Idioma:
Español
Fecha:
Subida:
2022-09-16T00:00:00+02:00
Duración:
46m 16s
Lugar:
Videotutoriales
Visitas:
858 visitas
Hércules. Formación. DESARROLLADORES. Enriquecimiento de información. Similitud
Transcripción (generada automáticamente)
Agravando.
La formación que has tocado y es la
segunda parte que tiene que ver
con el enriquecimiento en relación
con el análisis
de la obtención de similitud
entre entonces,
los temas que vamos a ver
a la parte serían.
Los experimentos sobre similares sin
servicio de detección de arreos,
instalación y temo esta parte
la compañeros por ahí
sabía Kevin Schwantz y a
continuación cómo hacemos la integración
de los resultados de la similitud
en LiterCast,
desarrollo, que fundamentalmente es
la ficha de cada publicación.
Entonces, sin más preámbulos,
salían podéis compartir los
comensales, con vuestra parte,
yo estaba muy nerviosa.
Si me puede confirmar que la
pantalla no, pero ellos sí si ahora encima.
Pues-como estaba comentando
la sesión de hoy.
Está enfocada a explicar el módulo
de un módulo de equitación
de reos similares está integrado,
el módulo principal de
enriquecimiento semántico
por recordar cuáles son las
capacidades que tendría
que tener este módulo para
identificar RO similares.
Acudimos al los pliegos técnicos y
se mencionaban 3, un funcionario
y centrarnos en lo más importante.
Por un lado, el modelo tiene que
ser capaz de determinar las.
Entre los textos que
corresponden a 2,
que pueden ser artículos científicos,
protocolos o o descripciones
de proyectos
de estas similitudes semántica,
de alguna manera tiene que ir
más allá de lo que es una,
una convergencia del léxico; no
similitud, léxico gráfica
sin parar la intersección entre
las palabras que hay
en los 2 puestos.
Por otro lado, el módulo
tiene que ser capaz
de explicar esa relación de
similitud entre los textos al usuario.
En nuestro caso, vamos a explicar
a continuación,
pues hemos optado por implementar
esa esa capacidad
de explicar las relaciones
mediante la selección
de las de los escritores
más relevante.
Esas relaciones os voy a comentar
la experimentación previa.
Hemos realizado a la hora de modo
de cara a determinar que hemos
implementado el módulo,
la versión definitiva del módulo
para la llevar a cabo
la experimentación.
En primer lugar, generamos
una serie de da clases
conjunto de datos para el
caso de los Pirineos,
constituida por alrededor de 300.000
Lastras el caso de los protocolos,
la tasa, que incluía casi 3.500
protocolos en el caso
de los proyectos de códigos,
casi 60.000 fichas
de del proyecto para evaluar
la similitud,
lo que hemos hecho es
de cada 1 de estos.
Se han seleccionado
20 de manera notoriamente ejemplo
ventas, tras 20 protocolos,
y luego lo que se va a evaluar
es el ranking de similares,
que el sistema devuelve para
cada 1 de esos 20 ejemplos
y de manera manual se evalúan las 5,
los 5 primeros y 3 de esos
nuevos enfoques
que tuvimos en cuenta tomamos
en consideración a la hora
de la experimentación.
Básicamente se reduce en 2.
Sería el enfoque clásico.
Es calcular las similitudes más a A,
representaciones vectoriales
de los textos de Bolsa.
Palabras bajo por cada texto.
Se seleccionan todas todas
las palabras,
si un cálculo estadístico
te genera un vector
a la hora de hacer esa selección
de palabras,
tienen.
Elimina las palabras las palabras
más frecuentes,
las palabras poco frecuentes.
En una serie de filtros estándar
una vez que tenemos la
representación vectorial del texto,
se calculará el método más utilizado
y más más clásico.
También.
El programa es una variante
de este método clásico
que la selección de palabras
para construir el vector se reducen
a los escritores extraídos
por el módulo que explicamos
en la sesión del lunes
y los cacos.
La siguiente variante que analizamos
es una variante que de alguna manera
se adecúa a lo que es el estado
de la lengua natural
hoy en día para abordar
la tarea del TS,
que quiere abordar en este escenario
se mantiene los enfoques más exitosos
en representaciones de
los documentos.
Las representaciones se construyen
a partir de modelos de modelos
del lenguaje neuronales, otras
formas por ejemplo pero en este caso
por cada documento se construyeron
una representación densa.
No se tienen, no se incluyen
todas las palabras
sino de alguna manera
conceptos más más.
Hemos utilizado la arquitectura bien
codearse de alguna manera
se ajusta buenos.
Carlos modelos.
Ver ajustarlo a la tarea de un
objetivo que es maximizar
cuando se hace en.
El seno del del entrenamiento pues
no, no hay verja escaso,
no quedan, que se calcula a partir
de las representaciones
que dan los los entonces.
Modelos versos en los que los pesos
van ajustando para obtener.
Para minimizar esa ese día hemos
estudiado 2 variantes,
utilizamos los monolingües
para el inglés.
Eso quiere decir
que no podríamos calcular la
similitud entre 2 textos.
Para abordar esa tarea la
similitud se mantiene.
Hemos analizado también una
variante que en este caso
más aún mayor de lo que utilizamos
hoy nos tenemos que ir como sea.
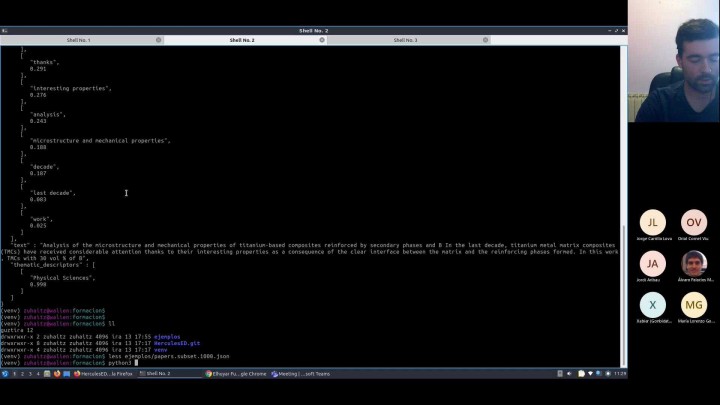
Estos son la tabla.
Se pueden ver los resultados que
hemos obtenido mismos enfoques
y cada una de las variantes puede
ver que la aproximación clásica
únicamente representación no digamos
utilizando todos todas las palabras
utilizando el paradigma o
más u otras cuestiones.
No tenemos la precisión media
analizando los 5 primeros del
los para los 20 ejemplos
declarada en este caso, pistas
que obtenemos una señora 3,
55 si hacemos las inyecciones algo,
escritores, baja de 8;
serían los resultados para
la aproximación basada,
consiguiendo un paradigma debajo,
la resultados para las Milito
si utilizando modelos basados en
modelos empleados neuronales,
pues observamos que la precisión
es mucho más apta.
En el caso de las web
vamos un poquito.
Esto es normal.
Tiene que contemplar más idiomas,
algo de ruido lo sigue siendo
una pensión muy competitiva
y suficiente para llevarlo
a un entorno.
Entonces, el enfoque que
se ha implementado
en el servicio se ha basado en
la arquitectura vaya a poder
y queda la opción de utilizar
tanto moderados,
monolingües como como la capacidad
que se mencionaba.
Los pliegos de una explicación.
Nadie de alguna manera este módulo.
Este modelo tiene
que además de aportarlos por
cada documento de texto
de entrada los similares similares
para cada reo similares
de algo similar de alguna manera
ofrece una explicación.
En este caso la explicación
se limita a mostrar
los escritores que son relevantes;
a esa relación de similitud nos
hemos analizado para implementar
esa tarea básico que básicamente
lo que hace escriptores
es un texto con una simple sombra,
enfoques más más avanzado,
se basa en modelos neuronales.
También selecciona los escritores
más relevantes
a la, la relación de similitud
pero, calculando de alguna
manera los escriptores,
los 2 documentos que son más
cercanos al promedio de la representación
semántica de los textos
de los 2 textos.
Documentos 1 2,
aquí lo que se ha hecho es una
evaluación cualitativa,
y se ha observado que avanzan
los mejores resultados.
Esto es el resumen de
la experimentación
que se ha realizado para consolidar
los enfoques
e integrar.
Ahora le voy a pasar la palabra a
mis compañeros, o es ofrecer,
nos va a explicar de qué manera
están implementados estos enfoques
y cómo pueden ser utilizados.
Vale Hola Buenos días entonces
yo voy a explicar bueno voy
a compartir la pantalla.
Vale.
Vale, pues suele explicar cómo
podemos instalar este servicio
y luego veremos qué métodos tiene.
Este ya está aquí y para finalizar,
veremos un par de ejemplos para ver
el servicio en funcionamiento.
Vale?
Entonces, a ver,
la función principal
de este servicio,
como como nos ha explicado Xavier
es devolvernos similares
de otro reo, vale, pero para
ello tiene que comparar,
dicho hebreo, con el resto de reos
de la colección que pueden ser miles
o incluso millones Vale.
Entonces, sería muy ineficiente
compararlos al momento.
Entonces, lo que hacemos
es, a la hora
de introducir un nuevo Rho, la
colección, hacer esa comparación,
generar un índice donde el carácter
tienen los por defecto.
Los 10 más similares están.
Encontraba hasta el momento vale?
Y eso se actualiza ese índice,
entonces, de esta forma,
lo que conseguimos es más ligera.
Bueno, el proceso de insertar nuevos
documentos es más pesado,
pero conseguimos que la función
principal del servicio,
que está devolvernos
las más similares
sea más más eficientes Vale entonces
vale con la introducción
como ya pasara vamos a ver un poco
los pasos a seguir para instalar
este servicio,
como dije el otro día.
Bueno, en este caso también
tenemos el con todos,
por lo que, bueno, con ejecutar
este sencillo comando
sería suficiente para crearnos
el contenedor
y ejecutar el servicio.
Quedaría ya automáticamente
el servicio
escuchando por defecto
en el puerto 5.081
vale?
En cualquier caso, si queremos seguir
todos los pasos desde el principio
para la instalación,
lo que tendríamos que hacer es
crear un entorno virtual
de instalar las tendencias que
están dentro del punto.
Vara ir dando los pasos
en la terminal.
Vale, aquí tengo el entorno actual,
lo tengo activado ya.
Para el siguiente paso sería el
archivo de configuración.
Para ello tenemos que copiar
el con la plantilla
de la configuración se encuentra
en el repositorio.
Esta pestaña estoy.
Dentro del repositorio Vall
-aquí estaría él.
Aquí tengo el concepto y
eso y tenemos solo 2.
Bueno, solo 2 parámetros
cuales 1 es si queremos
utilizar la ACP o GP
y el modelo que se va a utilizar en
este caso recomendamos utilizar
que está por defecto, vale?
Una vez que tengamos el archivo
de configuración solo
tenemos que ejecutar 1.
En este caso voy a utilizar el
servidor integrado de flash vale
pero bueno para ponerlo en
producción siempre conviene utilizar o apache,
o en nexo o un servicio más, más
robusto y más avanzado.
De momento no voy a estar así.
Esto les da unos 10 segundos.
Que tengamos el servicio en marcha,
pasaremos a ver los los
métodos del servicio.
Aquí vemos que tenemos un punto
para ser reo individuales.
De esta forma podemos insertar y
recuperar de forma individual
y eliminarlos también.
Luego tendremos colección,
que es prácticamente
lo mismo, pero en este
caso los artículos,
los lotes vale para que
sea más eficiente
y, por último similar,
que espera obtener,
ya sea pares y tenemos otro
más rebeldes ránkings?
Bueno, esto ya como sale adelante,
sería para actualizar o regenerar
el índice que os mencionaba antes.
Vale.
Vamos a ver un par de ejemplos.
Primero, para introducir un nuevo
RO utilizaríamos métodos de reo
aquí se explican todos los
parámetros, pero bueno,
son básicamente el identificador
del LRO,
el tipo de reo.
En este caso sería un artículo
científico,
el texto, los autores.
Luego los escriptores, tanto
temáticos como específicos,
son los que vimos el otro día.
Sí se menciona también, bueno,
introducir un error en el servicio.
Tarda, aproximadamente, 2 segundos
vale tanto en pero como si
lo que queremos es insertar muchos
reo sería más conveniente
utilizar o el método
post de conexión,
o esto lo voy a explicar
un poco más adelante.
El script.
Qué se encontrarán este repositorio
indexar Herreros
vale.
Es, y en ese caso si utilizamos
una o sí esto va mucho más rápido
porque tardaría entorno
a los 2 segundos introducir
1.000 reos.
En el caso del aceptado 23
segundos en un principio
pienso que sería suficiente
con cómo utilizarla.
Es el ejemplo falso armó
-radiactiva e nada, pero
no era un problema,
te encuentras mal Susana, al final
se escucha muy bueno.
Afirmó.
No sé si es una pregunta o
lo que estoy escuchando
es alguien.
Vale para entonces así bala entonces,
iba a ejecutar el ejemplo.
Tengo aquí ejemplo preparado.
Soy el mismo, creo que
está en el ritmo
si ejecutó el comando, lo voy a
hacer con para que sea más sencillo.
Por aquí.
Vale.
Pues como es el primer reo que
introducimos no tiene
que actualizar ningún
índice, es bueno.
Ha tardado nada milésimas.
Vale?
Entonces sabrá
si intentamos recuperar Sr el método.
También lo tengo por aquí.
No pasó.
Le diremos que nos devuelve
a todos los parámetros.
De esta forma podemos
introducir serbio,
pero como he dicho antes, la forma
más eficiente de hacer.
Esto sería utilizar un método
post de recolección,
pero en este caso luego tendríamos
que llamar al ránking
para que actualice o para generar
el índice desde 0.
Vale?
Entonces, es más conveniente
utilizar.
Este se encuentra en 1 de útil.
Perdón, lo mejor dentro
de la carpeta.
Vale.
Te haces de forma implícita
introducirlos erróneos y regenerar.
Tengo aquí un archivo con, me
parece que en 1.000 reos
puedes saber una parte del archivo.
Son 1.000 artículos científicos
con sus abstracto y títulos.
Vale.
Voy a utilizar para introducirnos,
tenemos que ir hasta el proyecto.
R y ahora nombre del archivo.
Y esto en mi ordenador tardaría
en torno a un minuto.
Pero si utilizamos una o más potente,
pues la mitad, o incluso menos, vale.
Voy a volver a las tablas
de la que entonces nos queda por
ver el método de la colección,
en este caso nos serviría
para obtener
todos los identificadores
de los identificadores
de todos los que hemos introducido
hasta el momento.
Pero en este caso sí que tenemos
que indicar el tipo de artículos
científicos o proyectos de código.
Es joya.
No voy a copiar, porque la
dirección es diferente.
Se espera que termine
de introducir los.
Esto nos devolvería solo
los identificadores,
vale y luego así nos interesa.
Recuperar todos los atributos
de un río en concreto,
pues ya el de alguien que
se ha mostrado antes.
En balas, listo.
Vale, en 2008 creó identificadores,
vale, por último, nos quedaría por
ver la función principal.
Vale?
Le pone en seria similar método
que entonces identificado
Ortega, 1 de los RO.
Lo encuentro tendría que devolver
los idiomas similares
de la colección de esos 1.000 reos
que acabamos de introducir.
Este sería el comando, este caso
ya estén identificados.
También tenemos que indicar
el tipo de herrero,
vale?
En este caso podemos cruzar los
tipos de río y solicitar,
por ejemplo los 10 artículos más
similares de un proyecto
o los proyectos más similares
de un artículo
o todas las combinaciones posibles
en este caso quiero
que me devuelvan los artículos.
Como el índice ya estaba creado,
en este caso lo único que tenía
que hacer es era buscar
la entrada correspondiente
en el índice
y nos devuelve los 10 artículos
más similares,
no solo los identificadores,
sino que también.
Esto es bueno en esta lista
debemos una serie
de escriptores específicos que
serían de alguna forma
lo que justifica no los que explican
las similitudes entre estos 2.
Esto quiere decir que, por
ejemplo, el concepto
Titanium metal matriz es relevante.
En ambos vale?
Este número sería el grado de
similitud de este concepto
comparando con los 2 más 2.
Vale?
Bueno y con esto terminaría
ya esta parte,
un principio.
No tengo nada más que comentar.
Dejar de compartir la pantalla, vale
ahora con la siguiente parte,
que básicamente es como hemos
integrado este este servicio
dentro de lo que es la la, la web de.
Vale.
Aquí estaremos dentro de este punto,
el enriquecimiento de información
por similitud integración
de los resultados,
como hemos integrado en el servicio
que acaba de despegar
dentro de la del agua.
Dentro de este modo lo vamos a ver
cómo hacemos para tratar los datos
dentro del servicio de similitud
posteriormente,
como los explotamos dentro del agua.
También, en primer lugar, para la
carga de los datos tenemos un
un servicio que es el normalizado,
que entre otras tareas
se encarga de normalizar cosas
que están dentro del sistema
y que otras se encarga
de de sincronizar,
digamos, las las publicaciones
que están dadas de alta
en el sistema, con, con los índices
que estarían dentro de este servicio
para que se mantenga actualizado y
posteriormente se puede explotar.
Pues el código del estaría en vea.
Aquí y ahora voy a enseñar cómo
funcionaría este servicio.
Vale para encargo.
Servir café varias cosas pero entre
otras vale por defecto
Cuando se arranca el servicio se
ejecuta un una normalización
de todo lo que hay en el sistema
y luego, finalmente, se configura
a través de una expresión
con la frecuencia en la que se tiene
que ejecutar esta normalidad.
Ahora, por ejemplo, en el entorno
que tenemos montado
lo ejecutamos todos los días,
a las 2 de la mañana.
Creo recordar.
Llegados a este punto, este método
haría una de muchos gastos,
pero lo que nos interesa
en este punto
sería estafa vale para qué.
Vale, vale.
El primer lugar que tenemos.
Tenemos estos 2 métodos.
Con este método, loable, lo que
hacemos es recuperarlos,
lo identificadores de los elementos
que están cargados en el servicio.
Similar era.
Para ello,
la petición que nos ha enseñado
a obtener todos los.
Tienen jugadores que están cerrados.
En el sistema tendríamos
estos 3.738 elementos
que se correspondería con
mucho grandísimo.
Tenemos 744.
Bueno, creo que debería decidir cuál
es el número de publicaciones
y tendríamos los que están cargados
en el servicio de criminalidad
y éstos serían los encargados
en el sistema.
Entonces estos realizamos eliminación
o modificación de los datos que
estaban dentro del servicio
de que paguemos los que
están cargados,
excepto los que hay que cargar
y si se hubiera cargado alguno que
no debería estar eliminado.
Lo haría.
Posteriormente se aplica el inverso.
Esto señalan que deberían
estar destartalados
y éstos están acordados.
Por ejemplo, para hacer una
prueba muy singular.
Vamos a poner, hipotéticamente,
no hubiese ninguno cargado
otro método.
Todo lo que hace es obtener
todos los datos
de los elementos que queremos.
El servicio de a dejar hace
diferentes consultas
a la base de datos, a
través de la app,
para obtener.
Para tener todos los datos
necesarios para cargar en el servicio de similar
llegar ese día los elementos,
nombres de los autores, las piezas,
junto a un peso, las vías,
junto a su peso
dentro de la pública,
tendríamos la de estos 3.700
pico publicaciones.
Con el identificador,
quienes valor tendríamos estos
datos, el tipo y los equipos,
junto con su peso, el texto en
cuestión de la descripción
y los escritores telemáticos, punto.
Entonces se procedería a la carga,
a la carga dentro del servicio
de similar,
ya atacando el método que había
enseñado antes tu servicio
y entonces, cuando se esté.
Tendríamos cargado de similitud
todos los datos necesarios
para que se puedan explotar luego
dentro de la dentro del agua.
Y ahora pasamos a cómo sería la
explotación de estos brazos,
una vez que esta encara estos datos
se explotan dentro de las fichas
de las publicaciones dentro
de las pestañas
de relacionado.
Vamos a el buscador de publicaciones
por ejemplo está vale la pestaña
de relacionados más similares
digamos a la publicación que estamos
se cargaban con un buscador al igual
que en el resto de páginas,
podría retirar esa publicación
y se podría terminar.
La búsqueda.
Si se quisiera todas las
facetas que dan.
En todos los buscadores que tenemos,
los muestran publicaciones.
Veamos.
El loco es que cuando se entra
dentro de la, siempre,
la de la ficha.
Cuando se entra dentro de la pizza
una petición a un servicio
que tenemos montado que por detrás
va a llamar al servicio de similitud
para obtenerlos.
Los similares de este recurso,
tanto del plan en la página
como cuando se pulsa sobre
esta pestaña está.
Es esta estar, aquí es similar
y documentos,
lanza contra él, un servicio
que tenemos
montado que se usa para otras cosas.
Adicionalmente, servicios,
lo que va por detrás es
hacer una petición al servicio
de similar edad.
Nos va a devolver esto es.
Vale, que nos vendría los lo casetas
publicaciones similares,
junto con los escritores
enseñado antes,
con los pesos este servicio.
Sería especial.
Vale.
Veía de nuevo.
El dopaje, como parámetro de entrada.
El identificador de la publicación
que estamos viendo.
Vale, y esto lo hace por detrás.
Tenemos el tipo de recurso que
estábamos viendo en este caso
sería una pública y esto
lo vamos a esperar.
Piensa hacer una petición al
servicio de similar edad?
Volvería.
Esto es lo que serían las
publicaciones más similares.
Y sus pesos, cuando termina la.
No, eso nos lavamos las
publicaciones más similares
hasta que estamos viviendo este día.
Veremos aquí con estos actores.
Señaladas en el servicio
externo tiene eso?
Dentro de este controlador,
que está mezclado, que es el que
se encarga de devolver,
lo siguen las publicaciones,
punto las etiquetas
y el peso de las Vegas.
Una vez que tenemos dentro
del está esta respuesta,
vamos a utilizar el servicio
de taxi de resultados.
Para montar esta esta búsqueda.
Vale, para lanzar esta búsqueda,
vimos que tenemos los
identificadores de las.
Tenemos las publicaciones y entonces,
como llama en otra demo pasada,
tenemos una cosa que son los.
Los personalizados básicamente
son jueves para que el servicio
de resultados
y de ventas ejecuten pasándole
unos parámetros.
En este caso se está utilizando
este ser personalizado.
Básicamente es una, es, es un
fragmento de una parte
en la cual se le pasan unos
parámetros y esos parámetros
se traducen en un acuerdo para
que veas la perdón,
para obtenerlos los recursos que
estaban hablando, por ejemplo,
si se pierde esta página puesto.
Esto realizada.
Pero un segundo, esto realizado al
servicio de resultados pasándole
como parámetros dentro de unos
y desde todos los elementos
contó con un peso de creciente
para que cuando se listen los
elementos del mismo orden
en el que han sido devueltas por
el servicio de similar edad.
Y para para ver el por qué
esta singularidad
cuando se completa la carga de
los resultados que cuenta.
Ojalá esté aquí cursos similitud.
Lo que no.
Por desgracia, tenemos el objeto
dentro del cargo,
tenemos cargados un objeto,
con los identificadores de los
de los reos similares,
junto con los escritores que
especifican la similitud de,
lo que es que un.
Hubo.
Este sábado, que tenemos
plagado esta variable,
los los digamos a cargar un tapón,
la inspectores y sus pesos,
y lo que hace es recorrerse los
elementos están pintados
dentro del dentro del contenedor.
En el listado de las publicaciones
se recorren las etiquetas.
Qué tienen los que tienen
estas publicaciones
y las marcas de color rojo
para presentar el?
Por qué de esta similitud,
por ejemplo, tendríamos.
Un poco más.
Por ejemplo, estaría marcado
en rojo llegamos.
Los sectores específicos que
dictaminan, digamos,
el hecho de por qué esta publicación
es similar,
es similar a esta obra pública.
Seguramente es una transcripción de
las publicaciones de estos 2
es por ello que el servicio
ha terminado.
Estos estas publicaciones y la
publicación principal este día.
Esta sería la explicación del
por qué estos elementos
se muestran como relacionarnos
dentro de esta.
Publica.
Y en principio con Con esto estaría
ya explicada esta implementación
del servicio de similar edad dentro
de la de la de la web de ver,
voy a parar un segundo
de la grabación
por aquí estaría esto concluido
y luego la daré otra para
las posibles preguntas.
Vale?
.
Propietarios
Proyecto Hércules
Comentarios
Nuevo comentario
Serie: FORMACION EDMA Desarrolladores (+información)
EDMA Desarrollo
Relaccionados
Videotutorial de introducción a la aplicación
Videotutorial de expediente de interesado iniciado en el ‘Registro General Auxiliar’
Videotutorial de acciones disponibles
Tests automatizados de accesibilidad de frontend
Resumen de cómo está la UI en Mi campus

Madeja ATICA
Análisis de dependencias de la BD
Impulsar expediente
Charla interna de formación
Desarrollo con DDD y Arquitectura Hexagonal
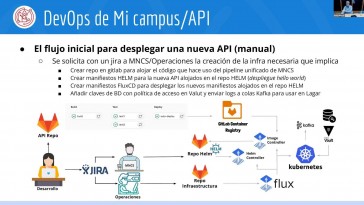
20230329 - Desarrollo Backend en Cloud - Sesión 4
20230322 - Desarrollo Backend en Cloud - Sesión 3

20230315 - Desarrollo Backend en Cloud - Sesión 2

20230308 - Desarrollo Backend en Cloud - Sesión 1
