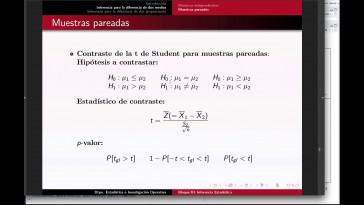
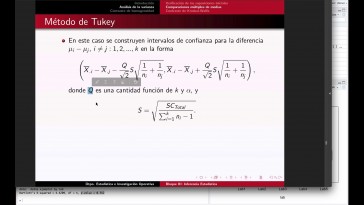
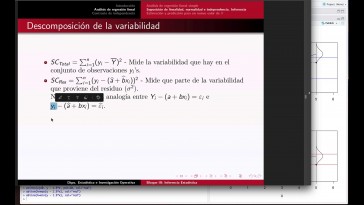
A todos y todas las alumnas y
alumnos de la asignatura de Estadística
del grado de Ciencias Ambientales.
Continuamos con la serie de
vídeos de la asignatura.
Yo le toca el primer vídeo del tema.
Seis titulado inferencia
para dos poblaciones.
En concreto, vamos a tener un
total de cuatro vídeos.
Esos cuatro vídeos se corresponden
a lo siguiente.
Objetivos y contenidos del tema.
En primer lugar,
vamos a plantear una introducción a
la comparación de dos variables
o sucesos que corresponde a lo
que aparecen en la sección
uno del tema de técnicas: influencia
para las comparaciones de media
de dos variables que se dividirán en
el caso de muestras independiente
y el caso muestras pareados que
aparecen en la sección
2, uno su sección de 2, por último,
veremos técnica de inferencia
para la comparación de
probabilidades o proporcione que se corresponde
con la Sección Tercera en
este primer vídeo,
pero muy la introducción
a la comparación
de otras variables o suceso,
y después también quiero hacer ver
la diferencia entre un experimento
con muertes independientes y
un experimento con muestra
variada, pero no veremos su análisis.
Simplemente, cuál es la diferencia
en la toma de datos.
En esas situaciones, a partir
de ahí yo quiero plantear
que en los ejercicios
propuestos decida
qué ejercicios corresponden al
caso muestras independiente
y que ejercicio corresponde
al caso de muestras,
pareja y, posteriormente, una vez
que hayamos desarrollado
los contenidos del análisis
de muestras independiente
y siete muestras para poder proceder
a hacer el análisis correspondiente,
y ya en un último vídeo, pues
veremos las técnicas
de influencia para la comparación de
dos probabilidades o proporciona,
no tanto lo contrario que
hubieran desarrollado
en este vídeo, se corresponden
a la introducción del tema
y después a la distinción
de experimento
con muestras independiente y
con muestra para después.
La diferencia fundamental
que hay entre esas dos situaciones
para después, ya digo,
vayáis a la hoja de problemas
propuesto ya hay una identificación
de qué situaciones que corresponden
a un independiente
y que el caso se corresponden,
a muestra bien.
Pues entonces vamos a empezar ya con
la introducción de este tema.
Vamos a ver una de las principales
aplicaciones
de la inferencia estadística.
Es verdad que el tema entre vimos
unas primeras aplicaciones,
donde podíamos hacer un análisis
de inferencia estadística
sobre una variable o sólo
una probabilidad,
pero en realidad una de las
principales aplicaciones
de la inferencia estadística es
la de comparar dos variable
o también suceso o más nuestro.
No tenemos que reducir nuestra
variable a la hora
de detectar si hay diferencias
entre esa variable
o la probabilidad de esos sucesos,
con el objeto de decidir cuál de
esas variables o sucesos mayor
desde un punto de vista
aprobado de acuerdo.
En este tema lo que vamos a hacer
es abordar el caso más sencillo
de comparar, solamente variable
o dos sucesos
desde el punto de vista
de su probabilidad,
aunque posteriormente en
el tema siguiente
veremos cómo entender eso
al caso general,
la idea es, ya digo, detectar,
diferencia y decidir en el caso
en que diferencia cual ella
tomaba valores más altos.
En el caso de la probabilidad
de dos sucesos,
la idea es sencilla.
Si yo tengo dos sucesos y puedo
comparar sus probabilidades
y ver que una probabilidad más
alta que otra cosa al final
lo que voy a tener que la producción
suceso va a ser más grande
que la probabilidad de
que otro suceso,
un ejemplo muy claro que estamos
viendo, por ejemplo,
en la noticia recientemente con
todo el tema del cómic,
es que sabemos que la probabilidad
de fallecimientos por coronavirus
es más alta en grupos de edades alto,
un grupo de edad más bajos.
Esto es un ejemplo directo y
sencillo de la comparación de probabilidades.
Entonces la comparación
de probabilidad total
está totalmente justificada
y enseguida se entiende.
Lo que no puede estar tan claro es
que quiere decir que dos variables
una vaya a ser mayor que la otra.
Bueno, pues voy a utilizar
para ilustrar un ejemplo
que quiere decir esto
de que una iglesia
Merkel entonces puede utilizar,
como siempre el ejemplo que tomamos
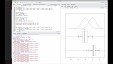
de la distribución.
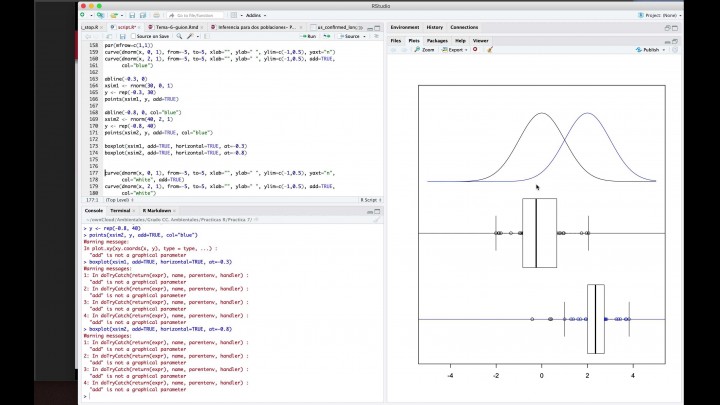
No vamos a considerar que tenemos
dos variables con distribución norma
cuya tensiones son en tanto
que aparecen de acuerdo.
Tenemos una densidad en esta zona,
la recta y otra densidad en esta zona
de la recta es bueno.
Vamos a obtener una muestra de cada
una de ellas de acuerdo,
como hemos hecho en ejemplos
anteriores.
Vamos a ver las dos muestras
que aparecen
cuando yo observo valores del
aval de las dos variable.
Es cierto que yo no puedo decir
que una de las variables
vaya a ser siempre mayor que la otra.
Por ejemplo, aquí tengo
observaciones que son mayores
que las observaciones de
la otra variable.
Luego no puedo decir siempre que
todas las observaciones
de una marea sean menores
que la otra,
pero lo que sí que observamos es
que mientras que en este caso
las observaciones están dentro
de un intervalo que sería
estoy aquí en el segundo caso el
intervalo está desplazado
hacia la derecha, es decir,
es un intervalo que probable
toma valores más grandes.
Bueno, pues la idea de comprar
dos variables,
decidir si los valores que
van a tomar una variable
van a ser en conjunto mayores
que otro conjunto.
Variable.
De acuerdo.
Claro, aquí la diferencia de dónde
surge la diferencia surge
del desplazamiento que esta curva
respecto de aquí la curva azul
está desplazando hacia la derecha
en relación a la curva negra,
de acuerdo.
Y cuál es la diferencia
con la diferencia
es simplemente este punto
aquí que hace
que la curva se desplacen hacia
una zona o hacia otra,
es decir, la media de la pared.
De acuerdo.
Eso produce un conjunto
de observaciones
en torno a la media que van
a estar por esta zona.
En este caso,
la observación en torno a la media
van a estar por esta zona,
y si queremos ver de una
manera más gráfica
el comportamiento, su conjunto,
podemos realizar los diagramas de
caja de esos dos conjuntos
y, efectivamente, vemos que
los diagramas de caja
en el caso primero, están desplazado
hacia la izquierda;
en el caso segundo están desplazados.
Bueno, entonces la idea de decidir
si una variable, más grande,
que otra es simplemente que si
las funciones de densidad
están desplazadas, una
respecto de la otra,
las observaciones nunca se van
a tender a ser mayores,
que en el segundo caso, y en el
caso de la distribución,
norma como vemos entonces se realiza
simplemente a partir de la media
de la variable.
Simplemente con que las medidas
estén desplazada ya se desplaza
toda la curva.
La observación es desplaza
hacia la derecha
o hacia la izquierda.
Por tanto, y volviendo
a nuestro tema,
el la situación en la que nosotros
vamos a aplicar
las técnicas que vamos a ver en este
capítulo son dopar viable,
que pueden ser dos variables,
una misma variable;
medida en dos poblaciones distintas,
o el intervalo de tiempo distinto.
Por ejemplo, podemos analizar
el comportamiento
de la medición de ciertas partículas
en la atmósfera de marzo
con la misma variable, pero en marzo
del año pasado, por ejemplo,
ahora, con la situación
que se está produciendo, hay
una menor contaminación
y la atmósfera está menos
contaminada.
Entonces son dos períodos distintos
y podamos comparar
en dos períodos de integración en
dos períodos de tiempo distinto
cómo se comporta la misma variable.
Otra opción es comparar esa variable
en dos poblaciones distintas.
Podemos comparar variables que
miden la calidad del aire.
Por ejemplo, en España con va
con la misma variable;
en Dinamarca, por ejemplo,
intentar ver
si se puede hacer una comparativa
de sí una mayor que otra,
y decidí que la calidad
del aire en un sitio,
pero otra, porque el valor
de la variable
tiende a tomar valores mayores
en un sitio que en otro,
y la otra situación es comparar
probabilidades o proporción
de un suceso en dos poblaciones
distintas
con intervalos de tiempo distinto.
Igual que en el caso anterior.
Entonces, en cualquiera de
las dos situaciones
la idea es buscar diferencias y
buscar cuál de esa variable
o suceso son mayores o menores.
Desde un punto de vista en general,
esta técnica se utiliza para
comparar dos variables.
Cualesquiera o suceder cualesquiera
lo que ocurre en muchas situaciones.
Esto no tiene sentido, es decir,
yo puedo comparar la variable altura
de la población española
con la variable, por ejemplo,
mediciones de la zona en Dinamarca,
pero no tiene ningún sentido de
hacer esa comparación de acuerdo.
Luego la la aplicación
de estas técnicas
tienen principalmente sentido
en estas dos situaciones
que perdón en estas dos situaciones.
Bien, el ejemplo que hemos utilizado,
de la población Normale
me va a servir
para introducir el la influencia,
para comparar dos variables que,
como veis, en el tema está descrito
como la inferencia.
Para la diferencia de dos me
voy a volver al ejemplo
y volver a la situación que aparece
en esta situación.
Tenemos distribución normal,
era la diferencia.
En las distribuciones genera
patrones de comportamiento más bajo
para una variable que para
nosotros, de acuerdo,
y entonces lo que hemos dicho
anteriormente es que esa diferencia
simplemente se debe a que las
medidas son distintas.
Al final, en realidad,
o lo único que estamos viendo,
cómo es esta diferencia?
Si la diferencia cero ante esa media?
Entonces la variable son las
medidas son iguales;
si la diferencia transmedia
expositiva,
una mayor que la otra diferencia
negativa?
Pues entonces una menor que entonces,
inicialmente todo el proceso de
comparar la tomaría en este caso
para normales, se puede reducir, a
ver qué le pasa esa diferencia,
si esa diferencia es nula,
positiva o negativa,
y con eso podremos concluir.
Si las observaciones de una hora
agotaban está desplazando hacia
hacia la izquierda
o hacia la derecha.
De acuerdo, la cuestión ahora
es que nosotros no vamos a disponer
de información de esa curva.
Nosotros nos vamos a encontrar
con estas dos muestras
de las dos variables,
y a partir de ahí queremos decir
que lo que pasa bien.
Entonces, volviendo al que estamos
viendo en el tema
y utilizando,
como ha dicho como referencia,
la distribución normal,
la forma más sencilla de
comparar dos variables
es simplemente comparar
su medio de acuerdo,
puesto que en ese caso los
observados se van a encontrar
en torno a la media, y
si son distintas,
los cabreros observados, tendrán
tenderán a encontrarse
distintos y, por tanto, las
variables tendrán un comportamiento bien,
pues entonces vamos a hacer
el inicio de este tema
comparando media de dos variables
como una forma de decidir.
Si una variable toma
valore más grande
que otro árabe que lo que ocurre.
La comparación de esa media,
por supuesto,
se va a llevar a cabo a partir
de muestras de la tumba,
pero ocurre que esa muerte se cuanto
más de dos maneras exacto
como esta pueden ser independiente
y pueden ser áreas.
El análisis en cada caso es distinto.
Un primer paso que va a tener
que llevar a cabo
si no, no vaya a poder realizar
el problema.
Distinguir la forma en que se han
tomado las observaciones,
es decir, si se trata de
muestras independiente
o demuestra pared.
Vamos a ver la distinción entre
esas dos situaciones.
De manera informa que el caso
de muerte de independiente,
la observación de las muestras,
se toman sobre el conjunto
de individuos o elementos que
son distintos, es decir,
el conjunto de individuos
sobre lo que yo mido
una primera variable Kisumu y
el conjunto de individuos
o en los que yo mido una segunda
variable llamémosle
e insultos son dos conjuntos que no
tiene nada que ver con el otro.
Por ejemplo, imaginar que
yo quiero comparar
es verdad que es una
situación extrema,
pero va a servir muy bien para
que entendáis la diferencia
entre un casi imaginar
que queremos comparar como variable
la talla del pie izquierdo,
con la talla del pie derecho.
Bueno, pues una situación como
independiente en este caso
sería que cogieran dos conjuntos
de personas por separado,
y en un conjunto medimos primera
hora del pie izquierdo,
y nosotros medimos la talla.
Del pd hecho este ejemplo,
queda claro que siendo
un conjunto distinto
no hay ninguna relación
entre el toma.
Ahora bien, habría una
forma alternativa
de tomar los datos, que es
el caso de muestras.
En el caso de nuestras variada,
los valores, de la muestra
de las dos variables
se toman sobre un único conjunto
de individuos o elementos,
y en esta situación es lo que ocurre
es que hay una posible relación
entre los valores de la tumba.
Volviendo al ejemplo anterior,
podríamos considerar en vez de
dos conjuntos distintos
un único conjunto de personas.
Cada uno de ellos les medimos
tanto el pie izquierdo
como el pie derecho.
Está claro que en este ejemplo
hay una relación
entre la medición del pie, derecho
y el pie izquierdo.
De acuerdo.
Si tienen una talla grande en un pie,
pues va a tener la misma talla
o similar en el otro bien
de acuerdo entonces esta
distinción fundamental
para poder llevar a cabo nuestros
análisis de acuerdo.
Además en este ejemplo,
vemos no solamente que
podamos realizar
el experimento de forma distinta,
sino que situaciones
de una de ellas tiene más
sentido que la otra.
En concreto,
tiene más entidad en la comparación
a partir de las muestras pared,
porque porque si optamos
por la primera opción,
en la muestra fueran independiente,
corremos el riesgo de coger una
población de individuos alto,
por ejemplo, una muestra de
100 personas en planta
y en la segunda una poblada,
con la segunda muestra,
coger una población cuyos individuos
sean más bajos,
por ejemplo, China, por ejemplo, y
observar en la primera muestra
valores más altos,
del pie izquierdo, por ejemplo, y
en la segunda bajó de derecho
y como conclusión final
de del análisis.
Decidí que las mediciones
del pie derecho
son más grandes que el pie izquierdo,
de acuerdo cuando en realidad
nosotros la evidencia,
que tenemos que la medida
es muy parecida,
el comportamiento como Guardiola
tiene que ser casi idéntico.
Entonces, que hay situaciones
donde lo que procede
es realizar un obtención de muestra
variadas de acuerdo,
como es el caso de comprar el pie
izquierdo con el pie derecho,
por tanto, en algunas
situaciones que es
preferible utilizan muestras
de independiente
y, en otros casos muestran pareados
todo depende del estudio
que queramos llevar a cabo
y forma parte del diseño del
experimento previo.
En nuestro caso,
nosotros vamos a tratar con muestras
que han sido obtenidas,
con lo cual no nos vamos a plantear
cuál es el diseño del experimento,
que procede o no.
Simplemente recibiremos un ejercicio
tendremos dos muestra,
y del enunciado del problema
tendremos que decidir en qué
situación estamos de acuerdo.
Entonces, resumiendo, la situación
la podemos ver en esta tabla.
En el caso de muestras independiente
yo voy a tener una variable que es
un bono y una variable coge un
conjunto de individuos,
los cuales me voy haciendo.
Observaciones
de la variable, que es un conjunto
conjunto de individuos,
y cada uno de ellos le
hablan de diciembre.
Ante la variable, parte
de observaciones,
primero fijaron que las
observaciones de la muestra le puesto dos índices.
El primer hace referencia a
que variable corresponde
a la observación y el segundo, su
índice indica el lugar que ocupa.
La observación de la
muestra que ocurre
como es el número de individuos
en el primer caso
es uno en el segundo caso
es en asuntos.
Utilizan su índice bueno,
para hacer referencia a la
variable que es uno
el suministrador.
Para hacer referencia a la
variable que son 2,
esos tamaño te muestran, no
tienen por qué coincidir,
luego en el caso de muertes
independientes
tendremos conjunto diferenciado,
contaba demuestra puede ocurrir
que incluso distintos,
con lo cual genera Motor muestra
de cada una de las variables,
que no tienen por qué coincidir
en tamaño.
Ahora bien, en el caso
de dependiente,
que situación enfrentan,
resulta que las variables
son variables
que se mide por parejas sobre
un mismo individuo,
con lo cual al individuo
primero le haremos una pareja
de observaciones
al indefinido segundo otra pareja
observaciones individuales
otra pareja observaciones
con lo cual al final
tanto muestras tienen que tener
el mismo tamaño de acuerdo.
El concepto de individuo
puede ser muy.
Es un concepto muy amplio,
pues una persona,
pues un objeto puede ser,
por ejemplo, un día
imaginar que yo quiero comparar las
mediciones de niveles de ozono
por la mañana.
Por la tarde procede que
yo tome mediciones
en un conjunto de días separados
por la mañana en autobús,
junto a su pasión por separado.
Por la tarde no, lo razonable
es que día a día
vayamos haciendo la medición por
la mañana y otra por la tarde,
y compraremos esas mediciones por
pareja o lo que es lo mismo,
vuestra pareja de acuerdo, el el.
La diferencia en la toma de
observaciones es importante
porque no tiene, primero, porque
aquí se pueden manejar un,
aquí se maneja un tamaño muy común y
a quienes pueden ser distintos,
y después, desde el punto de vista,
estas observaciones que aparecen
aquí potencialmente pueden tener
relaciones, pueden ser dependientes,
y este análisis no incluye la
dependencia entre uno el insulto,
mientras que el análisis de muestras,
paredes sí que incluye la
dependencia entre la pared,
bueno, espero que haya quedado claro
con los ejemplos y en general
la diferencia entre un caso
y otro y propuesta.
Ahora, en la siguiente,
una vez que leáis la fotocopia y una
vez me refiero al documento,
y una vez que ves el vídeo, vais
a coger la hoja de problemas
propuesta de acuerdo.
Hay una serie de ejercicios
que después el correo,
y en esos ejercicios lo
que os voy a pedir
es que hagáis una distinción,
que vuestro padece,
de si se trata de muestra
independiente o muestra,
es bueno identificar las variables
en cada caso,
como habéis hecho en los problemas
propuesto del tema anterior,
y ahora, si vais a analizar
si vosotros considere
que el ejercicio te muestra variada.
Os voy a pedir que me digáis quien
considere que ese individuo,
el individuo sobre el que
se están haciendo,
la toma de las dos observaciones,
el individuo,
ya digo, puede ser que, como
he dicho el caso anterior
puede ser un día o puede ser
un conjunto de imaginar
que se está tratando de sí
un determinado filtro,
reduce emisiones en los coches.
No puedes imaginar que hace una
medición de emisiones del coche.
Después, coger el coche
le ponéis el filtro
y hacer una segunda medición para
ver cómo son las mediciones.
A posteriori?
Pues los coches serían los individuos
o lo que estoy realizando las
dos observaciones entonces,
identificar si se trata
de muy independiente
o se trata de muestras mareada
y en el caso en que sean muestras
para identificar
quién es el individuo sobre el cual
se hacen las observaciones
que esto se va a pedir en el examen.
Por lo tanto, se soy meticuloso
con esto porque formaba parte
de la puntuación, en el caso,
que haya un problema de este tipo.
Bueno, pues me despido dentro de la
síntomas con este primer vídeo,
y seguimos hablando y reflexionando
sobre la estadística.
Un abrazo.