Idioma:
Español
Fecha:
Subida:
2020-04-03T00:00:00+02:00
Duración:
9m
Lugar:
Videotutoriales
Visitas:
675 visitas
DA11
Análisis Discriminante. Estadística Multivariante
Transcripción
O o decimoprimero y video
discriminante,
donde vamos a ver cómo se hace
ya al discriminante
en la práctica estamos en
la página 87 bueno,
hasta la manera en la que tendremos
nuestros datos siempre vamos
a obtener toque importante variable
numérica que se miden los grupos,
vale para hacerlo dado una
nueva variable variables
son numérica importante y que
vamos a tener una variable
que puede ser numérica o no,
que nos indiquen grupo?
Vale, grupos?
Pueden indicar, pues con
valores alfanuméricos
para no tener cuidado, porque
luego usa a la hora
de poner los grupos y el
orden alfabético.
Mítico?
Vale?
Bueno, esto nos va a indicar, sería
individuo estar en un grupo
en otro y aquí como siempre tenemos
nuestras observaciones omega
o sin preferí con la actuación
del tema anterior,
os unos que son nuestros individuos
a diferencia del tema anterior?
Aquí estos individuos no forman
una muestra aleatoria,
siempre para ello tenemos
que separar los grupos.
Entonces, si bajémoslos osos
j, tal que j tienen,
jota igual a una constante,
vale decir?
Cogemos a los individuos que no
grupo, eso sí va a ser una muestra,
la antonia simple de las variables
de ese vector directorio
que tiene con ese.
En algunos casos hemos supuesto.
Son normales, vale con matriz
de covarianzas y medidas
en algunos casos.
La matriz covarianzas son bueno.
Por lo tanto, la manera de calcular
medias, covarianzas etc.
Cambia un poquito.
Con respecto a lo que hemos hecho
un componente principal
es porque hay que hacerlo
por grupos padre.
Por ejemplo, si queremos
hacer las medias,
se puede calcular la media
de todos los individuos,
pero eso no tiene ningún sentido,
sino que lo que tenemos que hacer
en la media del grupo jota
vale para ello.
Cogemos todos los que tienen
una variable.
La variable del grupo junta da
igual, Hadj, suponemos, por ejemplo,
que los indicadores aquí voy
a simplemente números
que nos indica.
Por ejemplo,
uno que está en el grupo 1, etcétera.
Normalmente aparecen ordenados,
pero no es necesario.
Pues no lo mismo, pasaríamos
la matriz de covarianzas.
Si queremos estimar la Madrid de
covarianzas del grupo jota,
pues solamente tenemos que coger
a los individuos de grupo
junto a el 1, la función
indicador que nos dice
unos y la verdad.
Luego solamente cogemos los
individuos del grupo j,
a los que le restamos sus medias
puestos de medias,
y, de esta manera, con el vector
columna y vector fila,
igual que hacíamos en
sistema anterior,
pero solo con un grupo j, y en
j es el tamaño del grupo,
se calcula la matriz de covardia.
Fijaros que necesitamos, al menos
-2 individuos en el grupo.
Cada grupo para poder calcular
la matriz de covarianzas,
y no se puede, no se puede
hacer este método.
Necesitamos, al menos -2 individuos.
Calidad bastante más para
que funcione bien.
Se tienen que ser porque no vale.
Bueno, esa es la variedad de
calcular la distribución óptima,
la matriz de cabañas que no
conocemos y la conocemos estimarla
y lo mismo medias se sabe
su distribución
y hablamos de ella en
el tema anterior,
que huesos y ahora ya
pasaríamos a verlo.
Qué pasa si suponemos?
Claro, ya no estamos seguros,
en teoría,
que las matrices de covarianzas
de los grupos son iguales,
es decir, si queremos hacer un
análisis discriminante lineal,
bueno, pues en este caso lo que
tenemos que hacer es estimar
esta matriz v, que es la matriz
y cómo se pueden hacer
de forma óptima.
Pues muy sencillo.
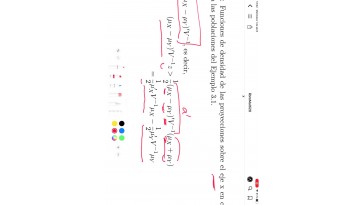
Van esta formulada aquí.
Esto es lo que se llama la matriz
de varianza en ingleses.
Pule ponderada,
podríamos traducir, vale, en la
que, para estimar un común
en todos usaremos estas estimaciones
de cada grupo,
todas ellas son buenas estimaciones.
Pensarán.
Mejores estimaciones.
Cuanto más grandes de su tamaño
vale que pudo usar,
como siempre es la demanda
de covarianzas,
o la matriz de cuasi-covarianzas,
vale obligando por cuasi covarianzas
por el peso que tiene esa estimación.
Que en j menos -1 se puede obtener.
El mejor estibadores había
dado para banau vale?
Es la fórmula que gusana r.
Cuando hagamos un análisis
discriminante lineal,
para estimar extra materia
desconocido vale
Una vez que v estimada pues la
fórmula que hemos visto
en teoría simplemente, pues él añade.
Gorros a todo.
Es decir, la función discriminante
lineal de Fisher muestral, que es la
que vamos a ver en prácticas,
pues era el borro z son
dos variables,
son fórmulas, será abor que
sea una estimación, vea,
vale o de manera ese domingo,
pero vale,
estimamos la media de cada grupo
y estimamos la materia
de covarianzas.
Como con la fórmula que hemos
visto cta son las patria,
vale?
Bueno, todo lo demás se hace
exactamente igual,
la probabilidad tipo uno estimada
pues lo único que hacemos
es usar las normales, tanda
silenciándola normales,
tanda un y variante y aquí
en vez de poner
del pues se pone una aproximación,
del que está gorro.
En la distancia embajada
no vi muestra que también había
usado ya los componentes principales,
que la misma vale en este caso.
La estancia entre las dos
medias pero usando
la Madrid covarianzas, estimada, que
está vuelve a ser la misma vale,
vale?
Bueno, a partir de aquí la función
criminal, discriminante, fis pinta,
se puede clasificar acepta
todo, etcétera,
vale, todo lo que hemos visto,
teórico como se puede hacer
exactamente igual,
y lo mismo pasa con sea
más de dos grupos.
O si creamos usarla lineales,
también nos vale para dos grupos,
pues cogeríamos la fórmula
correspondiente
y le pondríamos por todo menos hace.
Vale, acordó estas se calculaba,
daba donde fuese, máximo vale?
Aquí significaba recordar la función
discriminante era mayor
que estaba en el grupo de que vale?
Pues ahora hablaremos
todo con vale en r.
Las recta automática se 70 de
haber sido mayor que cero
o menos vale; herreno usa
esa utiliza otras.
Recordamos que daba igual porque
se podía multiplicar
por anda siempre que no fuese 0.
También se pueden hacer las
proyecciones canónicas,
que sería exactamente lo
mismo que hemos visto,
pero usando vale.
Y si pasamos al análisis
discriminante cuadrática
sería un caso en el que suponemos
que las covarianzas son iguales.
Entonces esta sería la fórmula
de cada grupo,
donde la principal diferencia es
que ahora ya directamente
no seamos sube gorro, sino que
en cada grupo usamos qbe,
gorros u, y con la fórmula que hemos
visto aquí se clasifica
en donde se hace mínima esta
distancia embajada.
La no avis, está formada
mediante esta parte.
Si queremos esta es la
que va a decir.
Queremos transformarla,
pues y usar solo malas novelistas
excusar está aquí.
Bueno, esto, esto se basa en que hay
normalidad, etc. Y por lo tanto,
pues hay muchas hipótesis, las
covarianzas son iguales,
no son iguales que métodos usamos,
está claro la práctica,
cuál se usa?
Vale para todo ello?
Para dar una cierta seguridad,
métodos.
Pues vamos a ver en el
vídeo siguiente,
qué significa la validación,
cruzada, y cómo se puede aplicar?
A para determinar qué método usa
y si el método de fiable conocía
Propietarios
Jorge Luis Navarro Camacho
Comentarios
Nuevo comentario
Serie: Análisis Discriminante (DA) (+información)
Estadística Multivariante