Idioma:
Español
Fecha:
Subida:
2021-02-26T00:00:00+01:00
Duración:
28m 45s
Lugar:
Curso
Visitas:
1.095 visitas
20210216 2-Introducción a Linked Open Data
Transcripción (generada automáticamente)
Bueno, continuamos, una vez se ha
visto un poco de los aspectos
generales de limpieza pelota.
En esta siguiente parte local saber
un poco su aplicación en Asia
y posteriormente lo lo lo que
va a suponer en el conjunto
de los proyectos Hércules ha sido
ese es el vacante semántico
de ese, pero también es el proyecto
en el que se ha definido
la red de antologías -Hércules,
que va a tener otros usos
en el ámbito de de los
proyectos Hércules,
particularmente en los proyectos,
en el proyecto.
Esto es esma, en cuanto a
requerimiento de datos
y métodos de análisis.
Entonces, los dos aspectos
que vamos a ver aquí
sería, por una parte Hércules,
ha sido incierto Open Data
y enlazado con datos externos
que se está haciendo, nació
y el que se propone y el que
se va a proponer hacer
en proyectos futuros.
Repasando un poco lo que era lo
que era el luego lo que es,
el proyecto del club
de ser culés está definido como
un proyecto de semántica,
de datos de investigación
de universidades.
El proyecto Hércules va a crear
un sistema de gestión
de investigación que circule
si se está basado en datos
abiertos para ofrecer
una visión global
de los datos de investigación del
sistema universitario español.
El objetivo es mejorar la gestión,
el análisis y las posibles sinergias
entre universidades
y el gran público.
Si sí digamos, si comparamos esto no
con lo que comentábamos en él
en la presentación anterior
son el tipo de objetivos
digamos que se cumplen con un
proyecto de datos abiertos
y datos enlazados, hércules
fue bueno,
como como comentábamos, un proyecto
de arquitectura semántica.
Los dos tienen sistemas de gestión
de investigación y universidades,
círculo, y se le exige, y
Hércules en principio
a la arquitectura.
También se podrían conectar sistemas
de gestión de otras universidades,
de otros tipos.
Digamos que los los dos pilares
no, que tiene ser
la parte de la arquitectura
semántica es así y el prototipo innovador,
sistema de gestión de
la investigación,
que es el sistema de lo que
aquí está representado
como sistema de gestión,
investigación y universidades.
Estos son los 2, las dos patas
principales del proyecto.
El proyecto Hércules hacemos
un repaso rápido,
tiene tres proyectos, por una parte
es así que estamos ahora que
esa arquitectura semántica
e infraestructura antológica la
parte de la infraestructura antológica
básicamente se trata de definir
el modelo antológico.
La red de antologías
-Hércules, la arquitectura,
se mantenga,
lo que define pues el conjunto,
agregamos el conjunto de herramientas
que permiten la carga y
almacenamiento de los datos.
En formato se mantiene y su
posterior publicación
interrogación la sgae y ese
sistema de gestión
de la investigación y encima
son dos en dos proyectos,
enriquecimiento de datos a partir
de internet y desarrollo
de métodos de análisis.
Saltamos, no, aquí es ese, ha sido
esa arquitectura semántica lógica,
datos a partir de internet vale,
son los tres aspectos, digamos,
que tenemos que hacer.
Tenemos que destacar en relación
con datos, en la zaga,
es decir, tenemos, es una
plataforma que cumple
los estándares de la web semántica.
Hay un desarrollo de tecnologías
Hércules
y además, enlaza y enriquece con
datos a partir de interna.
Ha sido, era el bueno, pero
digamos que tenía 2.
Estas 2, las dos patas de la
partida de arquitectura
se mantiene, correspondería
al desarrollo
de una plataforma eficiente
para almacenar gestión
y publicar los datos basándose
en la infraestructura
y con la capacidad de poder
sincronizar instancias instaladas
en diferentes universidades
y por otra parte
está la creación de una red
de antologías antológica
que pueda ser usada para describir.
Para disculpar.
Que pueda ser usada para describir
con fidelidad,
y los datos del dominio de gestión
de la investigación.
Ese es el prototipo innovador del
sistema de gestión, que incluye
todas las actividades de gestión
relacionadas con la investigación,
un requisito que tiene que estar
integrado con la actitud,
con la arquitectura,
se desarrollo y por último,
tenemos esma que el objetivo es
identificar, extraer y analizar,
analizar y evaluar conjuntos
de datos.
Son relevantes y se completa
con datos obtenidos
a partir de fuentes externas.
Datos, datos con los que puede
lanzar entonces el el.
Bueno, aquí hemos resaltado un
poco en rojo no carácter,
no del tema de publicar
datos en Asia.
Es importante esa parte
de publicaciones
en los crecimientos de los datos
enlazados en la parte
del esma la parte de información
de fuentes externas
y de las fuentes externas.
Si empezamos un poco
los tres proyectos en su
comunicación entre ellos,
no tenemos que ser enviado a,
ha sido consolidar datos en una
central unidad central,
datos homogéneos entre nodos,
explotar los datos del nodo central
y enriquece datos de fuentes
de internet,
y encima se conecta con esa ley
para la gestión de proyectos,
y esto es una presentación general
que ya vimos en su momento
cuando hablábamos del
proyecto Hércules,
cuando presentamos el
proyecto conjunto.
Esto es lo que decíamos,
pero podemos decir algo más, no, que
ha sido publicar datos abiertos
y enlazados, es decir, no solamente
consolida estos datos
sino que los pública son hace la
publicación de los datos abiertos
y enlazados y el nodo central no
solamente unifica los datos
sino que publica esos datos abiertos,
y no es que no es que se los
que digamos los consolida
y los para que nadie lo o lo que
hace es publicarlos hacia fuera.
Como queda.
Entonces, esto, bueno convierte
estos dos proyectos,
nos convierten en unos
proyectos de datos.
En la zaga se este símbolo,
bueno, Jorge para ti,
especialmente si lo ves por
ahí en webs y demás,
lo que significa en general
es que tiene un proyecto
que de alguna manera está
relacionado o exponer a los ojos.
Esto que comentábamos en la
presentación anterior,
datos abiertos, datos enlazados,
que data de.
El publicar datos abiertos
con rapidez
es un factor de innovación esto
ya lo comentamos, pero bueno,
es así; es decir, es más fácil,
como hemos visto antes, publicar
datos con una estrella
y publicar datos con 5,
pero es mucho más incómodo
reutilizar los datos de una estrella que lo sé.
Entonces, la rapidez es un
factor de innovación,
la gente puede reutilizar esa
información con rapidez,
pero si su uso no es cómodo
con la innovación,
entonces digamos si pensamos
en la abstención, modelo,
relación entre los datos,
en la zaga de los datos,
actualización y difusión,
tenemos dudas o problemas.
Con ellos, saben cómo se
obtienen estos datos
no se con un con una descarga
es con una pie, el modelo,
como es cerrado, abierto, público
o privado, propietario,
la relación no se pueden relacionar
los datos que están disponibles,
es decir, yo puedo ir a una
tabla, otra tabla,
otra tabla de manera aislada,
o puedo hacer consultas directamente
sobre los datos.
De alguna manera, los datos están
lanzados o no los datos,
se actualizan.
Quién es el responsable
de la actualización,
es el utilizado, o es el propietario,
es decir, tiene que procurarse
los datos más nuevos
o responsabilidad del propietario.
Yo sé dónde están y siempre
están actualizados,
se accede con una descarga
se hace con una pie
y luego, en cuanto a difusión.
Si hay, os hablamos de que
son enlaces expansivos,
entonces ha sido, ofrece una app.
Para obtener estos datos, el modelo
que ofrece es abierto,
es público, es estándar,
y es expresivo,
y extensible permite acceso a
consultas para almacenar datos.
Es decir, no solamente dejo acceso a
una, tendría acceso a una tabla,
sino que tuviera acceso al conjunto
de tablas, digamos,
el conjunto de entidades y sus
relaciones, en este caso,
caso para que la consulta o las
consultas que quieras.
Los datos están lanzados
con fuentes externas,
se pueden enlazar la actualización
es mediante una pie.
La responsabilidad es del
propietario de que estén actualizados
y, bueno, en principio,
los los los datos se difunden
vía vía web.
Es una discusión activa.
Pues bueno, el mejor medio
para publicar datos
abiertos es el medio ideal.
Hay otro asunto
que la a la que también tiene
relación con los datos abiertos,
que es el seguimiento de los
principios mínimos.
Son unos principios de publicación
de datos que se basan
en que los datos sin ser
encontrado tienen
que ser accesibles interoperable sí
reutilizables esto además bueno
esto es un juego de palabras porque
eso también significa bueno
de alguna manera entonces bueno son
ser es serían datos buenos pero bueno
son datos que cumplen estas
estos cuatro principios,
digamos, qué hacen estos principios,
después nos nos dan unas guías para
publicar recursos digitales
como conjuntos, de datos, códigos,
flujos de trabajo,
objetos de investigación, de forma
que sean localizables accesibles,
interoperable, sí reutilizables.
Estos principios se refieren
no solamente a los datos
para cualquier objeto digital,
sino a sus metadatos
y a la infraestructura.
Digamos que todo eso tiene que
proporcionar un acceso
a los datos, datos, datos clave.
Cómo vamos a ver?
Limpieza Open Data, también es el
mejor medio para ser sacerdote?
Bueno, creo que ya lo vimos
anteriormente.
Le queda táser ver en él
es el componente de.
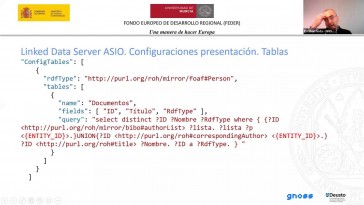
Entrando ya nació el componente
que, que permite en Asia
la arquitectura semántica del
componente que permite
la publicación de los datos que
están en el error de gestor
están cargados de gestor con datos
abiertos y enlazados.
El servicio tiene las siguientes
características.
Proporcionar una interfaz
htc con estilos
y formatos personalizables.
En nuestro caso
nosotros hemos incluido además una
presentación con tablas y brazos
para enriquecer un poco
en la presentación
de ciertas entidades la presentación
de los datos de otras entidades.
Proporcionar los datos informa Efe
para permitir la reutilización;
cumple las recomendaciones y cuenta
con un servicio que permite
localizar entidades por el nombre,
las presentaciones buenas parecidas,
esta enzima presentación
un poco.
Digamos que una parte estándar
de decir que dato
de que dato estamos,
a sea cuál es el dato que
estamos presentando
y qué valor tiene.
El valor de ese dato puede
ser otra entidad
o directamente una cadena de texto.
Es por ejemplo, que el nombre es
Antonio Fernando Skármeta
Gómez y luego, bueno,
pues hay una buena presentación
de datos,
como las publicaciones
en formato tabla,
o la relación entre los
entre los autores
con los que comparte,
con los que comparte publicaciones
este investigador concreto.
Esto lo lo veremos en con más
detalle en la hora siguiente.
La otra parte que permite acceder
a los datos en la arquitectura.
Que permite a los administradores
consultar los datos del conocimiento
que están en ese sector
mediante el lenguaje
Parker esto vimos ayer a quién
correspondía un repaso rápido,
es el protocolo de consulta de
interrogación para la FCC,
y así pues, bueno, va a tener
un puente sobre lectura
para los héroes públicos que no va a
tener acceso a los datos privados.
Esto es importante, es el texto,
permite un parque que le permite
el acceso a los datos,
que están directamente en el
resto y en otros, Rhodes.
Estos,
mediante otro tipo de consultas
federadas.
Como comentaba, Jorge al principio,
no para cuando, cuando te enfrentas
a la reutilización de los datos,
hay una primera parte que es
importante que conocer
el modelo semántico de los datos
en el caso de asilo,
en particular de Hércules.
Este modelo romántico tiene
una cierta complejidad
para reutilizar falta, conocerlo,
el modelo y ejecutar consultas.
Es y reutilizar.
El texto es el componente
de la arquitectura
que almacena desgracia conocimiento
dentro de ha sido.
Además, es un servidor de datos,
que responde a consultas.
Es porque a veces eso es
nombrado como seguidor
de los servidores de receptores el
que proporciona servicio de datos
y consultas al servicio
de los parques.
Ayer vimos eso, que en el desarrollo
de para cada universidad,
cuál sea la solución que más le
convenga y, como decíamos ayer,
uno de los requisitos obligatorios
es que debe cumplir el estándar.
Es parcial, uno punto en particular,
lo que se refiere a actualizaciones
de datos.
Esto pues eso es importante.
Esta proporciona servicio
de datos y consultas;
ha liquidado, tras ser vendida,
los parques.
Aquí hay una parte importante que
tiene que ver con la ingrata,
que es la que tiene que ver con él
con él esa limpieza del dos
de los datos que comentábamos antes.
No hay unos procesos que tienen que
se llama genéricamente procesos
de descubrimiento en el
proyecto Hércules,
así que tiene tres procesos,
no la reconciliación,
descubrimiento de enlaces y
detección de equivalencias.
Los tres procesos actúan
conjuntamente
en el gran proceso de descubrimiento
en la reconciliación.
Lo que se hace es evitar la
duplicación de entidades
mediante un conjunto de reglas.
Esto es lo que comentábamos antes,
no identificar a un un autor
que llega con la denominación,
saber si es uno que ya está cargado
o no para que no esté duplicado
la reconciliación es toma de
decisiones de tipo autónomos,
y si las reglas digamos,
ya superan un cierto umbral
de confianza,
y si queda en un rango de duda,
digamos, la validación del usuario.
El proceso de reconciliación
utiliza datos obtenidos
en el descubrimiento del acceso
a datos externos
adquirido y etc
desde el nodo, unidad, el
descubrimiento de enlaces,
lo que hace es obtener
identificadores de fuentes externas.
Se enriquece de alguna
manera con datos,
enriquece con la, proporciona
información
para el otro proceso
de reconciliación,
y además tiene un proceso
con ejecución continua,
para que cada cierto tiempo,
ir a buscar
a los repositorios en cuestión por
si hubiera algún dato nuevo,
un nuevo enlace o alguna
nueva información,
y, por último, estaría el
asunto de la detección
de equivalencias que obtienen las
entidades de otros nuevos.
Entonces, esto es el digamos
que enlaza con otros más, ha sido
el más que hemos visto antes,
pues una publicación es la
misma que la publicación
en esta otra universidad
o que este autor
es el mismo que hay en
esta universidad.
Entrando ya en Asia,
lo que hacemos con el enlazado
de datos externos
digamos que ha sido, obtiene enlaces
a fuentes externas,
por ejemplo, la página del
investigador Ortiz,
pero digamos que que lo quería esto,
digamos, si nos quedáramos
limitados a esto,
es que estaríamos enlazando
una web a otra,
una página la página del
investigador nación, la estaremos en la zona
con una página web, en otro sitio,
pero en realidad se pueden.
La farsa no es solamente un enlace,
un vínculo entre páginas web,
sino que también lo estamos
con el dato.
Es decir, esta petición, por ejemplo,
lo que hace es devolver el el
formato de este investigador,
mientras que aquí vamos a la página.
Con esto lo que hacemos
es obtener datos.
Es decir, lanzamos el dato
en Acción con el dato.
Como comentábamos,
el proceso de descubrimiento incluye
el enlazado de datos por tanto
con otras universidades poniendo un
ejemplo no en este investigador
un investigador
que tuviera este código que tuviera
en la Universidad de Murcia.
Gran punto es.
Podemos declarar, que es el mismo
que unidad se llama así
y a su vez, podríamos tener un
seis más que indicase que es
este investigador.
Es decir, podríamos llegar saltando
de datos o mediante datos lanzado
a la información que de
este investigador.
Tenga obtuviera el espacio de datos
abierto de la Universidad de Deusto
de datos abiertos y enlazados.
Podríamos pedir toda su
información viviendo.
Pero lo único que tendríamos,
lo único que puedo
que nos haría falta en realidad
tener enlazado en el único triple
que nos haría falta tener en
la Universidad de Murcia
para poder llegar hasta aquí
sería este primero.
El resto de la información
que mostraremos
se obtendrían mediante
mediante esos autos.
En cuanto a la zaga de
datos que hacemos
en la fase de descubrimiento, nos
ese es un proyecto bueno,
que la aparte de recoger la
actividad investigadora de los investigadores
ofrece un identificador único.
Tenemos este ejemplo?
Pues bueno, esto es lo que digamos
que lo que sería la página web
y esto serían los los datos que
están en un formato como este
en el caso de que se pidiera
que se diría pues eso,
que el autor,
en este caso sí lo es por aquí
que es Diego López.
También hacemos las de BP.
Es un espacio de datos
de investigación
relacionados con tres años.
Es muy específico, por
tanto, pero bueno,
es que si este las digamos
al alegre investigador,
pues no se vuelve una cosa parecida
a la que hemos visto antes,
entre ellos.
Bueno, por cierto, el propio código
que está aquí también
es un dato que se podría recuperar.
A lanzamos, también con
él, con unos costes,
es decir, las categorías,
los los de las entidades,
van a venir categorizado con
el tesoro de la Unesco,
y lo que vamos a hacer es el con un,
que es la implementación en
del tesoro de la Unesco,
que se aprovechaba la Universidad
de Murcia.
Entonces, por ejemplo, si algo viene
con una categoría 8, 3, 3,
esta categoría está apuntando a un
un apuntaría a este rdc tenemos
pues bueno las la el texto que
es la creatividad tenemos
cuál es el enlace a la categoría
padre con broker
y tenemos otras categorías
relacionadas.
Las patentes las vamos a enlazar con
el con los datos de la europea.
Ese es un proyecto de ley que
data que está muy bien.
Si os fijáis, el espacio o la
representación para humanos
llevamos es bastante parecida
a la que hemos implementado
nosotros, parecida a la que tiene
esto es un poco estándar
del que data de un servidor queda
tanto es tenemos la la página digamos
de una patente para una persona
y si pudiéramos, los datos,
lo que tenemos es eso, es
esa misma información
para poder ser reutilizadas.
Decir.
Nosotros lo único que necesitaríamos
guardar.
Como triples que una determinada
patente del es la misma,
es la misma que este enlace
o bueno habría que ver
cómo se declara.
Pero bueno,
el caso es que se podría
enlazar con este,
con este espacio, con esta, con este
y a partir de aquí obtener
toda la información de la patente
sin necesidad de tener más otro dato
almacenado distinto con el IBI.
Bastaría.
Entonces, en cuanto a, en cuanto
al enriquecimiento,
la extinción de los tres proyectos
que teníamos,
lo que decíamos era que ahí
hay una parte de aquí
sería el enriquecimiento de los
datos que corresponde al proyecto
Esma, que es el completar los datos
a partir de información de fuentes
hasta entonces, cuál es el futuro?
No los los próximos pasos
que esta arquitectura nos
va a permitir dar.
No es enriquecer datos o
lanzarlos con la wiki,
data de cualquiera, es bueno,
ya hemos visto,
son espacios de datos en la casa dos
de carácter enciclopédico y general
y por tanto como en principio
cualquier entidad.
Bueno, bueno, cualquier entidad en
casi cualquier ámbito va a poder
ser lanzada con un concepto.
Aquí sí que es cierto que conceptos
muy específicos
de ámbitos médicos especialmente
igual,
no están en que no están
en Wikipedia.
Por tanto, no van a estar en huída,
tampoco para esos casos.
Habrá otros espacios con los
que las armas concretos.
Pero bueno, no, no, es un
que a veces discusión,
no sobre la calidad de la
información que contiene tanto
como wiki data, que es la misma
discusión que en realidad
se tiene sobre Wikipedia, como
fuente de información fiable;
entonces, es cierto que,
bueno, pues tal vez
no sea una fuente de información
fiable al 100 por 100,
pero sí que es cierto que permite
un reconocimiento de entidades
y nadie es ambiguo;
acción que no hay que
despreciar y luego
ese reconocimiento de entidades
te permite relacionar.
Te permite relacionar entidades como
con más precisión es un sí
si bien podría ser discutible,
digamos la definición que haya
de despedida de una cierta entidad
en el ámbito médico,
lo que lo que no es discutible es
que si la entidad ha reconocido
de manera ambigua, eso
ya es un valor.
Además, haremos el enriquecimiento
con términos
como mes, que son términos que están
en el ámbito de la medicina
de la investigación médica.
Hay una en el caso de completarse
-años, con términos de antologías,
deseo en el caso de autores,
publicaciones y temas españoles
hay una fuente importante que es la
datos de esto además bueno Oscar
creo que estará implicado
en este proyecto,
porque tiene relación con el
grupo en el que trabaja.
Bueno, hay una puede ser
interesante, el azar,
con autores, publicaciones y temas
de la Biblioteca Nacional.
Además, tenemos que ofrecer,
tiene una información
particularmente interesante en temas que ya no son,
que no corresponde a la
investigación en ámbitos tecnológicos,
sino que son más, pues en temas que
pueden ser sociales de Derecho,
historia, etc. La que bueno, pues
pues otros otros medios igual
pueden tener alguna carencia,
hay algún otro sitio,
como Meteora, que es Diccionario
médico de terminología
médica, es Noves, se tiene que
determinar qué integral
tenemos puntos suspensivos,
porque, bueno, ahora mismo esto es
una cosa que está ahora mismo
un estudio y una de las no de los.
Una de las tareas que tienen estos
proyectos ahora mismo
es el identificar fuentes
en las tablas adecuadas
para cada área de conocimiento de
las publicaciones científicas.
Es decir, sí cual es adecuada.
Para la publicación, publicaciones
sobre sociología o política,
lo cual es asociado así en
las investigaciones
sobre derecho etc
En principio los ámbitos científicos
tecnológicos
en esto están más desarrollados
pero bueno,
hay que tratar de ofrecer la
funcionalidad de enlazado
de datos para investigaciones
en cualquier ámbito,
resultados de investigación,
incluso en el artístico.
Con esto acabaríamos la presentación
de esta de esta primera parte
de datos enlazados.
No sé si.
Jorge, tienes alguna pregunta Oscar?
Alguna observación.
No solo esta parte, no, por mi parte,
pues si queréis, hacemos una
posibilidad prevista,
creo que una pausa de media
hora si queréis la,
podamos hacer un poquito más
corta, un cuarto de hora,
o así y Podemos a las 11 10,
o así da?
Igual.
Vale?
Voy a para la grabación.
Propietarios
Proyecto Hércules
Comentarios
Nuevo comentario
Serie: Formación ASIO martes 16 febrero GNOSS (+información)
Descripción
Formación ASIO martes 16 febrero GNOSS