
Idioma:
Español
Fecha:
Subida:
2021-03-17T00:00:00+01:00
Duración:
38m 26s
Lugar:
Curso
Visitas:
1.168 visitas
01_Marco teórico
Transcripción (generada automáticamente)
Yo no sé si no hay nadie,
como tú veas.
Si vamos a ver, si no
va a haber, además,
hacemos una exprés en una cuenta
hasta ahora no puede contar.
Vale,
pues como tú quieras que entendí,
que tenía preparado,
pues en principio eran
hasta cinco horas.
Así que dejé claro.
Pero bueno, a mí.
No sé cuánto me he tragado haberle
dicho que se mantiene vivo,
ya que este es un poquito distinta.
Al final vamos a hablar
principalmente la librería,
descubrimiento que nos ha dado
entidades, no, eso es eso
sí lo que buscamos
es eso, ser un poquito si
quieres hacer una cosa
y eso no vale, yo te voy
yo te voy a eso
porque era así; si en
una hora lo vemos,
no sé si ha tenido una
parte práctica,
lo mejor,
si vale es así que luego ya queda
la isla y la presentas;
tú digamos la presentada para que
se quede, se quede grabada,
pero si quieres, claro, tampoco
te quiero estropear
el que la grabación es
a lo mejor de él
o alguien pero que sí podemos ir más
deprisa no no no no te preocupes
En principio yo creo que
lo suyo es adaptarse,
al que está claro que hay por
mucho que esté preparada
para una cosa y eso le puede
llevar y luego ahí ya
es que tengo que salir.
Si la posibilidad de que si
lo vemos en una obra,
pues mira, si ya me libero
el resto de la mañana.
Se buscará algo como colofón a la
parte teórica balear posible.
Intento centrarme algunas partes
para que le íbamos viendo nada
venga venga tienes que grabar
me parece tienen
que tienes que ponerlo, agravar,
en teoría ya lo está así;
si está puesto en y lo
veo, venga adelante.
Pues nada, un poquito lo que
lo que hemos hablado.
Vamos a hablar de descubrimiento,
comparación de entidades.
Entre ellos vamos a hablar
de distintas
a las distintas librerías.
En este proyecto, por un lado,
en la librería descubrimiento
que hace la que hace,
efectivamente tenemos la Federación,
la Federación es la que permita
la librería descubrimiento,
extraer datos, es decir, es
el módulo que interactúa
con los datos que hacen las
cargas necesarios.
Tenemos el serbio Discovery es un
servicio de descubrimiento
que básicamente permite
este proyecto,
está orientado para funcionar
con distintos modelos,
entonces el servir Discovery
y digamos
que es el pegamento para todos ellos,
hay que conocer la ubicación
de cada uno de los lobos,
y los datos tenemos en
la factoría de.
Es la librería que genera para
cada uno de los recursos
siguiéndoles tema que saber,
sino al proyecto y los criterios
clanes y bueno,
entre otros, que no vamos a llegar,
tenemos mal conjunto de métricas
que nos permite seleccionar
los triples más adecuados
para la grabación de datos.
La librería, descubrimiento
tiene distintos módulos,
tiene el módulo de la reconciliación
de entidades,
tiene el módulo de descubrimiento
de enlaces,
la reconciliación de entidades.
Se trataría de buscar similitudes
dentro del mismo modo,
es decir, por ejemplo, la
Universidad de Murcia,
aquellas entidades dentro
de la propia
Universidad de Murcia
que sean similares.
Si un descubrimiento enlaces,
hablaría de edades similares
en otros ámbitos, por ejemplo, en
otras universidades o en la nube;
los, por ejemplo, datos de Kidal,
uso de cualquier otra
fuente de datos,
aquí lo que tenemos es un un
esquema donde podemos ver
en el nuevo uno duplicados
relativos a la misma,
a la misma entidad dentro del
mismo modo, por ejemplo,
la Universidad de Murcia.
En ese caso, cómo acabamos de decir?
Pues estaríamos hablando
de un duplicado.
Si esa relación la encontrase
con 8, por ejemplo,
la Universidad de Oviedo en este
caso tendríamos que hablar de un link
sea la persona de, tendría una
relación con la persona b
y si lo encontraremos
dentro de la nube,
los estaríamos hablando de externo.
En ese caso
sería sería un venga externo hacia
una entidad almacenar opus
en cualquier área o en
cualquier otro.
En cuanto a la reconciliación
de entidades,
el aumento de datos justifica
justificar esto.
Se estima que en 2025 habrá
aproximadamente 10
elevado a 21 países o se ha elevado
a nueve en el mundo,
y eso hace que se requieran
herramientas para garantizar
la integridad de los datos y
y evitar los duplicados
profundamente estudiado.
Una uno es una, una rama de
la investigación activa
y abierta múltiples.
Tienen múltiples aplicaciones
de crear.
Los datos y cena basuras,
tiene basura,
es un problema no trivial
distintas, represión,
representaciones para los valores.
Valen lo mismo, atributo, distintas,
convenciones según el momento.
En el tiempo se vuelven
nacionalidades, culturas,
errores a la hora de introducir los
datos, distintos tipos de datos.
Por lo tanto, es necesario
distintas funciones.
Para evaluar la similitud,
también es relevante la importancia
variable de los votos;
no todos los atributos tienen
la misma capacidad
para discriminar una entidad de otra.
Cuánto valen quienes sí podemos
decir que es el proceso
por el cual se busca vincular
entidades entre distintas fuentes,
reconocimiento típicamente
puedes Garner?
Es la tarea de extracción
de información que a partir de a
partir del texto hará Armada
encontrar entidades como personas
organizaciones
lugares lesiones tiempo cantidades
encontradas en tiempo
y bueno básicamente este no va a
ser el objetivo de la librería
descubrimiento, la de esa emigración
entidades, o sea,
es la labor de estas islas, impedía
la labor de la librería
de descubrimiento y es la
parte que es la parte
de comparación de entidades,
bien para distintos vaqueros
dentro de la novela,
y luego tenemos el registro;
es la vinculación real,
consiste en encontrar relaciones,
empleados genios como por ejemplo
el módulo de la Fed,
del que hablaremos posteriormente.
Los objetivos dentro del proyecto
es, por un lado,
evitar duplicados dentro
del mismo paquete
es crear enlaces entre los
distintos paquetes;
esa misma instancia es decir si
encontramos cierto investigador
en una instancia y en otra, crear
los enlaces que apunten al otro
minimizar la intervención
humana, pero Faffe,
y a la vez facilitar la labor de
vecino rumano en los casos
en que no fuese suficiente para
llevar una acción automática
y crear enlaces a instancias
almacenadas.
Tienen tantas la novela en
referencia a la misma instancia
es almacenadas en el bracket,
de forma que los datos
almacenados pueden ser completado
la información de asistencias
para evaluar el proyecto.
Hemos evaluado primeramente
funciones comerciales
como como el módulo, de estar dos
o y hemos evaluado también
la posibilidad de una implementación,
y, finalmente, nos hemos decidido
por una implementación lado
para evitar las distintas compañías
y, bueno, en el pliego tenemos un
requisito que es poder cambiar,
en triples Thor en cualquiera
de los de los logros
y, bueno, las soluciones
que hemos mencionado
no nos vinculan directamente
con los triples
Thor que las comercializan.
En un caso es.
Tardó en otro caso, caso les grabó
ninguna de las dos soluciones
adecúa tampoco completamente
a los requisitos.
Son soluciones sagradas que además
no permite la implementación.
Por ejemplo, requiere una lista
de posibles variaciones
para los votos,
lo cual implica que tenemos que
conocer antes la asunción,
y estas dos oriental.
Búsqueda de similitudes al
proceso de información
desde una fuente externa, un fichero,
no la búsqueda de similitudes dentro
del propio conocimiento
y la implementación ado nos permite
ajustar los algoritmos
la lógica, las características.
Consideramos oportunas.
Bueno, para poder evaluar la
similitud de las entidades,
necesitamos bajar un poquito el
nivel y poder evaluar los atributos.
Para ello tenemos que crear
distintas métricas.
Para evaluar esos atributos
nos va a interesar
que todas las métricas
estén normalizadas,
es decir, en un intervalo de uno
para que sean comparables entre ellas,
la misma escala, siendo ninguna
similitud completa,
existen atributos de distintos tipos.
Tenemos atributos de tipo numérico
atributos de tipo,
fecha, cadenas de texto enlaces,
objetos y listas,
y tenemos también que no
todas las entidades
tienen la misma, todos los atributos,
tienen la misma capacidad
de identificación,
tenemos atributos que actúan
como identificadores
y, y, bueno, son estos,
serían los atributos en los cuales
esperamos encontrar
un único valor por cada
cada individuo,
por ejemplo, el dni se envían
que son graves,
pero no tenemos garantías,
por ejemplo nombre,
Daniel Ruiz Santamaría podría estar
repetidos en los distintos medios
y luego tenemos atributos sin
informativos que son atributos,
que no, que no actúan como,
y que por sí mismos
tienen un poder bajo
de discriminación,
pero que en su conjunto pueden
generar una firma que pueda ayudar
a salvaguardar.
Era para evaluar el poder
de discriminación.
Cierto atributo.
Lo que hacemos es crear una,
una métrica que vamos a llamar
el ratio de discriminación,
y lo vamos a definir como el número
de valores distintos
para una distinta, para una persona
tributo entre el total de instancias
de determinada clase.
Bueno, en este caso será un
indicador de la importancia del tributo.
Básicamente, los atributos
más relevantes
tenderán a tener un valor.
Uno para el ratio de discriminación
y los atributos menos relevantes
tenderán a tener un valor
bajo un valor 0.
Cuanto más instancias tengamos una
cierta clase, más precisos,
incluso en el caso de
que haya duplicados
y esos valores.
Esa ratio de discriminación y tienda
no ser exactamente 1,
incluso para los identificadores,
pues la importancia relativa será
mucho mayor a esos atributos.
Vale, aquí podremos ver un
ejemplar una siguiente,
la siguiente guía positiva, donde
tendríamos la primera columna,
el valor de las seguimiento.
En la segunda columna tendríamos de
discriminación que hemos calculado
en función de la fórmula más lista.
Anteriormente, en la tercera columna
tendríamos activos ponderados,
relativo.
De discriminación,
y en la última columna tendríamos
la similitud ponderada,
que no sería más que la implicación
de la similitud para ponderado.
En el caso, una similitud positiva,
pues podríamos ver, por ejemplo,
que la mayoría de la mayoría
de los balones, los valores
y aproximadamente suman,
si no me equivoco, un 8.085 por
100 en cuatro valores,
más o menos se concentra el máximo
poder de discriminación
y el resto de valores.
Tanto tanto el sexo como
el departamento
pues tienen un valor bastante
menor de importancia.
En el ejemplo podemos ver cómo el
valor de similitud es alto
para los valores, que tienen un
ratio de sí un ratio de discriminación
a la valoración calculada
que en ser positiva,
se entiende a ser bastante.
Sin embargo, en el segundo ejemplo
vemos la similitud es absoluta
para cuatro atributos
que tienen bastante importancia,
que están en rojo,
lo que hace que la similitud en
este caso sea bastante baja.
Vale?
Ahora vamos a hablar del tipo
de cadenas de texto,
que quizás es el tipo el
tipo más general.
Las variaciones comunes pueden
seguir las cadenas de texto,
pues son el cambio de palabras.
Por ejemplo, podemos encontrar
Daniel Ruiz Santamaría Santamaría,
Daniel, podemos encontrar también
frecuentemente abreviaturas.
Avenida Infante Don Luis
Infante Don Luis.
De Boadilla del Monte,
si me lleva a acercarnos al genial
personaje de Vives,
también hay que pensar qué opciones
tenemos que ver alguna vez bueno
lo que tenemos los errores
ortográficos
por ejemplo Elena se puede
expedir Singh
o a través de sus, a la hora
de introducir los datos,
es importante también para
simplificar la complejidad,
la normalización de las lágrimas.
Primero no vamos a discriminar
entre mayúsculas
y nos vamos a enfrentar a los 2.
De la misma forma, haciendo una
conversión a minúsculas
eliminaremos también los caracteres
de puntuación
es como si nos hacen 2, es decir,
separaremos en palabras y quitaremos
las estatuas que son palabras
que en Venecia parecen a menudo texto
o discriminatorio y pueden
alterar la valoración
por ejemplo los artículos nombres
posiciones opciones algunos verbos
adjetivos adverbio en este
caso hemos hemos añadido
este curso en unos 20
idiomas distintos.
Eliminar las mejoras también reduce
el tiempo de evaluación,
vale?
Para de similitud.
Nos hemos apoyado algoritmos
existentes
en este caso en 12 algoritmos por
un lado, tenemos el instante,
la estancia de Cartesian en vectores
de cadenas de texto,
distancia implica que la distancia
entre los vectores de cadenas
de texto, la instancia coste, no
es la distancia distancia,
el ángulo de cadenas de texto,
la distancia de Dáesh,
evalúa las similitudes nos muestras
desde el punto de vista
a los elementos que comparten
los caracteres,
la instancia ya cariño, analizado
que mide el grado
de similitud entre dos
conjuntos, es decir,
la casación.
Que evalúa el número de caracteres
iguales entre dos posiciones,
que son necesarios para
llegar de una obra.
Que quizás es el más;
el más conocido;
es la instancia reedición
de entre dos cadenas,
es decir, el número de el
número de ediciones
que necesitan realizar para apostar
por la cadena lo sé cuál es
la secuencia más larga en secuencias.
Seguimos guay basado en la longitud
de negra más cadenas
y si vanguardia Hernani,
ideado como un algoritmo para
realizar el alineamiento locales
Cohen, cierta adn se puede usar
también para alinear un alineamiento
óptimo entre dichas cadenas que
vale como a priori partíamos
de desconocimiento total
de estos alumnos
de estos algoritmos.
Lo que hemos hecho es crear
un conjunto de 20.000,
cadenas generadas con de tres asisto,
que cambien también aleatoriamente
y bueno.
Lo que hemos hecho es hacer una
serie de modificaciones.
No lo habéis hecho entonces con
datos de investigación de publicación,
no este nivel no.
Lo que buscábamos era únicamente
evaluar la norma,
ya no valen las similitudes de texto
en el fondo podrían ser.
Podrían ser investigadores,
podrían ser nombre?
Este artículo podría ser
cualquier cosa,
declaró marcas y es donde están las
características interesantes.
Por ejemplo, los nombres, cuando
entremos con nombre chinos
y empezamos a publicar con
chinos problema gordo
o con vietnamitas, si de todas formas
es un dúo que ha salido con el
proyecto sido y, bueno,
es algo que en algún momento haremos
en este momento no lo hemos hecho.
Si sobre todo esto nos ha servido
para justificar la algorítmica,
hemos aplicado a nivel general, en
la librería descubrimiento,
entonces y más sentidos
a último nivel
con los propios datos del proyecto,
hacer hacer rehacer un poquito
esta valoración.
Bueno, lo que hemos hecho distintas,
distintas modificaciones sobre
estos datos generados.
Primero la identidad,
es decir, ninguna modificación es lo
que vemos como iguales después
hemos desordenado.
Esas cadenas que hemos generado
entre tres seis
nos hemos desordenado.
Después hemos hecho cambios,
hemos hecho cambios,
si no me equivoco, hasta
un 20 por 100,
aleatoriamente o sean unos toques
si en otros toques
no hemos hecho cambios hasta no sé
si era el 30 por 100 de la cadena.
Hemos cambiado ciertos caracteres,
hemos truncado también, entre
también aleatoriamente
no todas las palabras sino las
palabras entre uno la mitad
y y como mucho, hasta la mitad
de cada, y luego hemos hecho
otra modificación, que son todas
las modificaciones.
Cada vez todas las hemos comentado.
Encara Saná la misma,
cadera y distintas.
Nos ha servido como medida
de control,
es decir, hemos metido cadenas
totalmente distintas,
generadas a la forma que son,
que no tiene ninguna relación
con la primera,
y nos sirve un poquito como cobayas
para saber si el algoritmo
peca de cada optimista o
se intenta encontrar
alguna similitud donde
no la hay, o no.
Bueno, con el fin de simplificar
un poquito las métricas,
por las hemos etiquetado mal.
Significaría menos del 25 por
100 de acierto suficiente,
menos del 0,4 por 100,
medio por debajo del seis por 100,
alto por debajo del ocho por 100,
excelente por debajo
del uno por 100 .
Lo primero que podemos observa
es que las dos primeros
casos son iguales, 2,
perfectamente cuando se desbordan
las cadenas perfectamente
y los problemas parecen empezar.
Cuando nacemos los cambios
de caracteres,
cuando tocamos o aplicamos todas
las las modificaciones,
inicialmente parece que
se comporta bien,
pero si nos fijamos en el valor
cuando son distintas,
ese valor no es del todo bueno.
Se ha de encontrar cierta similitud.
Cuando no hay entonces podemos pensar
que el algoritmo quien,
de ser un poquito,
demasiado optimista y bueno luego
tenemos el caso contrario
de algoritmos pesimistas, que
serían los cuatro o cinco
primeros donde funcionan
relativamente mal para los cambios
para los tocados, modificaciones.
Esto justifica que que
ningún algoritmo
parece funcionar bien para
todos los casos,
y la idea que la que
vamos a apoyarnos
es usar todos todos los algoritmos,
es decir, crear un algoritmo
de consenso
donde la unión de todos nos intenten
dar un valor que sea bastante
más fiable que el valor que nos
pueda dar individualmente.
El algoritmo de consenso que
hemos desarrollado.
Se basa en ordenar los resultados
de similitud de cada algoritmo
de la siguiente forma.
El resultado mayoritarios,
cierta similitud,
pues los ordenamos descendiendo,
enciende mayor amenaza
y si es en caso contrario
de menor a mayor,
vamos a establecer el peso
restante, como el beso,
que aún no hemos asignado en
la primera instalación.
El peso restante, obviamente
será 1, se establecen.
Vamos a establecer los
valores del texto
de aplicar el peso, aplicar
la integración para él,
para el valor y estableceremos
qué pasó
y será un tercio de lo que quede
para ocupar la primera instalación.
Pues era un tercio de 1,
es decir, un tercio del peso,
y el.
Como uno menos alfa, multiplicado
por peso
en la primera instalación, pues
tendremos que uno menos,
un tercio en el alfa que hemos
calculado por 1, será dos tercios,
que se siguiente peso.
Es el peso restante que
nos queda por aplicar
y, bueno, hombre, repetiremos desde
el punto tres hasta alcanzar
los dos últimos elementos de la
lista en los cuales vive dividir,
iremos al simplemente y queremos
pesos entre los y.
Bueno, para calcular la similitud,
lo único que haremos es
el sumatorio de.
Los pesos de la similitud condenada
que hemos que hemos calculado antes
en esta tabla, pues podemos ver un
poquito un poquito la evolución
de los pesos que vamos a aplicarlo.
Vemos que para el primer elemento
tercio exactamente
para el segundo elemento,
aplicamos un tercio del
restante; es decir,
entre los dos primeros elementos
tendríamos aproximadamente
un 50 por 105 por 100 del peso
que vamos a aplicar,
y esto iría disminuyendo.
Esto hace que es bueno que
tengamos en cuenta
todos los algoritmos, pero
nos apoyemos más
en aquellos que parecen confirmar la
premisa inicial en el caso de,
en el caso de valores numéricos.
Aquí tenemos dos casos.
Tenemos los valores numéricos,
tenemos que tener en cuenta
que muchos casos actúan
como identificadores
y, bueno, sí solo un identificador
no podemos estimar,
similitud o no sea la similitud
sería binaria,
sí mismo si es el mismo número
2, que debería ser 1,
si no es el mismo número, la
similitud tendría que ser 0,
esto lo haremos basándonos
en el ránking,
de maravilla de importancia.
Si nos lo que hacemos es aplicar
una exponencial inversa,
de tal forma que si el número
es exactamente igual,
el valor de similitudes en alguno,
si no es exactamente el mismo,
lo que entendemos es un valor que
oscilará en un rango de 0,
cinco a hacer, de tal
forma que existe
un salto cuantitativo
entre ser igual,
iba a generar rápidamente según nos
vayamos alejando del número
y luego tenemos valores.
La complicación que podemos
encontrar distintas,
distintas formas de no
escribir búlgaros,
podemos escribirlo conocer
o no podemos escribir.
Los eurofans podemos escribirlo
como en sí o no.
Ese en ella es tu.
Básicamente lo que tenemos es
un, es una clase de apoyo.
También intentamos es
bueno valencianas
y luego lo que haremos es aplicar
una operación en Guisando,
donde si son iguales, obtendremos
un uno básicamente.
Si son distintos.
Las fechas fechas tienen una,
una gran complejidad sobre
todo la detección,
sí o no, básicamente porque podemos
escribirlas de distintas chispas,
formas podemos alterar, el
orden podemos cambiar,
el lado podemos escribirlas
en cualquier idioma
pueden tener distintas
longitudes y bueno,
como en el caso de los, nos apoyamos
en una clase y variaciones
y consigue extraer de un texto
si es una fecha o no.
En cuanto a la evaluación
muy sencilla, una fecha
o es igual o no es la misma, no
nos interesa la cercanía.
Entonces,
una vez que determinamos piensa si
es la misma similitud distintas,
pero teniendo en cuenta que dos
fechas pueden ser iguales,
cuando una fecha es más precisa
que otras decir, por ejemplo,
en las dos fechas que aparecen
en el ejemplo,
podemos ver que una tiene
hora y hora,
sin embargo la fecha,
y debemos considerar que las fechas
son la misma en cuanto a las listas.
Las listas no es un tipo en sí mismo
si no que sino que al final
contiene elementos tiempo
determinado para evaluar las listas.
Aplicamos la siguiente.
Elegimos el primer elemento
de la lista
y buscamos el elemento o mayor
o con mayor similitud
dentro de la lista b y además
tenemos la similitud
encontrada y eliminamos los
elementos de la lista de la operación
hasta que no quede ningún
elemento a la vista
y calculamos la similitud
total para la lista
como la suma del sumatorio
de elementos de ahí
hasta el tamaño de la lista menor,
como las similitudes en la
escritura, elementos
y lo dividimos por el número de
elementos de la lista maño.
En cuanto a métricas de similitud
para objetos, podemos encontrar casos
aquí en la derecha donde podemos
encontrar objetos animados.
En este caso.
Lo que haremos es aplicar para
este objeto central objetos
de la cual hablaremos.
Hablaremos unos minutos en
cuanto a los enlaces
es un tipo bastante especial.
Aquí tenemos que tener en
cuenta el contexto.
Si el enlaces dentro del mismo modo
necesariamente estamos referencia al
mismo objeto en este caso solo
tenemos que ver dentro
del mismo modo hablo
dentro de la Universidad de Murcia.
En este caso solo hay que comprobar
si Lauri es la misma
la misma referencia clara
al mismo objeto
si la comparación estrés entre
distintos objetos
y el tema distinto en
la uvi podría ser,
va a ser distinta con su unidad.
Entonces lo que buscaremos es
una tripleta de equipos.
Hay más es la que estamos en
la que vamos a generar
en este caso este caso
entre distintos objetos de distintos
almacenados en distintos Sí.
Si existe esa etiqueta,
no se está indicando que ambos
objetos son lo mismo.
Entonces, entonces sí apuntan si
realmente una escala, otra.
La similitud seria
sería uno en caso de no existir
en este mismo equipo.
Si existe una tripleta
Klaus klaus más los más tripletes
que usamos para enlaces externos,
por ejemplo, una cierto investigador,
o estar apuntando a una cierta
distancia y base
y la segunda instancia puede estar
apuntando a la misma instancia base,
si sí estará en la misma
misma instancia,
pues tendríamos que podríamos
aplicar la propia transita viva.
Es decir, si es igual hacer
balance de ellos,
en caso contrario, que no
encontraremos esas tripletes,
necesitamos evaluar las entidades
que apuntan los enlaces, y bueno,
en ese caso lo que haríamos sería
recuperar esas entidades
y aplicarla a esto.
Bale en cuanto a la.
En cuanto a la evaluación
de entidades,
una vez que tenemos definida
la evaluación de todos,
de todos los tipos de atributos
o es relativamente simple
no podemos resumir en
esta esta fórmula.
Creemos que la derecha,
donde para todos los atributos,
aplicaremos el sumatorio de.
Ese, siendo es la similitud
de cada tributo
calculado según su tipo, según
ha mencionado anteriormente
y v, que será el ratio de
variabilidad de la importancia
y lo decidiremos todo
por la sumatorio.
La importancia de los votos,
y esto es la función que nos dará
la similitud de la entidad,
que como siempre se moverá
en el intervalo 0.
1.
Y bueno, entramos en el tema de,
entramos en el tema de
la complejidad,
y aquí el primer problema
que nos encontramos,
quizás uno de los mayores,
y es que para calcular calcular
la la búsqueda
vamos para hacer la búsqueda
de todas las entidades,
necesitaríamos hacerla
en todos los lados,
en todas las clases, en
todas las instancias
y en todas las instancias menos
unos, entonces menos en sí misma
de esa clase, es decir, para
todas las personas,
necesitaríamos por cada persona
evaluar con el resto de personas.
Esto nos lleva a una complejidad
de orden
elevado a la cuarta en principio,
como bien porque le declare,
es muy distinto.
De todos modos, dichas a
continuación se operó ahí ahí el número 2,
en número de clases no son grandes.
Entonces ese ponerle una cualquiera
no es Helene de las instancias,
sí más o menos.
Quizá no esté bien expresado,
no lo digo.
La siguiente punto ser en
el siguiente punto.
Lo que vamos a la lugar nunca
nos vamos a evaluar.
Todas las clases para las estancias
tampoco son de la misma magnitud
que el número de instancias
potencialmente.
Entonces, bueno, como siempre,
vamos a evaluar
para un modo determinado y para
una clase determinada.
Los dos primeros términos se reducen
a uno nos quedamos con la complejidad
del número de instancias para
el resto instancias,
es decir, tendremos una complejidad
del tipo del tipo en cuadrados
y y bueno, para que nos
hagamos una idea,
pues si tuviésemos solamente
1.000 entidades
no son muchas, que hablaríamos de
una de un 1.000.000 de comprobaciones,
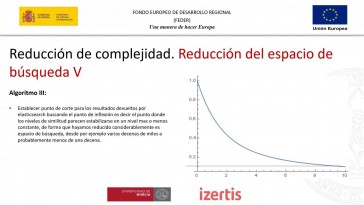
no empiezas a ser un problema,
aquí tenía,
tenía un vídeo que no te lo voy
a poner, tiene expresa,
pero básicamente habla del
crecimiento exponencial
y, y y bueno,
lo que lo que vamos a intentar
es que los dos actores
sean número distancias y
el número de estancias
con las que tenemos que comparar
lo que vamos a hacer.
Lo que vamos a hablar primero
es la reducción del espacio
de búsqueda y bueno,
lo que vamos a hacer es una búsqueda
previa en las pizza.
Aprovechando que tenemos, tenemos
los atributos atemorizados,
de importancia.
Vamos a vamos a realizar
dicha búsqueda
por los atributos más relevantes,
con lo cual vamos vamos
a limitar el ascenso de la
experiencia militar.
Pues estamos trabajando con clases
de unas 20.000 entidades más
o menos, y con este paso estamos
reduciendo la la búsqueda,
como mucho 50 la mayoría de
los casos por debajo,
lo cual hace que el segundo término
de la complejidad sea bastante,
y luego la segunda estrategia
que seguimos comparar,
únicamente los deltas, es decir,
si una, si una entidad no ha
cambiado y ya lo hemos evaluado,
no tendríamos porque volverá
a hacerlo en ese caso,
pues está claro que la
primera interacción
que hagamos la complejidad
será total.
Serán números distancias que haya,
pero a partir de ese momento
solamente nos van a importar.
Vamos a evaluar las entidades
que hayan cambiado
o lo cual, bueno, conseguimos
reducir estos dos términos,
que aunque sigue siendo otra,
una multiplicación,
pues bueno estoy otra es de otra
magnitud que a la que teníamos,
y no sé muy bien qué hacer Oscar
si si no, seguiré como.
Yo creo que si quieres lo que
está haciendo mucha gente
es que para saber cómo va los
vídeos los va acortando.
Haga bien que a lo mejor
eso te sirve más a tu.
Ayer iban cortando los vídeos
cada equis tiempo,
no cada una hora o la media hora;
cuando había un bloque
como has terminado este bloque, a lo
mejor eso lo puede exportar Bale
vuelve a comenzar otro vídeo que así
es mucho más fácil para los bienes
para obtenerlos.
Así que yo creo que te
puede venir bien.
Propietarios
Proyecto Hércules
Comentarios
Nuevo comentario
Serie: Formacion ASIO viernes 12 de febrero IZERTIS (+información)
Descripción
Formacion ASIO viernes 12 de febrero IZERTIS