana
vosotros lo habéis visto en
estadística descriptiva
es el valor que deja al 50
por 100 a su izquierda
y su derecha es una medida también
de tendencia central.
Igual que aquí cuando hablamos de
la mediana de las poblaciones
nos referimos al valor
de uno ya me soto las dos situaciones
que deja al 50 por 100 de los
valores poblacionales,
no de los valores centrales, sino
de los palabras poblacionales
al 50 por 100, la izquierda,
la derecha,
sería el valor que parte por
la mitad, la variable,
en el caso de la distribución normal.
El ejemplo anterior.
En momento voy a situarse
para que lo veáis.
Claro.
Los casos de variable con
distribución normal
fijaron que el valor que parte
por la mitad la variable,
se corresponden con la media.
Entonces el caso, la distribución
normal,
un caso de la mediana y
la media coincide,
pero no tienen por qué ser siempre
así; en cualquier caso,
se van a utilizar como medidas
de tendencia central
de la variable.
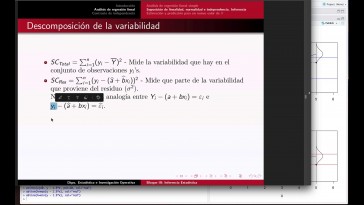
No hablo, no hablo, solo, muestran
sino a nivel de la pared
su definición formal bastante
técnica no voy a insistir en ella
porque tampoco va a aportar nada,
pero simplemente se trata de pensar
en la mediana de la variable.
De manera análoga,
como pensáis con la mediana de
una muestra es el valor,
que deja 50 por 100 a la izquierda
y a la derecha.
De acuerdo?
En nuestro caso lo vamos a hacer ya
que no podemos comparar la media
porque la mayoría no son normales y
no podemos compramos un insulto
porque no son normales.
Lo que vamos a plantear es
comparar las medianas
como alternativa a la comparación
de la media.
Por qué?
Porque es una medida también
de tendencia central.
Evidentemente,
si la mediana están desplazadas
hacia valores más altos
y eso obliga a la variable
de desplazarse a valores
también más alto, entonces el
esquema de pensamiento,
que quiero que quede claro que
la comparación de variable
se puede hacer en términos de media
como medida de tendencia central,
y eso tiene su sentido en el caso
la distribución normal,
como hemos visto,
y si no se produce esa situación
de normalidad.
La alternativa es comparar
cuota media,
tendencia central que en la media,
y además vamos a recurrir a esto
cuando el tamaño de muestra
sea pequeño de vuelo,
bueno, te contraste, pienso, su
estadístico tiene la fórmula,
son muy complicada, yo no podía
desarrollarla y vamos
a ver un ejemplo de ese
contraste de hueco,
John Wayne, para comparación de
media, para este contacte Boya,
también plantea una situación
práctica que os puede ocurrir, que es
que en alguna situación,
en vez de tener los vectores
de datos, separan,
los vectores de datos no tenéis
dentro de un marco de datos.
Entonces vamos a abordar una
situación que ya ha visto,
porque se corresponde con una
situación que aparecía
en la tabla.
Dos de la estadística descriptiva
en el cual se tiene
una serie de mediciones
voy a ir a la tabla,
vamos a comentar sobre esa tabla los
datos que tenía de acuerdo.
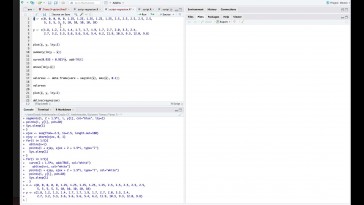
Entonces, primero voy a recuperar
la tabla con este comando,
recordar que para recuperar la tabla
en la sesión de trabajo de estudio
tenéis que indicar dónde
tenéis el fichero.
Entonces es consciente
de que si no identifica bien
el director de orquesta,
el fichero guardado este comando
va a dar un error de lectura
en este caso yo lo tengo
identificado correctamente y entonces he incluido
esa tabla de datos en un marco de la
que lo voy a llamar bellotas.
Si voy al si voy aquí a r
y le digo que me enseñe cuál
es ese marco de datos,
este marco correspondía a una serie
de mediciones de robles
de Estados Unidos.
Había distintas especie, se
distinguían por dos regiones,
estaba en la región atlántica
y la región de California
y aquí lo que hacíamos era
medir varios variables
en las que se encontraban el área
de el área donde se encontraban
el tamaño del área donde se
encontraban esos roble.
El tamaño en cuanto al diámetro del
tronco y la altura de esos facturas,
y no recuerdo mal estaban imaginaba
una situación donde yo quiero comprar
la altura de los robles
de la zona atlántica
con la altura de los robles
de la zona de California,
para detectar si hay
diferencias o no,
pues evidentemente no tenemos
los datos separados,
en dos vectores de datos,
pero lo primero que voy a hacer
es explicar cómo puedo coger
y separar esta columna en
un vector de datos
para poder hacer la comparación
entonces,
volviendo a r la forma de realizar
esa esa división
en dos vectores de datos, de esa
columna en la que aparece,
que había generado dos vectores
de datos, de Kisumu y éxitos
donde lo que hacemos es almacenar,
los datos de la altura
de la zona atlántica
y los datos de la altura de
la zona de California.
Entonces, como hemos hecho eso,
entonces recordar que los elementos
de dentro de un vector de datos
se pueden indicar entre
corchetes indicando,
primero la fina e indicando luego
la columna de acuerdo.
Bueno, la columna en la cual
se encuentran los datos
en la columna cinco recuerdo
teníamos cinco columna en la columna cinco
no tengo contrato hasta entonces
aquí lo que estoy haciendo
es decir, mi cable cuál es la
columna que quiero coger
y ahora con esta opción de aquí
lo que estoy haciendo
es indicarle que los datos que
quiero coger del marco de La dos
son los que tienen la segunda
columna igual a Atlantic Atlantic,
era la forma en que se identificaba
que el dato provenía
de la zona atlántica y la forma
en que se especificaba
que el dato viene a la
zona del iPhone,
en California.
Entonces tenemos que estar pendientes
de cómo se identificaba la región
en el marco de datos.
Aquí sería Atlántico y en esta zona
a otra zona como California,
y eso es lo que tenemos que
empezar a redactar,
que aquí lo que hago es decirle
que el marco de datos
coja la segunda columna,
pero solamente los valores
que son igual,
da igual lo importante que mantenga
el interés sino no va a dar problemas
para acoger los datos de
la zona en California.
Hacemos lo mismo.
Quiero los datos de la columna, 5,
en los cuales la segunda columna
es igual a California.
Hay muchas otra forma de especificar
o de extraer un subconjunto de datos
de un mal dato en el fichero
PDF donde está desarrollando esto,
o ese puerto un enlace
o un vídeo de unos cuatro
o cinco minutos,
donde especifica otra forma,
por si resulta más cómoda.
Esta es la forma donde queda más
explícito y más evidente
que lo que quiero hacer.
Quiero coger la columna cinco cinco
solamente los datos que tienen
la segunda columna.
Igual adelante, los que tienen
la segunda columna igual
a California.
Entonces, una vez que construimos un
marco de datos podemos nosotros
ya pasaba igual que en
el caso anterior.
Voy a construirlo de caja.
De la muestra, de acuerdo, como ves,
aquí hay dos conjuntos de muestra.
Los datos parecen
aquí están mucho más dispersos
en esta situación de acuerdo
y, bueno, pues se trata de ver que
lo que ocurre aquí volviendo
al trabajo que estábamos
haciendo de Primera.
El primer planteamiento sí quiero
comparar esas dos variables
sería analizar la normalidad
de una muestra.
Como veis, el pequeño, un nivel
de cielo, punto 0, 5;
rechaza la hipótesis de normalidad,
y para la segunda muestra,
pues sí que aceptaríamos la
hipótesis de normalidad, pero no la no;
son las dos variables normales
una silla una y otra no?
Luego no.
Lo que nos tendríamos que plantear
es si la maniobra es una
institución local
indicó normal.
Lo hacemos como hemos hecho en
el caso del tema anterior
en los dos situaciones, pero muy
pequeñas y concluirían,
que las dos variables
tienen distribución
a que no pueden considerarse
normales ni lo normal.
De hecho, en este análisis que hemos
realizado, la segunda muestra,
donde decía que sí que seguía
una distribución normal,
pero la siguiente.
La primera no.
Luego si ya sabemos que la variable
no es normal no tendríamos
ni que seguir,
porque porque si estás
normal ya sabemos
que la tono pueden ser normales,
pero ya sabemos también que el
actor no puede ser un hogar.
Indicó normales, porque aunque
está fuera del hogar normal
que estoy aquí sí que sería
malo de vuelo.
Entonces, en cualquier caso,
se benefició de la normalidad y
la normalidad era variable,
y si salen negativo en dos casos.
Entonces,
cuando tendríamos que plantearnos
qué pasa con el con la comparación,
desató entonces lo que hemos
planteado anteriormente
era bueno, si la variable no sigue
una distribución normal,
no vamos a ver qué ocurre con
el tamaño que muestran aquí
los tamaños de muestra
son menores de 30.
Lo podemos ver rápidamente.
Si realizamos el tamaño de
muestra de su bono,
este caso 28.
Y el tamaño y la otra variable.
Eso luego no hay, de momento,
no son cada vez mayores
y no podíamos aplicar
el control lateral,
que solamente hace falta que una
muestra sea menor que en 30
para no poder aplicarlo anterior.
Entonces, volviendo a nuestro caso,
lo que hemos dicho ni normalidad
no hay normalidad.
Los muertos son menos que 30.
Entonces, tenemos que optar por
el contrato de uil Toxo,
buena para detectar diferencia
entre la variable.
En este caso a partir de su media.
No puedo detectar diferencia a
través de la media de acuerdo,
no tengo herramienta estadística que
me permite detectar diferencia
a través de la media y luego voy
a utilizar contra tema.
Son muy buena para detectar
diferencias
a través de la mediana poblacional.
Bien, entonces, cómo se lleva
a cabo el contact de hueco?
Son muy bueno.
Tenemos que plantear primero
que contacte,
queremos realizar, imaginar
que yo quisiera plantear
como contraste que la mediana
de la zona atlántica
es menor que la mediana de
la zona de California,
como puede ser nula, y la
alternativa que la media de la zona atlántica
es mayor que la mediana de
la zona de California.
Recordar que lo que estamos
intentando comparar
son la mediana poblacionales,
no la mediana, mostrar.
De hecho.
Si vamos al gran caja bigote,
podemos ver el comportamiento
de las medianas,
recordar que Ryan centrales de caja
se corresponden con las medianas
muestra.
Allí como vemos, no hay mucha
diferencia de acuerdo,
entonces podría ocurrir
que no fuera que fuera de
Wall-E y, entonces baba
a realizar el contrato como Whitney
para el ejemplo que estamos
viendo en este sentido,
pues la función que me permite
generar ese contraste es estar aquí
punto tres lo único que
tengo que hacer,
indicar quién es la muestra de
la variable con mediana 1,
la muestra de la variable
comedia era un insulto
y después, como siempre, indicar
cuál es la hipótesis
alternativa alternativa, que
es uno mayor que me Sotos,
entonces tendremos que en r.
Pues está claro que este
procedimiento específica,
la hipótesis alternativas,
con un contrato tipo,
no es nada bueno,
pues realizamos contacto y hipótesis,
en este caso, y estadístico,
se vuelve al cubo doble
que aparece aquí que lo tenéis que
anotar en puesto contacte,
y este sería el programa.
Una cuestión que os va a pasar.
Muchas veces y siempre da problema.
Muchas veces aparecen
mensajes de aviso.
Por ejemplo, aquí aparece un
mensaje, por Warner Messi,
mucho pensar,
y esto está estropeado.
Ha habido un error candombe,
no se puede hacer nada,
es simplemente un mensaje de aviso
a los mensajes de aviso,
en general no prestarle atención.
Otra cosa es que apareciera
un mensaje de error,
me acuerdo.
Cuando hay una rueda sí que
hay que entenderlo,
porque no, no produce
ningún resultado,
pero cuando aparece un mensaje
de aviso en general
olvidaron de por qué no, no, no,
interviene en el desarrollo
de la obtención de resultados.
Entonces, volviendo al ejemplo,
este sería nuestro estadístico o
tenéis que anotar éste sería puesto
en valor también en notarlo y
igual que en otros casos.
En este caso el valor es mayor que
el nivel de significación
tanto sincero como 5, cero como euro,
y aceptaremos la hipótesis de que me
uno en menor o igual que en esos,
es decir,
la mediana de la zona delantera
es menor o igual
que la mediana de la zona
en California.
Es cierto que esto no
lleva diferencial
del todo las poblaciones.
Por qué?
Porque cabría la, por la posibilidad
de que fueran iguales.
Entonces, en estas situaciones,
lo que haríamos sería distinguir
si son iguales
o son distintas.
Una vez que sabemos que
es una menor, igual
que resultó podemos distinguir; si
son iguales, son distintas,
si son iguales y si son distintas,
porque me subo el menor estrictamente
que nosotros entonces que tenemos
que hacer lo mismo que antes,
pero plantea como hipótesis
alternativa que son
distintas alternativa,
igual cuando llevamos a
cabo el contraste,
en este caso el valor cero punto
906 es un valor muy alto,
aceptaremos la hipótesis nula,
y la conclusión sería que
la mediana son iguales.
Luego la conclusión final
que tendríamos que la mediana de
altura en las dos poblaciones,
no en la vuelta
sino en las dos poblaciones se
pueden considerar iguale,
no hay diferencia a efectos de
mediana en las dos variables,
y podríamos considerar en
términos de esa mañana
que la altura se comporta
de manera similar.
En un caso y en otro.
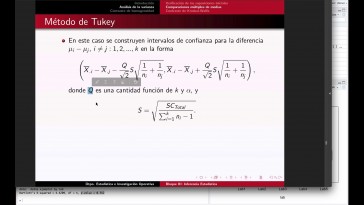
El contraste de Cookson
se lleva a cabo a partir
de las medianas,
igual que la comparación de
medias poblacionales
se realiza en términos de la media
muestra este tipo de contraste.
Aquí también se utiliza la mediana,
mostrar entonces aquí hay una
diferencia entre las medianas.
Muestran que no es lo
suficientemente significativa
como para concurrir que son
distintas y por eso al final
la realización del contraste nos
lleva a ver que son iguales.
Bueno, visto el ejemplo de este
tipo de situaciones,
también donde tienen que
de un marco de datos
todo su conjunto o propuesto
un problema,
si lo podido resolver y si
no resolvemos en duda.
Ahora bien, volviendo al
tema 7, a perdonar,
temas ido volviendo a todo lo
que hemos desarrollado,
hemos visto una serie de pasos
que hay que seguir
y un esquema de trabajo.
Entonces, yo voy a facilitar
un esquema de trabajo
para que vosotros lo podéis seguir
y podéis aplicarlo en
vuestros ejercicio.
Este trabajo es el esquema de trabajo
para la comparación de media de
dos variables independiente.
Entonces aquí lo que he hecho es
un resumen de todos esos pasos
que hemos seguido.
Entonces, el primer paso,
una vez que tenemos las muestras
de las dos variables,
es plantearnos si la variable
es una distribución,
norma, cómo lo realizamos, con
el contraste de Spirou
y si la variable sido una
distribución normal.
Entonces, el siguiente paso
que nos planteamos,
si la ponencia son iguales,
son distintas,
con el contraste de la.
F
922
00:51:37,000 --> 00:51:37,980
-de acuerdo.
Ya lo sabemos.
Si la apariencia son iguales,
son distintas.
Pueden complicar la lectura en
un intervalo de confianza
para ver cómo se comportan
esa 2, uno un susto.
Entonces, siguiendo lo
que hemos dicho,
si falla la normalidad lo que nos
planteamos continuaciones
y las variables y una distribución,
lo normal es que su uno dos
sigue a una distribución.
Lo normal,
si la respuesta es que si realizamos
los dos vasos,
el aquí pero aplicando eso, pasó
a lo tanto tal formado
mediante el organismo
de manera similar
a como hicimos el caso del contrato,
cuando solamente tenemos
una variable.
Y ahora qué ocurre?
Si la variable no sigue una
distribución normal
o lo normal?
Bueno, hemos dicho anteriormente
que tenemos que verificar
si el tamaño de muestra es mayor o
menor tamaño en mayor o menor 30,
ningún problema.
Lo podemos aplicar esto aquí;
pero si los tamaños de muertos
un pequeño entonces
lo que haríamos sería aplicar
el contraste de boicot,
de acuerdo para ver si la mediana
se ordenan en algún sentido.
Entonces, con este resumen ya
podemos abordar vuestro ejemplo,
con la salvedad de cuenta
que contrate hueco,
son muy buena y lo tenéis
que aplicar.
Si no se da la normalidad,
la normalidad y bueno,
si tuviera esta mañana,
te muestras pequeña,
el pueblo.
Bueno, pues con esto voy a cerrar el
segundo vídeo lo dejamos aquí
y seguimos en contacto.
Una obra que vaya todo bien.