Vale, pues vamos a continuar con
la parte de la segunda sesión.
La semana pasada habíamos visto
un poco la estructura
de este proyecto.
Os enseñé por encima la arquitectura
que tendría,
y luego estuvimos instalando ventaja
para que tuviera todo
el entorno listo
y demás.
Si recordáis, vimos un
poquito por encima,
como funciona Tajo, por dentro,
como la estructura que tiene,
que tienen los dios,
las transformaciones también
os había enseñado
cómo conectarlos a un repositorio
a un proyecto existente
y luego también estuvimos analizando
la salida del formato
de los de los, son los ojos con
las distintas entidades,
los los objetos, planos, los objetos
relacionados y un poquito también,
cómo se mostraban las colas, de
Kafka, etc. Entonces buenas
la sesión de hoy.
Lo que lo que vamos a ver
es explicarnos un poco
cuál es el objetivo real.
Es decir, tiene como finalidad hacer
un mapeo de la odontología,
a más bien al contrario de los
datos de cada universidad
a la odontología.
La antología es una especificación
que tiene que ser estandarizada tiene
que ser transparente a cualquier, a
cualquier tipo de corporación,
mientras que los datos
de cada universidad
será algo específico.
De cada una de ellas,
si bien es cierto
que existen muchas entidades,
muchos datos que pueden ser
comunes o transversales
a cualquier universidad, pero
siempre habrá datos específicos,
incluso aquellos datos
en común tendrán
ciertas particularidades propias
de cada universidad
o, simplemente el formato.
Es decir, un formato o un
campo de tipo fecha
puede estar en formatos diferentes,
dos universidades distintas,
o incluso la misma universidad,
dos orígenes de datos
independientes, pues les encargaría
de unificar estos estos datos,
formatos y convertirlos
a un formato común.
Os voy a compartir la
pantalla avisando.
Por favor, si lo veis.
No sé si lo estáis viendo,
ya no ahora mismo
no.
Vamos a ver.
Volveremos a intentarlo.
Estoy compartiendo que ahora
sí vale perfectos.
No sé si tenéis aventajó abierto
estos ordenadores
que lo habíamos instalado
la semana pasada.
Vamos.
También quería saber si tenéis
operativos todos los contenedores.
Dedo que habían configurado
la primera sesión.
No sé si lo tenéis listos,
era simplemente bueno,
porque os bajará
y el proyecto de allí y lo
abriera para un problema
y poquito cómo se abre
como se ejecuta.
Lo que pasa es que si
estos contenedores
no lo estén activos, no
os va a funcionar,
es confirmar activos de
otro día, que era 5.
Si tendría que ser la base de datos,
el serían los que necesitaríamos
para lte.
El de la base de datos, como
se llama María María Bale.
Si los servicios lo tengo ventaja,
no recuerdo más arrancado
para la ventaja.
Lo que tenéis que hacer es
entrar en la carpeta
que os habéis descargado vale que
la tenéis en vuestro ordenador
un sitio de ordenador, y
dentro de esa carpeta
tenéis un listado muy grande de
ficheros y uno de ellos se llama.
Es un punto bat.
Lo pongo en el chat.
En el chat, en nombre del fichero.
Cuando lo tengáis tenéis que
entrar en este reto,
los pongo en el chat.
También.
Eso vale cuando tengáis el
repositorio abierto comentó mal.
Firme si tenéis problemas
para abrir ventaja.
Está arrancando balas.
Si quiere el proyecto,
mientras tanto,
tarda un poquito en abril.
Ventaja.
Tenéis que entrar en este repositorio
Bale dentro del proyecto Hércules,
el repositorio y tenéis
la web en el chat
y dentro tenéis una carpeta que
se llama proyecto bale.
Esta carpeta contiene.
Debería de contener la última
versión del proyecto,
que la veo incompleta por lo que veo,
o sea, que me temo que nos la vais
a poder descargar ahora mismo,
porque vamos a tener que cargar
la última versión,
la estructura del proyecto para
que veáis bueno, pues,
se compone de todas estas carpetas.
La había enseñado en
la primera sesión,
pues tendría que.
Y luego además dentro de la raíz
tenéis una carpeta que se llama
recursos y aquí dentro, bueno,
tenéis un vaca de la base de datos
que vais a necesitar para ejecutar
esta vaca bajo de tele
la descarga y, bueno, con un editor
de bases de datos cualquiera
que tengáis que maneje un valle
se cuele simplemente la carga
y sistema para tener la estructura
de la de la base de datos a mano,
y así bueno podéis ir viendo sobre
la marcha según se ejecuten
los datos, que se van,
que se van volcando.
Siendo ahora que no tengáis
disponible la versión del proyecto
en cuanto termina la sesión,
la dejó su vida,
la última y así ya la tenéis lista.
Para que hagáis vuestra pruebas
mal entonces, bueno,
continuó con la sesión y cualquier
cosa me vais.
Me vais diciendo?
Vale?
Entonces voy a abrir el proyecto.
Si os acordáis en la esquina
superior, derecha,
teníamos un botón que
se llama con el.
Entonces.
Aquí tendréis disponibles.
Todos los repositorios que
estén conectados.
Si no lo tuviera, simplemente tienes
que darle explicar opositor.
Ayer en la ventana que sabré
tendríamos que añadir.
Un nuevo repositorio escogería
otros repositorios
escoger es un repositorio basado
en ficheros, valen,
los seleccionadores, desea
el botón de comenzar.
Aquí simplemente le dais su
nombre al repositorio
y se lesiona.
Es la ruta donde se encuentra
la ruta del proyecto
sería la carpeta que contiene
todos estas carpetas.
Si lo descargado se llamará
a la carpeta
-proyecto, vale,
simplemente la marca es la raíz de
esa aceptar su nombre Hércules,
por ejemplo, le dais a finalizar y
hasta ya no lo tendría sincronizado
con ventaja.
Entonces, simplemente haciendo clic,
en el voto no conectar ahora
están conectados al proyecto.
Hecho esto, simplemente ahora,
al darle al botón de abril
cualquier fichero directamente
Pentágono sobre el directorio raíz,
dónde está nuestro proyecto, vale?
Entonces, a partir de aquí podréis
cargar todos los ficheros.
Voy a conectar a mi repositorio.
A ver.
Un show en directo.
El proyecto.
Conectamos.
Vaya, no sé qué está pasando.
Dadme un minuto y lo comprueba.
Vale, de acuerdo?
Es que la carpeta había sufrido un
cambio de nombre a disculpado.
Esto es lo que pasa al trabajar
todos los días con ello.
Bale.
Ahora, ahora sí entonces,
al darle al botón,
abrir acciones directamente al
directorio raíz del proyecto,
y aquí tenéis todas las carpetas,
Bale, a la izquierda,
podéis ir marcando la carpeta
que queréis acceder,
y a la derecha todos los ficheros
que contienen.
Las carpetas más importantes
sería la cuatro
la cinco yo si transformaciones
aquí está digamos
el grueso del proyecto está todos
los distintos módulos
del proyecto con los que se trabaja
dentro del resto de carpetas,
contienen otras transformaciones de
carácter general o transversal,
al proyecto que se encarga de
validar las conexiones
a los orígenes de datos, otro
tipo de transformaciones
que se encargan de verificar que
las que el proceso, todo,
el proceso,
ha comenzado y ha finalizado
de forma satisfactoria,
existe otra carpeta que se
encarga de almacenar
todos los los los otra que almacena
distintos etc pero lo que nos comentó
todas las transformaciones,
todo el trabajo,
la parte principal del trabajo, se
encuentra en estas dos carpetas,
vale?
Yo y transformaciones, vale
para abrir el proyecto.
La primera vez tendréis que
entrar en la carpeta raíz
y seleccionar un guión que se llama,
que está aquí separado.
Bale lo abrimos, este sería
el la parte inicial
del proyecto Bale.
Ahora no os voy a os voy
a comentar un poquito
como está estructurado el proyecto,
porque, como decía, se basa en
transformar los orígenes de datos
en la odontología.
Entonces, primeramente
hay que tener claro
cómo está, cómo se encuentra
diseñada y estructurada,
la odontología.
Esto lo habéis visto en otra sesión.
De todas formas, para trabajar
con él es necesario
simplificar el esquema de la
antología al máximo posible,
y para ello, pues hemos desarrollado
este fichero excel,
que nos señora por pantalla,
que contiene de una forma
lo más sencilla posible.
Es que matizar la oncología, vale.
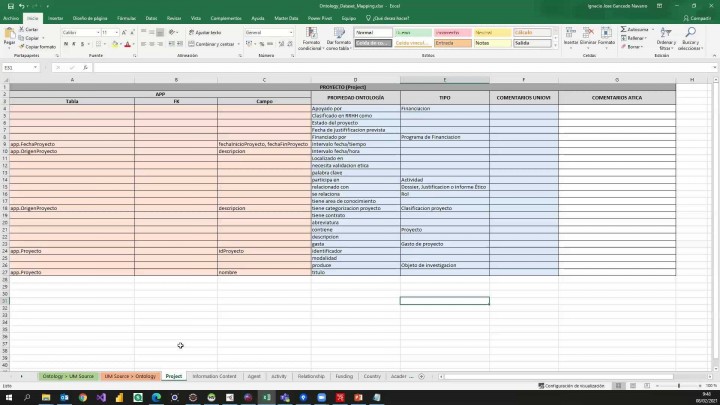
Aquí lo que veis es una una tabla,
una tabla que contiene
todas las entidades
de la de la versión actual
de la odontología.
Vale, como veis, tiene
distintas columnas.
Cada columna sería un
nivel jerárquico,
dentro de cada una de las entidades,
si os, por ejemplo, la columna,
la que pone el uno véis un
montón de entidades
de la antología no actividad a gente
concepto entidad de contenido
de información etc este serían las
entidades que se encuentran
al nivel más alto.
Dentro de la antología de las cuales
penden el resto de entidades,
luego os vais a ir encontrando
a niveles sucesivos
bale con los distintos
niveles jerárquicos.
Vale.
Como veis, existe hasta
un nivel cinco
de jerarquía en este caso de entidad
de continuidad de la información,
lo podéis ver claramente la
entidad y el contenido
de la información continua, su vez
tres entidades que serían colección,
publicación científica
y que a su vez contienen una
serie de de entidades,
a ellas dentro de colección,
veis las entidades dossier
y periódica periódica,
a su vez tienen las entidades,
por ejemplo, también veáis la
entidad artículo que se encuentra
dentro de publicación científica
y que, a su vez comprende distintos
tipos de artículo?
.
212
00:16:33,525 --> 00:16:37,500
Bueno pues lo mismo con documentos
de colección facturas secciones
de documentos tesis etc vale la
tabla es bastante densa de contenido,
es decir, muchas entidades,
pero Bueno,
aquí podéis encontrar de una
forma relativamente fácil,
rápida y cómoda una ubicación
de los orígenes de datos
a la antología.
Vale?
Con esta tabla presente.
Lo que hemos hecho
es añadir una columna a la derecha
donde lo que hacemos
es encontrar o hacer un mapeo
entre la odontología
y los orígenes de datos de la
Universidad de Murcia.
La idea es ir analizando cada uno
de los orígenes de datos
de la Universidad.
Intentar encontrar una entidad
de la oncología,
que digamos que etiqueten de
alguna forma esos datos
no algunas son inmediatas,
como, por ejemplo la entidad persona
se encuentra en una tabla
dentro de la universidad,
llamada persona,
y tiene una relación directa
con la entidad personal
de la odontología, por ejemplo,
la entidad artículo.
Lo mismo, bale en este caso.
Se trata de un origen de datos que
contiene todos los artículos,
con lo cual sería complicado
categorizar los artículos por tipo
de artículos académicos de editorial
de prensa de conferencias etc
entonces en este caso lo que se haría
es cómo tenemos una entidad llamada
simplemente artículo Bale,
que se encuentra a un nivel más alto
que la de los tipos de artículo.
Cogemos y relacionamos nuestra,
nuestro origen de datos,
artículo con la entidad artículo
de la antología.
Vale?
Entonces lo que haríamos sería
todos los niveles que se encuentran
de artículo hacia abajo,
en la jerarquía.
Podemos prescindir de ellos.
La idea de esto es que si
tenéis que se tiene
que adaptar este proyecto
a otra universidad,
si esa esa segunda Universidad sí
que contuviera un origen de datos
donde distinguir antes los
tipos de artículos.
Si esos tipos de artículos
se puede categorizar
dentro de algunas de las clases
de la antología,
sería que, donde donde se realizaría
el mapeo corresponde.
Bueno, veis algunas otras entidades
que también son inmediatas,
como libro patente, también
tenemos proyectos,
todas estas serían inmediatas, Bale.
Luego existen algunas que no tienen
una relación tan directa,
requieren un poco de análisis previo,
no entender un poquito la naturaleza
del dato y ver si primeramente,
si existe una correspondencia
con la tecnología bale.
Nos puede enseñar algún ejemplo.
Por ejemplo, la parte de
financiación que se encuentra aquí vale.
Aquí tenéis la clase financiación y
distintos tipos de financiaciones
vale?
En el segundo nivel.
Luego aquí tenéis otra clase, que es
la fuente de la financiación.
Bien, pues los datos de Murcia
tenemos distintos orígenes de datos,
entre los cuales nos encontramos
tipo de financiación.
Nos encontramos otro origen de datos,
que ayudas nos encontramos
otros datos que tipo
fuente de financiación.
Entonces, bueno,
primero sería necesario entender
qué tipos de financiaciones
se manejan a ver si existe
alguna relación directa
con algunas de las que contemplan
la antología.
En caso contrario,
siempre vamos a tener
la clase genérica,
que las aglutina todas vale?
Por esa razón yo lo que he puesto
es que la tabla tipo
financiación se encuentra
relacionada con cualquiera de las financiaciones
que contemplan la que contempla
la odontología.
Por qué?
Porque la tabla tipo de financiación
contienen diversos tipos
de financiación,
algunos de los cuales se pueden
corresponder con estos cuatro
que me indica la odontología.
Pero puede ser que alguno se
escape entonces bueno?
Financiación a secas
contemplaría cualquier tipo de
financiación existente.
Vale.
Sin embargo, la tabla ayudas
se correspondería
con lo que es el tipo de
financiación que encajarían
o que tendría una relación
con las las ayudas.
Luego, en el caso, por ejemplo, de
tipo de fuentes de financiación,
qué bueno, básicamente te dice
quién, qué entidad financia.
Pues sí que tendría una relación
directa con la clase fácil shows
que veáis.
Esto serviría para, como comentaba,
para hacer un mapeo rápido
entre la odontología
y los orígenes de datos
de cada universidad.
Vale, sin embargo,
lo cada cada una de las entidades
tienen propiedades,
es decir, os voy a enseñar el
esquema de la oncología.
Vale,
este sería el, este sería el esquema
detallado de la antología.
Si aquí tendréis todas las
todas las entidades
instaladas en forma de árbol
y las entidades,
básicamente este esquema se
corresponde un poquito
con el exterior.
Se acabó de enseñar lo que ocurre,
que aquí tenemos mucha
más información.
Por ejemplo, si nos centramos
en la entidad proyecto.
Y hacemos clic sobre el nombre aquí
dentro de un montón de propiedades.
Estas son las propiedades
de la entidad proyecto
aquí véis, por ejemplo, que
una de las propiedades
es la entidad que financia
los proyectos.
Hay otra propiedad que es
el estado del proyecto,
fecha de justificación.
Tenemos.
La propiedad localizado se
relaciona con algún rol,
si tiene abreviatura descripción,
título etc. Estas ideas,
las propiedades que la Odontología
dice que tiene que tener la entidad
proyecto, pues bien, en el externo
lo que hemos añadido es una pestaña
por cada una de las distintas
entidades donde lo que tendríamos
la columna azul serían
todas las propiedades que determina
la odontología con este listado
de propiedades lo que podemos hacer
es encontrar exactamente el campo
dentro de cada una de las tablas
de los orígenes de datos
que se corresponden con cada
una de las propiedades.
Entonces, dicho esto, aquí hay
un pequeño trabajo extra
que consiste en una vez encontrado
el mapeo entre la odontología
y el origen de datos, es decir,
una vez que sabemos que
la Odontología
contempla una entidad concreta y
nuestros datos de la Universidad,
existe esa entidad,
tenemos que encontrar todas
sus propiedades,
y esas propiedades pueden ser que
se encuentren en un único,
en una única fuente, en un
único repositorio tabla,
base de datos o puede ser que
se encuentren varios.
En este caso, por ejemplo, para
la Universidad de Murcia
habéis que hay distintas tablas
involucradas en los datos
de los proyectos.
Tenéis la tabla proyecto, de
la cual se podría sacar
la propiedad identificador
y la propiedad,
título que se correspondería con los
campos nombre del proyecto.
Sin embargo,
existen otras propiedades que
están en otras tablas,
como, por ejemplo, el campo
de inscripción
se encuentra en la tabla origen,
proyecto, vale?
Este campo se correspondería con
la propiedad de la oncología,
tiene categorización del
proyecto que sería
del tipo clasificación, proyecto.
De la misma manera, las
fechas de origen
y fin del proyecto, que es otro
dato de la antología,
se encontrarían en la tabla, fecha,
proyecto de dónde las podríamos sacar
a través de los campos fecha inicia
el proyecto fecha fin proyecto
vale entonces en lo que hacemos
es este proceso,
es decir,
acceder a los distintos
orígenes de datos,
hacer las uniones correspondientes,
extraer y acceder a los campos
que necesitamos,
que serían estos que están
aquí y al final,
una vez que lo tenemos todo,
digamos, en el mismo saco,
pues, componer el formato
de salida necesario.
Muchos de estos campos se
quedarán en blanco
porque son campos que no existen, no
se encuentran nuestros datos,
pero hay que tenerlos
siempre presentes
porque puede ser que nos datos
de la Universidad
si existen.
Entonces,
lo que habría que hacer sería
adaptar de manera que esos orígenes de datos
se conecten y se transformen con
todas estas propiedades
que están aquí vale.
La idea no sería crear un nuevo,
no sería modificar a realizar
grandes cambios,
sino cambios
que sean lo más pequeños posibles,
puesto que se encontraría en
la medida de lo posible,
preparado para disponer en un futuro
de esos datos que por ahora
no existen, vale,
con lo cual, simplemente habría que
conectarlos y incorporarlos
al resto del flujo de datos.
Vale?
No sé si tenéis alguna pregunta
hasta ahora, porque, bueno,
puede ser que esta parte pueda
ser el principio,
un poquito, una duda, el ex del Este,
que no sé si esta subida
al repositorio
no sé si es así y, entonces, lo
que no tiene equivalencia
de con alguna clase,
porque en la Universidad de Murcia
no, no existe esa esa relación,
no exactamente darnos cuenta
de que nuestro,
por decirlo de alguna manera,
nuestro conejillo de indias
es la Universidad de Murcia.
Entonces, nosotros lo que tenemos
es que encontrar una relación
entre unos datos reales,
que son los datos de la Universidad
de Murcia,
y una especificación estándar
que tiene que ser transparente
o transversal,
a cualquier tipo de universidad,
entonces la oncología es una, una,
un diccionario de datos,
una especificación muy amplia que
contempla muchísima información,
con lo cual la Universidad
de Murcia no va a estar.
Toda esa información es
prácticamente imposible,
estará gran parte de esa información
e incluso puede estar mucha otra
información que no encaja
dentro de la odontología.
Entonces, nosotros lo que tenemos
es que hacer ese proceso de
discriminación, de datos,
analizar nuestros orígenes de datos
y ver cual es de esos datos,
si tienen una correspondencia
una vez hecha esa tarea,
que sería lo que haría y se está
en esta pestaña principal,
vale.
Hay que entrar al detalle,
hay que meterse dentro de las tripas
de cada una de esas entidades
y intentar hacer el mismo proceso,
esa discriminación de datos,
pero con las propiedades
de cada entidad,
y eso sería lo que haría.
Con estas tablas de aquí vale,
vale, pero entonces,
si llegase otra universidad,
lo que les gusta,
si de igual manera la antología y
nosotros tuviésemos que hacer
otra cosa distinta, los procesos,
o yo o lo están los datos
son los mismos.
Me refiero al mismo proceso
para la otra universidad.
Se comparten procesos.
Son dos procesos distintos.
Me explicado, si te explicas, te
explicas muy buena pregunta.
Por cierto, el proceso
va a ser el mismo,
porque la tele se construye
basándose en la odontología,
es decir, tiene que haber un proceso
por todas aquellas entidades
de la odontología.
Vale?
Entonces ese proceso de momento va
a utilizar los datos en Murcia,
pero si hubiera que conectarlo
a otra universidad,
lo que habría que modificar
para que las conexiones
a los orígenes de datos sea
a esa otra universidad
y además hacer un análisis previo
que se podría hacer excel
para facilitar la tarea donde habría
que encontrar datos que en la versión
de la Universidad de Murcia no
estén y al mismo tiempo
otros datos que en la versión de la
versión de la Universidad de Murcia
sí estén, pero en esta
nueva universidad
no se encuentren de acuerdo.
Entonces es lo que habría que hacer,
es adaptar para hacer este cambio,
pero le duele sí que tendrá un
flujo encargado de gestionar
la entidad proyecto y que tiene
como objetivo encontrar
todas estas propiedades.
De aquí lo cual puede ser que que
cubra para una universidad puede
ser que cubra parcialmente
para otra universidad.
A lo mejor podría darse el caso
de que una universidad
no tuviera ningún dato.
Sería extraño,
porque proyectos deberían de estar
en cualquier universidad,
pero podría podría darse
la circunstancia.
La casualidad de que una entidad
que tuviera muchos datos
para una universidad no tuviera
datos para otra,
donde se en ese caso ese flujo se
quedaría vacío en el momento
de ejecutar el proyecto
para esa universidad.
No sé si.
Mi duda es conectarse,
orígenes distintos
de distintas universidades, y el
flujo no supone ser el mismo,
pero no sé si podría darse el caso
de que en una universidad
un proyecto o un tipo de
proyecto, un artículo
que sea una cosa, se correspondan
con una cosa de antología,
y en otra universidad se
corresponda con otro.
Sea contradictorio, sí podría
darse ese caso?
Bueno, eso sería, sería un
análisis muy exhaustivo
y sería ya meterse a entender el
tipo de datos que se están manejando.
Comentaba un poquito, no, en un
principio hay entidades que son
bastante triviales, bastante obvias,
pero puede ser que algunas
no lo sean,
puede ser incluso que tengan
nombres parecidos,
pero no manejan los datos esperados.
Lo que hay que hacer ahí es
analizar previamente,
si ese dato tiene sentido
incorporarlo,
porque a lo mejor no lo contemplaría
la antología,
no sé si me explicó.
Se sería un poco, sería un poco
esos los pasos que habría
que llevar a cabo,
pero la idea es que el flujo
se encuentre preparado
y que y que espere por todas
estas propiedades
siempre va a haber que hacer
modificaciones y ajustes.
Eso es inevitable, porque,
bueno, los datos,
lógicamente cambian bastante
y y bueno,
estamos intentando hacerlo
lo más dinámico posible
que sea capaz de adaptarse en
la medida de lo posible,
pero siempre va a haber que hacer
algo de trabajo manual.
Os voy a enseñar aprovechando que
se acabó de enseñar esta parte
de la entidad proyecto, lo
que voy a hacer ahora
es abrir el flujo la entidad
proyecto y bueno,
le echamos un vistazo y yo.
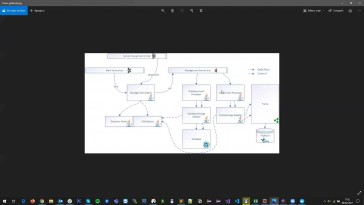
Vale, este es el exceso de tele
que se encarga de crear los objetos
planos del proyecto
y, como veis, tiene cuatro
orígenes de datos.
Uno sería proyecto;
otro sería fecha, proyecto,
origen, proyecto y bueno,
estoy aquí que sería tipo origen.
Proyecto vale?
Son los orígenes de datos necesarios
para extraer la mayor parte de las
propiedades que la antología
dice que debe tener la entidad
proyecto a partir de aquí cada 1.
Estos flujos empiezan a realizar
transformaciones sobre los datos.
Este primer nodo que veis
aquí lo que hace
es una selección de campos.
Vale aquí en esta primera
pestaña que tenéis aquí
que sea más ante una lista
de todos los campos que contienen
nuestro origen de datos
y al que a la derecha
se hace un crimen
se les cambia el nombre en
caso de que se requiera,
hacer bien si nosotros adapta
y sextete leal
los datos de otra universidad.
Obviamente estos campos de aquí
no tendrán ningún sentido,
pero la tele tiene la capacidad
de mediante este botón,
que dicen que tu selecta recoja
automáticamente los nuevos campos
de nuestros datos.
Entonces, pasos para adaptar
proyectos a otra universidad.
Primeramente entrar en cada
uno de estos nodos
de los orígenes de Datos,
aquí dentro se hará un selecto al
origen de datos correspondientes,
vale este selecto, ahora mismo se
encuentra en proceso de desarrollo
cuando el proyecto está en producción
tendrá una forma muchísimo
más simplificada,
porque todos se pasarán
por parámetros
para que los nombres de las tablas
y los orígenes de datos
simplemente se almacenan
en una variable.
No haya que entrar directamente
en cada uno de los 2.
Pero, bueno, la idea general
sería esta,
hacer un selecto, se podría
ser una selección
de todos los datos, y luego,
en este segundo paso
lo que haríamos será recoger
todos esos campos
vale vale entonces bueno pues
aquí lo que podemos hacer
es renombrar, los podemos eliminar
campos que no queramos, por ejemplo,
el campo presión, sino lo queremos,
lo marcamos y suprimir
y directamente queda excluido
del flujo vale hay
otra pestaña que sea que sirve bueno
pues para transformar para hacer
cambios de tipo de dato.
No?
Por ejemplo, imaginaros
que uno de los campos
es una fecha y viene como un bueno,
pues, podemos cambiar el tipo y
hacer que se convierta a un tipo de Bale
y luego, bueno, pues, podemos
elegirle un formato
que queramos, año mes,
día a día, mes año, podemos hacer
un Time Mestalla, etc.
Se puede transformar de
cualquier manera.
La idea
es que los cambios que se tengan que
hacer para cada universidad
sean, pues, a este nivel, no
a nivel de extracción,
vale más o menos por aquí luego
ya el flujo genérico.
Bueno, pues lo que sé de
lo que se ha encargado
es principalmente de que todos
los todas las propiedades,
todas las variables tengan los
nombres que dice la antología
vale y que el formato de
salida va a ser común,
independientemente de la universidad
que estamos manejando.
Entonces, un poco volviendo
a tu pregunta.
Si habrá que modificar
todos esos flujos
habiendo hecho todo el análisis
previo, pero bueno,
los cambios que hay que
hacer serían mínimos,
no sería acceder al origen de
datos y extraer los campos
que necesitemos.
Claro, otro cambio que
puede ser necesario
es incorporar otro flujo
de datos diferente
o o eliminar alguno que
no, no tenga sentido.
En este caso tenemos 4, pero igual
de los existen proyectos
se hace para la Unidad Complutense
de Madrid.
Pues toda la información
relativa a proyectos
se encuentra en el mismo
origen de datos.
Entonces, bueno, fácilmente
lo que se puede hacer
es desconectar cada una de las ramas
que no interesen, vale,
y simplemente se hace una unión
directa al resto del flujo,
que ya sería el camino común.
Acuerdo.
No sé si ahora me queda claro,
porque cada uno de estos flujos
es para una universidad
en concreto el flujo.
La idea es que el flujo sea estándar
a la odontología,
pero hay una parte de ese flujo
que va a ser exclusiva
de cada universidad,
si entonces esa es la que vas a
tener que adaptar un poquito, pero bueno,
como ves, es una parte muy
pequeña del flujo,
y es más fácil de gestionar porque
sería simplemente acceder
al origen,
extraer los datos que queramos como
mucho cambiar los nombres
no entiendo gracias nada pero no
pudo repetir la configuración bueno
digo si estamos en duda
todavía de presentar,
porque no va a durar.
Lo había hecho al principio.
A qué te refieres?
A la primera sesión?
No lo que ha hecho hace uno minuto
para conectar el repositorio
se vale.
Cuando abres ventaja en la
esquina superior derecha
tiene un botón que dice.
Vale, vale.
Si le vas encontrarás una opción
que dice repositorio
a ir.
Bueno, si lo tienes en español.
No sé si dice gestión
de repositorios.
Otros repositorios era ese.
Repositorio ayer le darías a añadir.
Bale, en la ventaja que se te
abre, te da la opción,
otros repositorios.
Bale la siguiente pantalla te dice
si quieres un repositorio de base
de datos o un repositorio de
ficheros cogería ser repositorio de ficheros,
le das a que le das un nombre
al repositorio libre
y simplemente buscar la ruta donde
tengas el raíz del proyecto
vale cuando lo descarga esa
ruta se llamará proyecto
bale será esta carpeta.
De aquí.
Qué es la que va a contener
todas las?
Todas las carpetas y todos
los ficheros necesarios
para ejecutar valer estos?
Os lo voy a dejar subido en
cuanto termine la sesión.
Vale para que lo tengáis accesible.
Vale, ya lo tengo perfecta.
Bale, pues de la misma manera
que hemos trabajado con
la entidad proyecto,
pues tendremos en este extremo
el resto de entidades,
vale?
Si no somos a la siguiente
pestaña la que dice,
el contenido de la información,
si lo recordáis de la de la primera
de la primera pestaña,
donde veíamos esta entidad contenido
de la información,
ves que está esta clase de esta
entidad es bastante grande
tiene muchísimas su entidad
vale entonces bueno
no es tan sencilla como
la de proyecto,
porque, bueno, tenemos
la entidad patente
la entidad artículo tenemos
la entidad libro
la entidad sección de un libro
la entidad tesis doctoral crisis
de máster facturas,
y ya vale.
Pero bueno, hay muchas más.
Al lado de cada nombre de
la entidad se puesto
la, la estructura jerárquica vale?
Para que resulte más fácil
de ubicar patente,
pertenece a la clase,
identidad de contenido
de la información,
que a su vez pertenece a
publicación científica
y después patente.
Bueno, lo he dicho al revés,
perdón, patente,
pertenece a publicación científica
y que a su vez pertenece a
la entidad de contenido
de la información.
Vale?
En este caso todas son publicación
científica,
exceptuando sección del libro.
Queréis que tiene una entidad
que se llama capítulo,
que a su vez pertenece a sección de
un libro que a su vez pertenece
a parte de un documento que a su vez
pertenece a publicación científica
y a su vez el contenido
de la información.
Vale?
Es bueno si tenéis en algún
momento dado duda.
Bueno, pues os quedáis con esta
con esta línea de aquí
y os vais a la primera pestaña.
Vale.
Entidades de continuidad
de la información,
publicación científica,
documentar sección del libro,
capítulo del libro Bale,
y que tenemos dentro del
capítulo del libro
El origen de Datos llamado
capítulo libro
para la Universidad de Murcia.
Entonces, teniendo esta
estructura clara,
pues quedaría repetir la tarea
que veíamos antes
no propiedades de la antología,
estarían.
Uvi el origen de datos
correspondiente
y una vez que sepamos
el origen de datos,
pues buscamos el campo o la columna
que tenga ese dato en cuestión.
Pero esta tarea,
alguien que se encarga de gestionar
las bases de datos
de la universidad, pues lo pueden
hacer muy rápidamente
si la persona encargada no
tiene una visión general
o conocimiento amplio
de los estudiantes
más necesitar, probablemente, ayuda
de esta persona, que será
quien le pueda dar detalles exacto
del tipo de dato que se maneja,
vale, y, bueno, pues un poco
con el resto de entidades
lo mismo no sería lo mismo agente
actividad relación financiación etc
vale ahora bueno nos encontramos en
proceso de desarrollo del proyecto
Entonces, bueno, esta plantilla está
hecha parcialmente, vale,
con el tiempo, irá creciendo y bueno,
como sigue el patrón de la oncología.
Pues esto se podrá reutilizar
para cualquier universidad,
debería no debería ser más grande.
Esta tabla para un análisis
diferente,
simplemente puede tener más o menos
datos en función de sus orígenes.
Bale.
Entonces, volviendo a Tajo, el
proyecto se encuentra organizado,
con el me vale y dentro del top 20
tenéis un yo que se llama carga,
lo que se encarga de cargar
toda la información
con las propiedades planas
de los proyectos.
Entonces, dentro de este,
lo tenéis distintos,
cada uno con los nombres de las
entidades que se encuentran
en el excel.
En la columna, uno vale.
Este sería la, el nivel más
alto de la jerarquía.
Entonces, por el momento tenemos
la entidad acreditación
que está en este primer yo la días
proyecto contenido de la información
agente actividad financiación
gasto roll relación
y campos de investigación
si nos metemos,
acreditación, por ejemplo,
pues aquí véis,
que acreditación tiene una
transformación que se encarga
de cargar el objeto plano
acreditación de investigación.
Porque, bueno, porque la
odontología me dice
que hay distintos tipos
de acreditaciones,
entre las cuales se encuentra,
acreditación de investigación,
que es la segunda que el nivel dos
que tienen una relación directa
con una tabla de la Universidad
de Murcia
que es Diploma de Estudios Avanzados.
Es decir, después de analizar los
datos porque esta no es trivial,
no es inmediata.
Hay que entender que Diploma
de Estudios Avanzados,
se correspondería con acreditación
de investigación.
Vale, aquí está parte de esa tarea
de análisis que os comentaba antes.
Vale, si nos vamos a otra
entidad, por ejemplo,
contenido de la información
es un poquito más grande.
Bueno, es que tenemos la carga
de un guión que sería
publicaciones científicas y
otro que sería colección.
Si entramos dentro de publicaciones
científicas,
pues aquí nos vamos a encontrar otro.
Yo, que se encarga de cargar cada
una de las entidades que tendríamos
facturas patentes artículos libros
tesis doctorales y tesis
si entramos dentro de
la transformación,
que se encarga de cargar los datos
relacionados con libro,
pues aquí vais a ver tres flujos
de datos independientes,
uno se encarga de la entidad, libro,
otro se encarga de la entidad,
capítulo del libro y otro se
encarga de la entidad.
Sección del libro.
Vale?
Como todos ellos hacen foco
en la entidad, libro.
Bueno, pues nos hemos unificado
en la misma transformación
para simplificar al máximo
posible Bale y bueno,
pues con el resto sería un
poco lo mismo no agente
actividad financiación gasto vamos
a entrar en gasto por ejemplo
por ver algún otro ejemplo
dentro de de gasto,
pues tenemos gasto, proyecto
y gasto de potente.
Serán los dos únicos orígenes
de datos que tenemos
relativos a gastos.
Si llegamos a la odontología,
buscaremos la entidad gasto
estaría aquí euskera.
Antología, nos contempla estos
cuatro tipos de gastos.
Todo objeto de investigación,
gasto de personas,
gasto del proyecto, gasto de
patente coincide que estos
dos últimos los tenemos en nuestro,
en nuestros orígenes de datos bale.
La idea es que aquí además de
estas dos transformaciones
existan otras dos más que de
momento se quedarán vacías
y que se encarguen de gestionar un
flujo de datos para gasto objeto
de investigación y gasto de personal
vale por sí el día de mañana
en la universidad.
Estos datos existen,
sería enchufar a ese flujo de datos
en origen correspondiente
y adaptar los nombres de sus campus
a las propiedades que tengan bale
si quieres preguntarle algo más.
Una cosa así yo me he puesto
el principio,
si me imagino esto está relacionado
con lo que hemos visto al principio,
no sé si en esta sesión
o en la anterior esto ejecutaría
todo correcto correo
a las entidades relaciones
relaciones exacto exacto
todos nos traslada la todos los
todas las transformaciones del proyecto
llevamos que dependen de este,
sí se pueden lanzar o se lanzan
algún yo de manera independiente,
pero cualquiera de ellos
tú puedes ejecutar
cualquier yo o cualquier
transformación de forma
independiente.
Es decir, imagínate que tienes
y te interesa cargar todos
los objetos, planos,
pero los objetos relacionados
que están en este yo.
No te interesa, porque va
a llevar dos horas
todo el proceso de carga.
Bueno, pues entras dentro del hogar
y aquí puedes ejecutar todo esto.
Dice.
Es Bale este, yo tardé muchísimo, y
además no me interesa cargarlo.
Solamente me interesa
cargar proyecto.
Pues entonces yo proyecto y aquí
tendría sus proyectos
y proyectos internacionales,
pero además, como estoy todavía
consume mucho tiempo
y no te interesa, todo, solo te
interesa ver los proyectos,
puedes venir a la transformación
del proyecto
que tiene este flujo de datos
y ejecutarla por sí sola.
Además, coincide que no sólo
quieres ejecutarla,
sino que quieres hacer una
serie de cambios,
y esos cambios tienen un
proceso de depuración,
y durante ese tiempo, pues
le estaba dando errores.
Hasta que lo tengas todo pulido,
pues trabajarían.
Dentro de esta transformación.
Ejecutaría las veces que quisiera
salir tus pruebas, tus cambios,
y ya, cuando esté todo listo, puedes
ir hacia arriba hasta llegar
al poder ejecutar todo
el flujo de datos.
Vale, porque he visto el
resultado del Hoyo,
ha dicho.
Habéis dicho que acaba
acababa en una cola.
No sé si esto acabe existiendo en
alguna base de datos que sea.
El resultado de las transformaciones
resultado de la tele
se va una escuelas de Kafka, a
partir de la cual hay un proceso
que gestionaría el equipo
de desarrollo,
y de ahí se va al triples Touré,
claro que si lo ejecutó
yo de proyectos,
son todos los que tienen que acabar
en eso, en una en una transformación
y una cola blanca, que sería
lo que ha resaltado
de todas las transformaciones exacto.
De hecho, el último nodo
de las transformaciones que se pone
aquí es un modo que tiene tajo,
que se llama Kafka Bale.
Entonces, este no era el hostil.
Puerto de ese, esas colas, de Kafka,
el topic Bale, que es
donde se almacena,
y el campo, el campo de salida,
el campo de salida,
como ya tiene un formato
de mensaje Kafka,
se van cargarlo se encargaré yo
automáticamente de subir a
la cola correspondiente.
Digamos que desde esta parte de aquí
desde donde confluyen todos
los flujos en adelante,
hacer nada, eso sería
la idea más vale.
Sí que es verdad que
lo que hemos hecho
es una carga en una base
de datos intermedia.
Por qué?
A-como comentaba mi compañero, el
proceso que se encarga de lanzar
lte es una web determinada en
versión iguala y el número de la versión.
Entonces, esa esa versión, va a
tener, valga la redundancia,
una versión de los datos.
Pero qué pasa con las versiones
anteriores?
Sería muy interesante tener
un histórico de versiones
por si hubiera que si hubiera que
hacer alguna operación de recarga
o simplemente de comprobación
y demás.
Entonces apodo de histórico,
lo que estamos haciendo es almacenar
una base de datos.
Todas las versiones que se
van a ejecutar entonces,
a Kafka siempre va a ir
la última versión,
pero todas las presiones
que pasen por el flujo
van a ir con en esa base de datos.
Es algo interno, es algo
para el desarrollo,
no es algo que que tenga
una utilidad directa
con la salida de datos que le vale,
porque como nos comentaba
en la versión en curso,
la que se va a subir a Kafka, vale?
Esa sería un poquito la idea,
esa base de datos,
esta subida al repositorio también
va a ir creciendo
conforme vaya aumentando el
desarrollo de esa base de datos
haciendo cada vez más grande.
Pero bueno,
siempre procuraremos tener siempre
la última versión
para que las formas con el
proyecto que os voy
a dejar subido y la versión
de la base de datos
y hacer alguna prueba local,
no tenéis problemas.
Aunque el proyecto está parcialmente
creado o no,
para lo que vais a necesitar
que es bueno entenderlo,
un poquito sería suficiente.
Bale?
Pues bueno, por mi parte, en
principio ya terminado,
os dejo en el cuerpo a los
enlaces de interés,
vale la ciudad al repositorio,
a raíz del repositorio de
detener y luego bueno,
para que no perdáis tiempo
buscando en la carpeta
-proyecto tenéis el proyecto de
trabajo para descargarlos
y luego en una carpeta que se llama
dos Este Excel de la oncología,
también para que lo tengáis yo.
No sé si quieres preguntarle
algo más, no, perfecto.
Si tenéis cualquier duda, bueno,
ya sabéis dónde estamos.
Porque bueno, esto ya se sabe, no?
Las sesiones suele.
Suele quedar todo más o menos
clara la idea general,
pero en cuanto empezamos
a trastear con ello,
pues puede surgir alguna duda puntual
si entonces los que estamos
a vuestra disposición
para lo que me necesitáis vale
gracias gracias bueno creo
que la sesión de mi compañero
empieza a las 11.
Entonces, bueno, yo le voy a
comentar que ya ha terminado, pero bueno,
en principio, si no me dice nada,
tenéis 45 minutos de descanso.
Bale?
Sí vale muy bien.
Pues pues nada más,
muchísimas gracias por vuestro
tiempo y bueno,
espero que eso haya sido útil.
Gracias.
Entonces nos conectamos ahora ya ha
sancionado, porque yo creo que sí
porque mi compañero probablemente
tenga en mente
conectarse sobre esa hora para ver
si hacemos valer perfecto,
gracias a estarlo.